blog
AIブログ
音源分離とAIの関係について説明します!
皆さん、「AI」という単語を耳にすることが最近増えてきたのではないかと思います。しかし、その仕組みについて知りたいと感じても、「私には難しそう…」と敬遠してしまっている方も多いのではないでしょうか?
ここでは、AIの利用手段として大きな分野の1つになっている「音源分離」について、仕組みを分かりやすく解説します!
大まかな仕組み
AIを構成する重要な要素として、ニューラルネットワーク(Neural Network, NN)と呼ばれるものがあります。この「ニューラルネットワーク」は人間の脳における情報交流の流れを模倣したもので、AIはこのニューラルネットワークで入力を「色」や「形」、「模様」など注目すべき特徴量と呼ばれる情報に分解し、入力情報と判定モデルの情報を対応づけます。
そして、現在ではこのニューラルネットワークの考え方から発展した畳み込みニューラルネットワーク(Convolutional Neural Network, CNN)と呼ばれるものが広く使われています。当初、CNNは画像認識の分野で大きな成果を収めたネットワークだったのですが、その性能の高さから最近では音の判定など様々な分野へ応用されています。音源分離AIはこのCNNを用いて学習をしております。
音源分離
音源分離は、人間の持つカクテルパーティ効果という認知機能を機械で再現するものです。
カクテルパーティ効果とは、カクテルパーティのようにたくさんの人が会話し、騒がしい環境下でも自然と自分の会話相手の声を聞き分けられるように、人は自分と関わりのあることについて注意を傾けて聴く「選択的聴取」を行っていることを指します。つまり、耳に入った音が脳で処理され、「音が聴こえる」までの間には、マイクが周囲の音を拾うことと比べてかなりの高度な処理が行われているのです。例えば、騒がしい環境で会話ができていても、その状況を録音をしたものを聞いたら何を言っているのかわからない、というようなことが起こりえます。
このことをAIでも行うためには、どうすればよいのでしょうか?
人間の聴覚系自体まだ解明されていない部分も多く、完全に再現することはできませんが、AIによって特定の音を抽出することは可能です。そのためには、AIに対し、「分離処理を行いたい音源」と「正解として扱う音源」の2種類のデータを用意し、こちらで前述したCNNに大量のデータを入力し、この2種類の音声の対応関係を学習させることで、AIは「分離処理を行いたい音源」から「正解として扱う音源」を抽出することが出来るようになります。(以下、図)
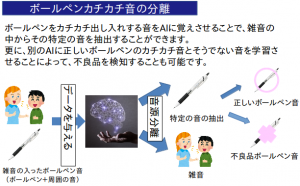
つまり、これを行うことで雑音の抑制が行えるように、すなわち、ノイズが含まれた音声からノイズの含まれていない音声を抜き出せるようになるのです!
活用が可能だと考えられる分野として以下のようなものがあります。
・会議議事録・・・会議音声の話者ごとの分離
・音声通信… 通信によるノイズを除去し、電話やテレビの音声をよりクリアにする。
・音声対話ロボット… 音声認識の精度向上
・自動採譜・・・楽器ごとに楽譜を作成
・補聴器・・・雑音を抑制し、騒音環境での聴きやすさを改善する。 , etc.
弊社では、ノイズ混じりの原音から人の音声を分離するAI、コネクタの咬合音を検知するAIなどを作成しております。ここに弊社のAIを利用した音源分離のサンプルを掲載しておきます。
雑音環境下での人の声の分離
上が雑音入り音声、下が分離後の人の声です。
このAIは他にもバンドの楽曲からインストゥルメントとボーカルの音を分離したりすることに利用できます。以下はその例になります。
多人数の声から一人の声を分離
異なる学習のさせ方を行うことで、多人数が同時に喋っている状況から、一人の音声のみを抽出することにも成功しています。
一番上が二人が同時に喋っている音声で、下2つがそれらを分離したものです。
コネクタ嵌合音検出
弊社のAIの中でも有数の精度を誇り、検出率は99%にも達します。現在、大手自動車メーカーの現場で活躍中です。
上は雑多な環境音であり、下はその環境からコネクタ音を抽出したものです。
音源分離について知っていただけたでしょうか?
ここまでご愛読いただきありがとうございました!
よろしければ弊社SNSもご覧ください!
Twitter https://twitter.com/crystal_hal3
Facebook https://www.facebook.com/クリスタルメソッド株式会社-100971778872865/
Study about AI
AIについて学ぶ
-

ディープフェイク=怖いだけじゃない?実は“必要とされる理由”と未来の可能性
ディープフェイク=怖いだけじゃない?実は“必要とされる理由”と未来の可能性 ディープフェイク技術。名前を聞くと、どこか怖いイメージを持っている人も多いのではない...
-

未来が爆誕する場所へ——テクノロジーで体感せよ!大阪・関西万博2025
「未来がここにある——テクノロジーで読み解く大阪・関西万博2025」 2025年、大阪にやってくるのは単なる「博覧会」ではない。それは、未來の社会をまるごと体験...
-

AIエージェントの登場!AI企業が目指す“自律型AI”。人間はもうインターフェースなのか?
かつてAIは、ただの道具だった。与えられたプロンプトを実行し、間違いなくタスクを処理する”静かな天才”。だが今、その構図が静かに崩れ始め...