blog
AIブログ
感情認識とは?開発の経緯やAIの仕組み、活用事例を紹介します

感情認識とは、AIが人間の表情を読み取り、その膨大なデータと照らし合わせることで今どの感情を示しているのかを識別する技術のことです。
正確には、人間の感情を認識しているのではなく、“その表情がどんな感情を示しているの”という客観的な判断になります。
AIの技術によって、人間の複雑な表情の違いや発する声を分析して感情を判断することができるのですが、「それって一体何がすごいの?」「わざわざAIを使わなくてもいいんじゃないの?」と感じる方もいらっしゃるでしょう。
この記事では、
・感情認識とは?
・感情認識ができるようになった経緯
・感情認識の種類
・感情認識によってどういったことが可能になったのか
・弊社のとりくみ
これらを中心に解説していきます。
弊社はAIの受託開発業務を専門におこなっておりますので、専門家の視点も交えながら極力わかりやすく解説していきますので、感情認識やAI、最新の技術に興味がある方の参考になれば幸いです。
感情認識とは?

感情認識とは、その字の通り、人間の表情の動き、声質や文章などから感情を読み取り、認識することを指します。
心理学という言葉があるように、人間は些細な外部からの刺激にも敏感に反応し、それが態度や表情となって表れます。
従来では人間の複雑な心境や細かな感情は、コンピュータでは分析することはできないとされていました。
しかし、技術が進歩し、機械学習が発達したことで、「人間の表情筋の動きや目線の動き」などを細かくデータ化し、過去の膨大なデータと照らし合わせることで、「この表情は怒っている」「この表情は悲しんでいる」と識別できるようになりました。
さらに改良を重ねることで、「声による音」「文章による感情の識別」など、多方面からの分析が可能になりました。
「甲高い音で激しく怒鳴り、険しい表情をしている=怒りの感情」といった複合的な判断をすることで、より高度な感情認識が可能になったのです。
当然のことながら、複数のことを同時に、かつ総合的に判断するには高度な技術が必要になりますが、将来的には、脈拍の動きや瞳孔の動きなども読み取り、より精密な感情認識が可能になると期待されています。
感情認識ができるようになった経緯
一般の方が気になるのが、「感情認識は必要なのか?」という点だと思います。
人とコミュニケーションを取るために、人間の感情がわからないAIを使う必要があるのかと疑問に感じる方もいらっしゃるかと思います。
しかし、技術の進化によりAIは人間に確実に近づいており、五感で認識する人間以上の精度を誇り、コミュニケーション以外の場所でも活躍しています。
詳細を解説する前に、まずは感情認識の開発の経緯を簡単にご説明します。
◆機械学習の登場

AIを語るうえで外せないのが「機械学習」の登場です。
この技術により、AIがAI自身で思考し学習することで急成長を遂げました。
人間が与えた課題に対し最適解を探し、仮に失敗したとしてもその過程を学習して次回に活かすことで、より難問を解けるように成長していったのです。
詳しくはこちらでも解説しています。
これをきっかけにAIの研究が盛んになり、様々な技術が開発されてきました。
そして次の課題として「AIをどこまで人間に近づけることができるのか」というところに注目が集まっています。
アニメの世界やSF映画では、ロボットが感情を持ち、自律して人間と共存する世界が描かれたりしていますが、「そんなものは空想の世界だ」と思う方も多いでしょう。
言われたことを忠実に再現するお手伝いロボットのような“意思のないロボット”はイメージできても、自身で思考し表情豊かに表現する“意思のあるロボット”はまだまだ現実的ではないと考える方が大半だと思います。
しかし、人間の声を認識して反応するペットロボットやGoogleの音声認識サービスのように、技術は確実に進歩しています。
特定の言葉に反応して、指定された行動をするという段階まで来ており、次は自身で思考し自律するロボットの研究開発がなされています。
AIで人間の感情は読み取れるのか
感情認識をする際に、AIは人間の感情を読み取れるのかが課題になっています。
結論としては、「感情を読み取っているのではなく、特定の行動などから過去のデータと照らし合わせて近いものを判断している」ということになります。
技術面でいえば、すでにAIは画像の区別がつくまでに技術が進歩しています。
正しい画像と誤っている画像を学習させれば、あとは自動で判別し正しいものと誤っているものに振り分けられるといった具合です。
縦と横だけの平面世界、画像などのいわゆる2Dでは驚異の性能を誇り、人間の肉眼で見えないものまでも正確に判別できます。
詳しくはこちらでも解説しています。
次の技術の進歩として、縦×横×奥行きという3D(3次元)を認識できるようになりました。
これにより、機械のような複雑なものや、布のような決まった形を持たないものも認識できるようになり、実際に工場の検品や異常検知などに導入されています。
このような技術向上やカメラも高精度になり、人間の表情を細かく読み取れるようになりました。
上記をまとめると、直接感情を認識しているのではなく、怒っているときの顔のパーツのパターン(眉が吊り上がっている、口をつむんでいるなど)などを識別し、総合的に判断しているということになります。
この技術によって人間のように主観や個人差に惑わされないといったメリットがあります。
紹介したような技術と強化学習を組み合わせることで、AIをどんどん学習させ、自律した人間に近いロボットを作るという壮大なプロジェクトが進行しているのです。
感情認識の種類について解説します

感情認識の技術の経緯について簡単に解説したところで、次はどのような感情認識の種類があるのかを解説していきます。
大きく分けて
・音からの感情認識
・顔の表情からの感情認識
・発話内容からの感情認識
・マルチモーダル感情認識
からなる4つの感情認識があるのですが、まずは予備知識として「快・不快」について簡単に解説します。
快・不快とは
「快・不快」という感情は人間の根本的感情の1つとされています。
「快」……つまり気持ち良い状態のことで、生物は本能的に快を得られる行動を取るようになっています。
また、不快から避ける行動も「快を求めている状態」とも捉えることができます。
それは食欲であったり、物欲であったりと様々ですが、人間も快を得たいという欲求が、行動に影響を与えていることは確かです。
反対に「不快」とは、気持ち良くないことや危険なことから回避したいという状態になります。
生存欲求にも大きく関わる感情のことで、空腹状態や不眠状態も不快にあたり、この状態が長く続くとストレスや健康にも影響が出てくる、非常に重要な感情といえます。
人間の感情は様々な要素が絡みあい、非常に複雑なものですが、AIの感情認識は大きく分けて「快・不快」のどちらに該当するのかが基準となり、そこから細かい感情に分類していくというわけです。
こういった人間の根本的感情を土台として、AIに新たな感情を学習させていくのです。
次項では4つの感情認識についてそれぞれ解説していきます。
音からの感情認識
AIは音による感情認識が可能になっていますが、音とはつまり「人間が発する声」です。
声の大きさ、高さ、抑揚などから判断していきます。
音声によって相手の感情がわかると、相手が怒っているのか、悲しんでいるのかがわかり、適切な対応を取ることが可能となりますので、コールセンターなどでの活躍が期待できます。
特にこの「声の感情認識」で注目すべき点は言語に左右されないという点です。
単語1つ1つではなく、その話し方や声量、息遣いなどによって総合的に判断されるので、「何を話しているかはわからないが、怒っているということは理解できる」状態になるのです。
さらに自分自身の声も感情認識が可能になりますので、自身の発する声から知らぬうちにストレスを抱えていたり、体調不良に陥っているといった気付きが得られます。
この技術を用いて、対話ロボットは相手が今どんな感情なのかを瞬時に判断し、適切な回答を選び出しています。
このまま技術が発展すれば、より相手との自然なコミュニケーションのサポートや、翻訳の技術で他国言語を話す人とコミュニケーションを円滑に進めることも可能となるでしょう。
顔の表情からの感情認識
顔の表情から感情を認識することは、実は人間は無意識におこなっていることです。
石器時代から集団生活を営んできた人間にとってコミュニケーションは必須であり、言語を持たなかった人間は表情で相手の感情を察していたのです。
言葉が発達した今でも、相手の表情から得られる情報は多く、「目は口程に物を言う」ということわざがあることからもその大切さがうかがえます。
AIの感情認識の場合は、表情筋と呼ばれる顔にある無数の筋肉の動き1つ1つをカメラで捉え、その各筋肉の動きや角度などの微妙な動きから、どの感情に分類されるのかを当てはめていきます。
アメリカの企業などは1,000万人以上にも及ぶ表情のデータを有しており、顔の形や国籍も関係なく高精度で判別することが可能となっています。
表情から感情が識別が可能になったことで、コミュニケーションの場面以外にも活用ができるようになっています。
食品会社では、試食品を食べてもらったお客様の表情を分析することで、お世辞ではない本当の反応を見ることができますし、パッケージデザイン会社では、その見た目が売り上げに大きく影響するために、なるべく快の反応が大きいデザインを採用するということがあります。
今後はVRゲームやテレワークなどでカメラ越しに会話する機会が増えると予想されるため、表情からの感情認識の活躍の場は増えていくことでしょう。
発話内容からの感情認識
「音からの感情認識」で解説したように、従来の感情認識では「怒ってはいるけれども何を言っているかはわからない状態」でした。
しかし、テキストマイニングの技術により、その言葉の持つ意味を理解し、より高精度な感情認識をする研究が進められています。
※テキストマイニングに関してはこちらで詳しく解説しています。
テキストマイニングによってその言葉や漢字が持つ意味を学習することで、その言葉を発した相手の感情を総合的に判断できるようになるのです。
私たちの声を「音」でしか理解できなかったAIが、言葉として内容を理解したうえで感情認識をおこなえば、より正確な感情認識がおこなえるでしょう。
マルチモーダル感情認識
マルチモーダルとは、Multi(複数)とModal(様式)を組み合わせたコンピュータ用語です。
対義語としてシングルモーダルがあり、従来のコンピュータは1つの基準だけで物事を判別していました。
しかし、深層学習の技術が確立されたことで、複数の情報を与えて総合的に判別することが可能となりました。
これを上記の感情認識に当てはめると、相手の「発する声、表情、発話内容」から見て総合的に判断することができるようになったということです。
人間はこれらを当たり前にこなしていますが、実際はかなり複雑なプロセスを踏んでおり、AIでの再現の難しさとがよくわかるかと思います。
ですが、徐々にAIも技術も進化しており、いよいよ現実味を帯びてきたことがうかがえます。
対話エンジンへの応用例
対話エンジンとは、こちらの話した内容を理解し、その内容に対して最も適切な回答をすることができるエンジン(プログラム)のことを指します。
これまではチャットボットのように、あらかじめこちらの質問内容が決まっており、その質問に対して回答するものが一般的でした。
テキストマイニングの技術が発達したことで、入力された言葉や文字を理解し、その内容に対して回答する技術が開発されてきましたが、その発展型として「対話エンジン」が開発されました。
代表的なものに、SiriやAmazon Echo、Google Homeなどがあります。
こちらの発した言葉を理解して適切な回答をするだけでなく、雑談などにも対応できるようになったのは、膨大な機械学習の成果だといえます。
今は家電製品などにも人間の声で音声操作できるものも増えており、今後は対話エンジンもより高度なものになっていくでしょう。
さらに研究が進めば、人間と同様のコミュニケーションができるロボットが開発される日も近いかもしれません。
感情認識によってどういったことが可能になったのか?

ここからは皆様が気になっている「感情認識によってどういったことが可能になったのか?」について解説していきたいと思います。
“相手の感情を読み取るだけ”と思ってしまうかもしれませんが、コミュニケーションを円滑に進めるうえで重要な役割を果たしていたり、意外な製品に使われていたりといった新たな発見があるかもしれません。
店舗での顧客満足度の向上
最もイメージしやすいのが、店舗での顧客満足度の向上です。
来店されたお客様の表情をカメラで捉え、接客やサービスに対してどのような感情を持っているのかを識別します。
言葉では賛同していても表情では不信感を持っていたり、口元は笑っていても目は笑っていない、いわゆる愛想笑いをAIは正確に判別することができます。
そういった深層心理化で現れる微妙な表情の違いは人間では見抜くことは難しいですが、感情認識AIを導入したことにより、反省と改善がおこなえます。
そういった分析はお客様へのサービスや品質の向上につながります。
また、接客だけでなく、店舗内の気温や湿度、BGMといった環境も分析することができ、総合的な顧客満足度の向上が期待できます。
お客様側だけでなく、導入する企業側にもメリットがあります。
接客時のスタッフの表情を認識することで、無意識に感じているストレスや疲れを早期に発見することができます。
ミスを未然に防いだり、労働環境の改善にも一役買っています。
客観的にデータ化することができれば接客技術の向上も期待でき、成約率や業績アップにも繋がるでしょう。
商品リサーチ
前述したように、感情認識は新商品の開発や顧客へのリサーチにも応用することができます。
広告やパッケージ、商品のPOPなど、様々な方法で購買意欲を刺激し、購入してもらうのが目的ですが、実物を見せたときの表情の変化や反応を分析することで、「売れやすい商品」の傾向を読むことが可能になります。
見た目、色味、大きさ、臭い、音など、人間は五感で様々な刺激を受けており、無意識下で反応しています。
そういった人間には判別できない微妙な違いも感情認識で拾うことができれば、無意識に気になり手に取ってしまうような商品も開発されることでしょう。
顧客対応ロボット
今後の活躍が期待されているのが、受付やコールセンターなどの対応ロボットです。
これまでは実際にスタッフが電話機の前に常駐したり、チャットボットによる機械的な対応が主流でした。
しかし、音声認識の技術により、電話口での声だけで相手の感情がある程度分析でき、相手の感情に合わせて最適な回答をすることができます。
さらに、ディープフェイクの技術により、実物の人間に限りなく近い容姿のAIをモニターに映すことも可能になっているため、相手の発言内容に合わせて表情を変えたり、こちらも表情豊かに応じることができます。
会社の受付窓口がAIに変わったり、コールセンターという業務がAIに置き換わる未来が近いうちに来るかもしれません。
自動車のアシスタントロボット
音声アシスタントロボットと聞いて、真っ先に思い浮かぶのはカーナビゲーションシステムでしょう。
目的地を指定すれば、そこまでの最短距離や料金を計算し、音声で案内してくれます馴染みのある製品です。
これもAIを使った製品なのですが、近年はカメラやセンサーを導入し、運転手の表情から疲れや眠気などを察知し、休憩を促すことで交通事故を未然に防ぐといった技術が開発されています。
また、危険運転やスピード違反、わき見運転といった運転手の感情や挙動によって発生する事故なども、運転手の視線のブレや怒りの感情を事前に察知することで防止することができます。
医療診断
感情認識は医療現場でも活躍が期待されています。
医師の問診以外にも、患者の表情や挙動から健康状態や感情を判断することができますし、入院中の患者の異常などを早急に察知できるといった使い方も可能です。
介護が必要な方へのサポートだったり会話相手、モニターを介することで遠方の家族の顔を見ることができたりと、従来のロボットアームだけの無機質な介護ロボットから、様々な機能を備えた人型ロボットへと変わりつつあります。
弊社での取り組み

弊社はAIの受託研究開発業務をおこなっており、様々な成果をあげています。
特に人間のサポートをすることができるAIの研究を主軸とし、実際の企業様にも採用していただいたり、AIの導入を希望される方のサポートをおこなっております。
深層学習により、年々グレードアップしていくAIですが、それに比例して作業効率や生産性も向上していきます。
感情認識を用いた弊社での取り組みの一部をご紹介させていただきます。
対話型AI HALさん
対話型AIのHALさんは弊社の技術を結集させて誕生したAIです。
HALさんは様々な深層学習により、多くの機能を備えています。
もちろん上記の感情認識も備えており、カメラに顔を映すことで本人と照合する勤怠管理機能や、表情や声からスタッフの体調管理も可能となっています。
質問された内容を理解してただちに検索する機能や、翻訳機能、文章を認識して読み上げる機能、議事録作成機能など、他にも紹介しきれない機能を有しています。
性能はもちろんのこと、ビジュアルにもこだわっています。
かわいらしい容姿をして見ている方を和ませつつ、会話内容や相手の発言に対して表情豊かに反応し、しっかりと感情を乗せた声を発します。
詳しくは下記リンクにて実際の動画をご覧ください。
企業の受付AIだけでなく、
・医療現場で患者様の診察や対応
・介護現場での見守りや話し相手
・商品開発のマーケティング業務
など、多くの可能性を秘めております。
すでに弊社では、2DのAI・深層学習において高い水準を誇っており、実際の企業様にも導入されております。
それに加えて、音の深層学習、3Dの深層学習の研究開発を並行して進めておりますので、近い将来にはより高度なAIが開発できると自負しております。
『ロボットを人間に近づける』という一見無謀にもみえる大きな課題のもと、弊社は日夜研究を続けています。
もはや使命にも似た大きなテーマですが、毎日わずかではありますが着実に前進しており、人間とロボットが助け合い共存する世界も夢ではないと考えております。
私たちの研究開発が私たちの生活を豊かにし、わずかでも日本に、世界に影響を与えるような、そんな願いを胸に日々研究開発に励んでおります。
感情認識に関する研究報告

CNNなどを用いて音声データから感情を識別する研究を行っています。
東北大学 伊藤・能勢研究室 能勢先生・千葉先生と研究しています。
◆第五回 現在の研究方針
現在までの音声のみの学習ではなく、テキストも利用した画期的な方法で学習を行う。査読付き研究論文化予定である。
これまでの研究経緯・結果
第四回 CNNによる音声特徴量を用いた感情識別
前回からの変更点
- 音声の特徴量を取り出す前に無音区間をjuliusによる強制アライメントを利用して無音区間の切り抜いた。
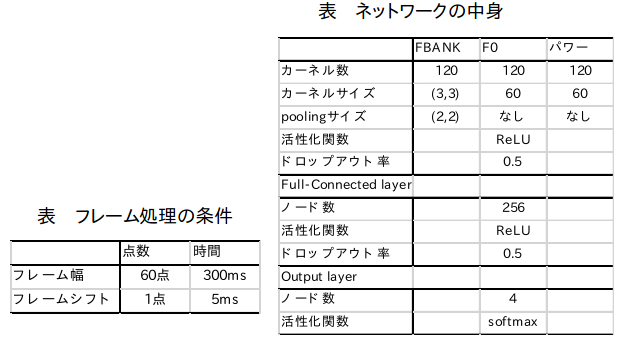
- 音声の特徴量として音声のスペクトル、基本周波数、パワーに関するもの( F0(基本周波数)、パワー、FBANK特徴量)を用いた。※FBANK特徴量はMFCC同様、音声の音韻的な特徴をよく表現できることが知られている。
手法
step1 JTESを学習セット・開発セット・テストセットに分割
step2 JTESのサンプルの無音区間を取り除く
step3 特徴量の抽出
音声スペクトル、パワー、基本周波数(F0)に関わるものをWORLDを用いて抽出する
step4 音声特徴量系列からフレームを切り出す ※FBANKは二次元画像、F0とパワーは一次元系列
step5 CNNに特徴量をフレームごとに入れて学習する

結果と考察
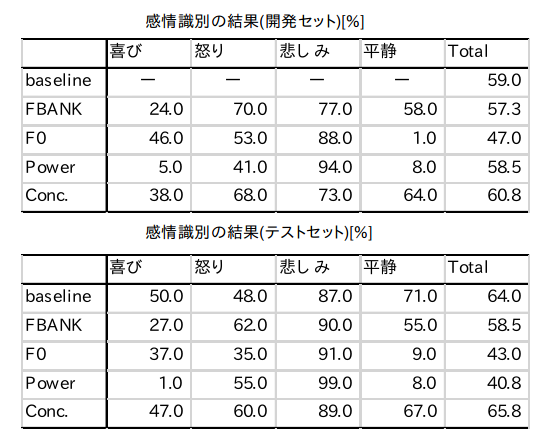
※開発セットに対する識別結果とテストセットに対する識別結果を下図に示した。表中のFBANK、F0、Powerはそれぞれの特徴量を単独で使用した結果である。Concは3つすべての特徴量を結合した結果を示す。またbaselineはopenSMILEで抽出した特徴量を隠れ層3層のNeural Networkで学習したものであり、第三回の結果である。

考察
今回の結果を特徴量別にみるとFBANK特徴量による識別性能が高く、スペクトラムが感情識別において有用性があることを示唆している。しかし、従来感情識別で有用とされる声高やパワーが今回の結果で高い性能を得られなかった。今回のネットワークでは声高・パワーの変動をうまく捉えていないことが原因だと考えられる。
また、各感情の識別率が特徴量ごとに異なる傾向があることが分かった。全体的に「悲しみ」の正答率が非常に高く、すべての感情に対して性能のいい単独の特徴量はなかったが、単独の特徴量の識別が相補的になっているものがあり、結合によって性能が向上したことが考えられる。
過去の研究
第三回
手法
openSMILEを用い音声特徴量をとり、Deep Neural Networkで学習を行った。
結果
上表のbaselineの項目に記載。
第二回
手法
音声データをスペクトルグラム化してCNNでクラス分類
結果
正答率
学習データ 約95%
テストデータ 約64%
第一回
手法
Wavファイルの情報をそのまま一次元のCNNに渡して学習
結果
正答率
学習データ 約60%
テストデータ 約45%
AIの感情認識は様々な活用方法がある

ここまで感情認識についての解説や開発の経緯、種類、弊社の取り組みを主に解説してきました。
あまり聞きなれない言葉でも、意外なところで使われていたり、今後の技術の発展次第で無限の可能性を秘めていることが少しでも伝われば嬉しい限りです。
特に今後はよりAIが身近な存在になることが予想されますので、その進化の裏側で「こんな技術が使われているんだ」と気付きがあったり、AIに興味を持っていただければ幸いです。
弊社公式Twitter: https://twitter.com/crystal_hal3
弊社公式Facebook: https://www.facebook.com/クリスタルメソッド株式会社-100971778872865/
Study about AI
AIについて学ぶ
-

ディープフェイク=怖いだけじゃない?実は“必要とされる理由”と未来の可能性
ディープフェイク=怖いだけじゃない?実は“必要とされる理由”と未来の可能性 ディープフェイク技術。名前を聞くと、どこか怖いイメージを持っている人も多いのではない...
-

未来が爆誕する場所へ——テクノロジーで体感せよ!大阪・関西万博2025
「未来がここにある——テクノロジーで読み解く大阪・関西万博2025」 2025年、大阪にやってくるのは単なる「博覧会」ではない。それは、未來の社会をまるごと体験...
-

AIエージェントの登場!AI企業が目指す“自律型AI”。人間はもうインターフェースなのか?
かつてAIは、ただの道具だった。与えられたプロンプトを実行し、間違いなくタスクを処理する”静かな天才”。だが今、その構図が静かに崩れ始め...