blog
AIブログ
強化学習入門 アルゴリズムから解説
近年は掃除ロボットや車の自動運転など身近なところでAIの研究分野である強化学習が用いられています。
しかし、「強化学習とは」という問いに対して正確に答えられる人は少ないでしょう。
そこでこの記事では、AIを専門に研究開発する会社の視点から強化学習の例やアルゴリズムについてわかりやすく解説します。
強化学習とは
強化学習(Reinforce Learning)とは機械学習の手法の一つであり、与えた目標に対して試行錯誤を通じてタスクを実行できるようになる手法です。
わかりやすく言うと、コンピュータに目標を与え大量のデータを読み込ませ、自で目標達成のために試行錯誤を繰り返し、その過程で得た行動に基づいて識別や予測を行うアルゴリズムを自動で構築する技術のことです。
その他の機械学習
これまでは人間が一つ一つプログラムを組んでコンピュータに指示を出していたのですが、自身で学習しプログラムを構築する技術を備えたことで、自分で考えるAIが誕生しました。
その分野には
・強化学習
・教師あり学習
・教師なし学習
の3つがあり、これらを総称して「機械学習」と呼んでいます。詳細な説明は以下の記事をご確認ください。
教師あり学習
教師あり学習とは、学習データに人間が予め正解を与えた状態で学習させます。
そのため、教師あり学習は人間が与えた正解と一致するかどうかが基準になります。
例えば、大量の郵便物の宛名書きを読み取り、特定の都道府県だけを選別したいときなどは教師あり学習が有効になります。
教師なし学習
教師あり学習に対し、教師なし学習は学習データに正解を与えない状態で学習させるというものです。
AI自身が過去のデータの特徴や傾向から自身で判断して選択したり、行動したりします。
過去の膨大なデータと比較して判断する天気予報や売り上げ予測などに使われています。
このように機械学習の中にもそれぞれ得手不得手があり、うまく使い分けることで最短で最適な答えを導きだしています。
それぞれ、このようなイメージですね。
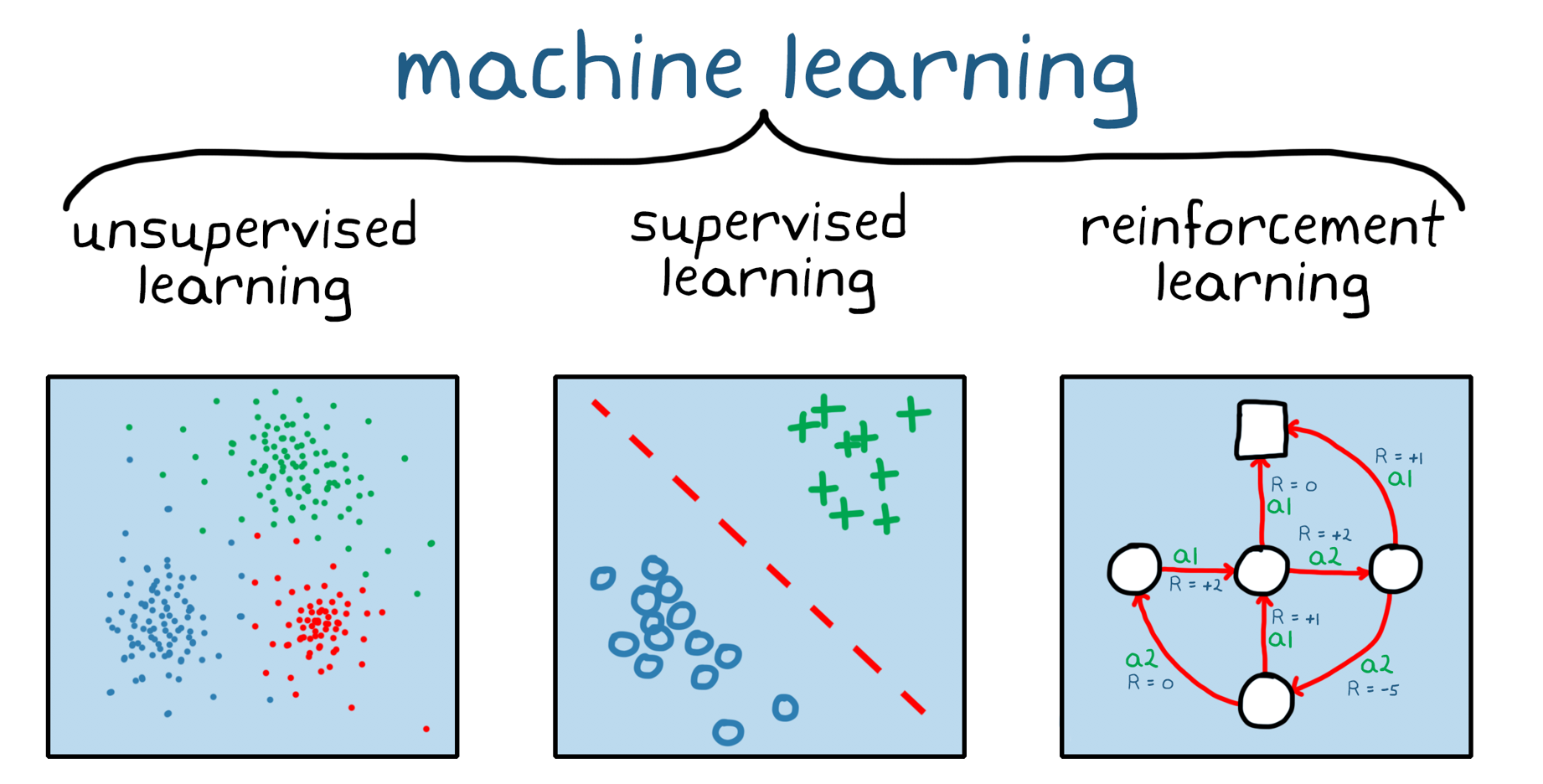
https://jp.mathworks.com/discovery/reinforcement-learning.html より引用
強化学習のアルゴリズム
強化学習は、ある「環境」下での学習の成果に応じて「目標(報酬)」が与えられ、将来的にその「目標(報酬)」が最ももらえるような行動をするように学習させていきます。
一度行動してみて、その行動の結果からさらに最良の結果となるよう何度も試行錯誤を繰り返させ、膨大なデータから瞬時に最良の行動を選択できるように学習させます。
強化学習で最も有名なのは「カーナビゲーションシステム」です。
目標(報酬)が設定され、そこに最短で辿り着くために無数のルートを瞬時に判断し、どのルートが最適かを導き出します。
以下の図のようにイメージすると、
- Agent(カーナビ)はPolicy(辿るルート)に基づいてAction(ルートを辿る)を実行
- その結果によってReward(報酬)を獲得する
- Policy・Actionが新しく設定され、次のステップに移行する
- Rewardを最大化するようなPolicy・Actionをみつけるまで1-3を繰り返す

https://ai.googleblog.com/2020/04/off-policy-estimation-for-infinite.html より引用
この方法の他にも代表的なアルゴリズムとしてDP法(動的計画法)、MC法(モンテカルロ法)、TD法(時間差分学習法)などがあります。
強化学習の活用事例
強化学習はゲームAIや自動運転、ロボットの制御などにも使われていますが、最も有名なものはAlphaGoでしょう。
AlphaGp
AlphaGoとはGoogle傘下のDeepMindという会社によって開発された囲碁プログラムであり、深層強化学習が使われています。
人間の棋譜のデータを元に自分自身と数千万回もの対戦を繰り返すことで最適な一手を打てるようになり、ついには世界トップ棋士にも完勝するようになりました。
囲碁は打つ手の手段が膨大にあり、戦局が刻一刻と変化します。感覚的なゲームであるという側面も持っているため、コンピュータでは人間を倒すことはできないとさえ言われていたために、AlphaGoの勝利は世界に衝撃を与えました。
ある分野では人間を超えるパフォーマンスを見せるまでに、AIは高性能になっているのです。
自動運転
強化学習は自動運転の分野でも事例があります。
Prefferd Networks社では、車が密集した交差点でミニカーを用いた自動運転を実施しました。強化学習を用いることで、周囲の状況を同時に把握できるため前方向だけでなく後ろ方向にも正確に移動できます。
以下の動画では実際に「ぶつからない車」として過去に自動運転の様子を展示した際の様子です。赤い車は人が動かしています。
強化学習の歴史
強化学習の原型は、機械の自律的制御を可能にする「最適制御」の研究として、1950年代には既に存在しました。
1990年頃には「強化学習の生みの親」とも呼ばれるカナダ・アルバータ大学のリチャード・サットン教授らを中心に、活発に研究されていました。
強化学習から深層強化学習への進化
前述のとおり1950年代から存在した強化学習ですが、ディープラーニングの登場で大きなターニングポイントを迎えました。
ディープラーニングとは、「深層学習」とも呼ばれ人間が自然に行うタスクをコンピュータに学習させる機械学習のうちの一つです。
人間の神経細胞であるニューロンの仕組みを参考にしたニューラルネットワークがベースになっており、そのニューラルネットワークを多層にすることでより多く深く学習させることが可能になりました。
今までの強化学習にディープラーニングを組み合わせたものを「深層強化学習」といい、これまでとは比較にならない情報量を処理し学習させることが可能になりました。
飛躍的に性能が向上し、複雑なシステムの制御が可能になったことでゲームやロボットなどにAIが取り入れられるようになったのです。
深層学習に関する詳細な説明は以下のリンクよりご覧ください。
弊社の強化学習の開発と今後への取り組み
このように、様々な分野で可能性を秘めている強化学習ですが、弊社ではこの強化学習を機械制御による物体把持に活用しています。
物体把持というと少し難しそうに聞こえますが、アームやロボットハンドによる「掴む・持つ」という動作に注目して日夜研究しています。
具体的には、自動車の組み立てを自動的に行う機械の開発や、お部屋の片づけロボ、人間が持てない柔らかさの物体を持つことができるロボットなどを開発しています。
人間の筋力では持ち上げられない重さや熱さ、大量の物体を強化学習によって自動で行えるようになれば、私たちの生活はより豊かになると信じ、日々研究開発に力を入れています。
AIと強化学習は密接に関係しており、まだまだ可能性がある
ここまで強化学習について解説してきました。
機械学習から発展し、ディープラーニングによって一気に高精度になり、現在は様々な分野に取り入れられています。
自身で学習を繰り返すことでより高精度になるAIは、今後私たちの生活と切っても切り離せなくなるでしょう。
この記事を読んで、強化学習やAIについて興味を持っていただけたり、もっと深く知りたいと思っていただければ幸いです。
※機械学習について詳しく知りたい方はこちらから
>>機械学習とは?詳しく解説
ご愛読いただきありがとうございました!
よろしければ弊社SNSもご覧ください!
Twitter https://twitter.com/crystal_hal3
Facebook https://www.facebook.com/クリスタルメソッド株式会社-100971778872865/
Study about AI
AIについて学ぶ
-

AI社員・AI上司とは何か?企業AIアバター活用の最前線【2026年】
2026年、「AI社員」という言葉をビジネスシーンで耳にする機会が増えています。AIが上司になる、AIが同僚として働く——そんな話題が現実のものになりつつある今...
-

Claude Codeの使い方|インストールからAI設計書生成まで完全実演【2026年最新】
この話について 第1話 / 全10話 2026年3月26日|著者: Kei Kawai|読了: 約15分 Claude Codeとは?2026年最新のAI開発ツ...
-

営業ロープレをAI化するメリットとは?課題をまとめて解決します
「営業ロープレをもっと効率的にできないか」という声は、営業責任者や研修担当者から絶えず聞かれます。ロープレは営業スキル向上に効果的な手法である一方、「相手の確保...