blog
AIブログ
GPTとは?Chat GPTの起源「GPT-1」を解説します!
GPT(Chat GPT)とは、OpenAIが開発した言語モデルで、大量のテキストデータから言語学習を行い、人間にとても近い自然な文章を生成することができるチャットボットです。
本記事では、今話題となっているChat GPTの起源である「GPT-1」について、分かりやすく解説していきます。
GPTとは
GPT(Generative Pre-Trained Transformer)とは、自然言語処理(NLP)モデルの一種で、TransformerのDecoderによる事前学習に基づいた汎用言語モデルです。
GPTが「汎用」言語モデルと呼ばれる理由は、事前学習後にファインチューニングをすることによって、さまざまな自然言語処理タスク(テキスト含意判定、質疑応答、意味的類似性判定、文書分類など)を高い精度で行えるようになるためです。
この事前学習は教師なし学習によって行われ、ファインチューニングはタスクに合わせたラベル付きデータが与えられる教師あり学習です。
このように、教師なし学習でデータそのものの特徴を学び、教師あり学習でタスクに対する性能を上げる学習手法を半教師あり学習といいます。
また、GPTにはいくつかのバージョンがあり、Open AIのRadfordらが2018年に発表した「Improving Language Understanding by Generative Pre-Training」で登場したモデルは、現在GPT-1と呼ばれています。
GPT-1登場の背景
多くの深層学習モデルは、教師あり学習に基づいており、自然言語処理のタスクについてもそれは例外ではありませんでした。
教師あり学習は、学習データとして、正解ラベルをつけたデータが必要となります。そして、この正解ラベルをつける作業は手動なので、コストが非常にかかり、学習データの大規模化の妨げとなっていました。
この状況下で、ラベル無しデータを用いた教師なし学習は、データラベリングをより多く集めることに対する重要な代替案として挙げられるようになりました。
さらには、このような教師なし学習による特徴抽出に基づいた学習は、手動のラベリングによる教師あり学習よりも優れた結果を出すことがいくつかの論文により示されました。
しかし、この半教師あり学習には、
①タスクへの転移を最も効率的にするには、どのような特徴量を学習すべきか(どのような目的関数を設定すべきか)
②得られた特徴量をどのようにしてタスクへと転移させるか
という課題が残っていました。
GPT-1では、広い範囲のタスクで、そして極わずかなファインチューニングによって転移できる普遍的な表現の獲得を目標にしています。その上で、上述の課題に対して、
①言語モデルを教師なし学習する
②①で得られたパラメータをタスクに対応する目的関数によって教師あり学習する
という手法を提案しています。
GPT-1のアーキテクチャ
GPT-1は、大きく分けて三つの部分に分かれています。
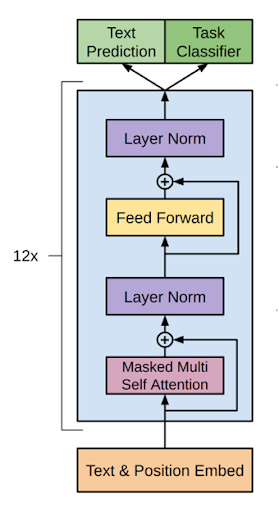
Alec Radford,Karthik Narasimhan,Tim Salimans,Ilya Sutskever 2018 Improving Language Understanding by Generative Pre-Training より画像の引用
埋め込み層
この層は、非常に大きな次元のone-hotベクトルになっている単語を低次元のベクトルに埋め込むための層です。ここでは、単語レベルの埋め込みだけでなく、位置についての埋め込みも同時に行なっています。
4.事前学習にて詳しく説明しますが、位置の埋め込みの手法は、元のTransformerと異なり、学習可能となっています。
Transformer Decoder12層
文章を低次元ベクトルに埋め込んだら、次はTransformer Decoderに埋め込みベクトルを通します。
ただし、ここで登場するTransformer Decoderは、元のTransformerと比較するとFeed Forwardの手前にあったMulti-Head AttentionとAdd&Normという層(図中赤枠で囲われている部分)が無くなっています。

Ashish Vaswani,Noam Shazeer,Niki Parmar,Jakob Uszkoreit,Llion Jones,Aidan N. Gomez,Łukasz Kaiser,Illia Polosukhin 2017 Attention Is All You Need 3 より画像の引用
出力層
出力層は、Text Prediction(文章の予測)とTask Classification(タスクの分類)に分かれています。前者は、GPT-1が学習する言語モデルの出力のための層で、後者はファインチューニングにおいて、タスクごとに応じた出力を得るための層です。この記事では前者を言語モデル出力層、後者をタスク出力層と呼ぶことにします。
後ほど説明しますが、言語モデルでも、タスクでも(2)の層までは共通のパラメータを用いています。そのため、(2)までの層が学習されていれば、タスク出力層をそこにくっつけて微調整(ファインチューニング)することでタスクをこなせるようになります。
事前学習
事前学習では、言語モデルを学習します。言語モデルは、文脈と呼ばれる一定の長さに切り取られた文章を入力として与え、その続きとしてあり得る単語を予測するモデルです。
例えば、「今日の天気は」という入力を受け取った場合、この次の単語として「晴れ」などと予測します。
天気の話をしているという文脈を読み取った上で、次の単語としてあり得るものが天気に関する言葉であると予測するのです。
この例で分かるように、言語モデルが上手く学習できたということは、単語の意味、単語と単語の関係、そして文脈の読み方といった知識を学習できたといえます。
GPT-1では、この知識がさまざまな自然言語処理タスクで利用可能であると考えているのです。
また、GPT-1では自然言語の抽象的な知識を得るために学習していますが、言語モデルは、最初に文の始まりを入力として渡し、その出力を使ってまた入力とする、ということを繰り返すことによって、文章の続きを書くという処理を行えます。
先ほどの例を用いると、前回の出力を元の入力に付け加えた新しい文章「今日の天気は晴れ」を入力とし、以降その出力を前の文章に付け加えるということを繰り返すことによって、最終的に「今日の天気は晴れです。」などの文章を得ることができます。このように自身の出力を新たに入力として使い出力を繰り返すモデルを自己回帰モデルといいます。
ファインチューニング
言語モデルの学習が終わったら、ラベル付きデータセットを用いてパラメータを解きたいタスクに最適化していきます。
このラベル付きデータセットは後ほど説明する変形によって、GPT-1の入力として受け取れるようにしているものとします。
ファインチューニングでは、タスク出力層の出力がラベルを正しく予測できるように学習します。ここで、本来ならば言語モデル出力層はこの学習において無関係となりますが、言語モデルも同時に学習することによって、タスクに対する精度も高まることが報告されています。
タスクに合わせた入力の変形
GPT-1では、モデルの構造上、ラベルを分類するようなタスク(文章分類など)が暗に仮定されていますが、実際のタスクはその限りではありません。
タスクごとにどのような変形を施すのが良いか紹介していきます。
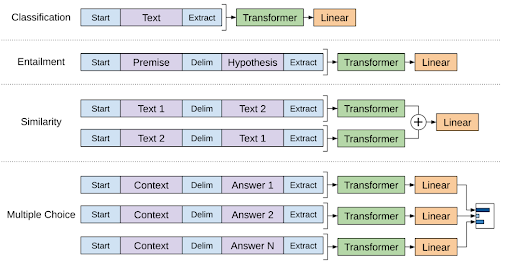
Alec Radford,Karthik Narasimhan,Tim Salimans,Ilya Sutskever 2018 Improving Language Understanding by Generative Pre-Training より画像の引用
文章分類
これは、先述の通りほとんど調整が必要ないです。文章の初めと終わりが認識できるように、ターゲットとなる文章の初めにStart、終わりにExtractというトークンを差し込みます。
文章分類に限らず、どのタスクにおいても文章の初めと終わりにはこの二つのトークンが登場します。(以降この二つのトークンについては省略して説明します。)
文章含意
このタスクは、前提と仮定が与えられ、前提が真のとき、仮定も真になるかを判定するタスクです。
前提(premise)と仮定(hypothesis)が入力となるので、この二つの間にdelimiter(区切り文字)トークンを差し込んで、これを一つの入力とします。
文章の類似性判定
(2)の文章による推論には、入力の順番に意味がありましたが、文章同士の類似性を図る場合、入力として与えられる文章の順番には意味がありません。
順番の要素を排除するため、文章1・区切り文字・文章2と文章2・区切り文字・文章1という順番の異なる二つの入力をそれぞれ入力として与え、それぞれのTransformer Decoder層の出力の和をタスク出力層の入力とします。
質疑応答と常識推論
このタスクでは、文脈と質問、そして回答としてありえるいくつかの選択肢が与えられます。
出力として欲しいのは、どの回答が最も適切なのか、なので、文脈と質問・区切り文字・回答の一つという形の入力をすべての回答について作り、それぞれGPT-1に通して、それぞれのもっともらしさという形で出力を得ます。
GPT-nへの展望
ここまでGPT-1について説明してきましたが、2019年にGPT-2、2020年にGPT-3、2023年にGPT-4が発表されました。GPT-2以降のGPT-1からの特に大きな変更点を解説します。
GPT-2
GPT-1からGPT-2への主な変更点は以下のとおりです。
- ファインチューニングを行わなくなった
- Webクローリングによるコーパスのさらなる大規模化
ファインチューニングには、ラベル付きデータが必要、学習したタスク以外では精度があまり良くないといった問題点がありました。そこで、タスクの見方を変えます。
従来は、タスクは入力に対して適切な出力を予測する、というものでした。これを、タスクは条件付けられた入力に対して適切な出力を予測する、と変えます。ここで言う条件とは、入力がどういうタスクを指しているのか、を表しています。この入力を工夫する発想の転換により、GPTはより多くのタスクに対応できるようになったのです。
もちろん、ファインチューニングが無くなったため、タスクへの適応も難しくなったはずですが、モデルのパラメータ数を増やし、学習に用いるコーパスもWeb上の良質な文章を自動的に獲得することによってさらに大規模化したため、ファインチューニング無しでもタスクに対する精度を高めることができたのです。
GPT-3
GPT-2からGPT-3への主な変更点は以下のとおりです。
- パラメータ数とコーパスのさらなる大規模化
- Sparse Transformer風のAttentionパターンの採用
GPT-3では、GPT-2からさらにモデルが大規模化しました。これにより、性能や対応可能な文章の範囲が広がることを期待できますが、計算量が膨大となることも容易に想像が着きます。
そこで、計算量を減らす工夫として、Sparse Transformer風のAttentionパターンを採用しました。Sparse Transformerについては詳しく説明しませんが、元のTransformerのDecoder層とどのように変わったかを説明します。
従来のTransformerで使われているAttentionは、ある位置の単語を予測する際に、その手前にある単語すべてを用いていました。この手法の問題点は、計算量が入力文章の長さの二乗のオーダーで増えていってしまうことです。
この問題を解決する手法として提案されたのがSparse Transformerです。Sparse TransformerのAttentionは、手前にあるすべての単語を参照するのではなく、位置ごとにどれだけ手前まで参照するかを定めています。
GPT-4
最後に、2023年4月現在最新発表されているものでは最新のGPT-4です。GPT-4は、今までのOpenAIの方針と打って変わって、論文で技術的な詳細は説明されていません。これは、汎用言語モデルの開発が競合している背景や、安全上の理由からこのような判断に至ったと論文では説明されています。
論文内で明記されているモデル構造の変化は、人間のフィードバックによる強化学習を用いたモデルのファインチューニングの採用です。これは、2022年に発表されたInstruct GPTにおいて発表された、GPTの出力をより人間の好みに合わせた出力になるように学習するという手法です。
もちろん、質問に対して求めているような回答を得られるようにするためのものですが、ユーザーにとって有害な文章を生成しないように、人間界のマナーをGPTに理解させる取り組みでもあります。
GPT-4での変更点で最も特徴的なのは、画像を入力として与えられるようになったことです。
GPTの活用例
ChatGPTの汎用性は非常に高く、目的に合わせて上手く指示をしてあげると非常に便利なツールとなります。ここからは、Chat GPTの活用例を紹介していきます。
言語学習
Chat GPTは大規模言語モデルなので、もちろん言語についての知識に精通しています。
例えば英語学習をする場合、実際に英語で雑談などをしてみる、英語で書いた文章を添削してもらう、単語や文法について説明してもらうなど、さまざまな方法で使うことができます。
プログラミング
Chat GPTは、コーディングが非常に得意です。例えば、〇〇をするコードを〜〜言語で書いてと指示をすると、高い精度で対応するコードを出力してくれます。
さらには、ある言語で書かれたコードを別の言語での書き換え・コードが何をやっているかの説明、ある言語の文法についての説明をしたりもできます。コーディングの手間を省くことも、プログラミングの学習にも使えるのです。
文章の要約
非常に長い文章を読まなくてはいけないときや、自分の考えをつらつらと書いた文章を人が分かりやすいようにまとめたいとき、Chat GPTに文章を渡して要約してもらうこともできます。
ただし、重要な情報を必ずしも理解できているわけではないので、肝心なとこが抜け落ちてしまうこともあるので注意してください。
まとめ

ここまで、GPT-1の仕組みとGPT-nについて紹介してきました。GPT-1は、言語モデルを学習し、その知識をさまざまなタスクで活かすことで汎用性を得たモデルです。
そして、以降登場したGPT-nは、GPT-1をベースにモデルおよびコーパスの大規模化を施すことで、ついにはファインチューニング無しでさまざまなタスクに対処可能になりました。
GPTの進化は目覚ましく、特に2022年の終わりから2023年の始まりにかけては、Chat GPTが世間に知れ渡るようになり、多くの人に活用され始めています。
今後もGPTのさらなる発展はもちろん、独創性溢れるChat GPTの活用事例が登場することに期待します。
クリスタルメソッド公式note:https://note.com/crystalmethod/
X:https://x.com/YCrystalmethod
YouTube:https://www.youtube.com/@haltalktube
Study about AI
AIについて学ぶ
-

営業ロープレをAI化するメリットとは?課題をまとめて解決します
「営業ロープレをもっと効率的にできないか」という声は、営業責任者や研修担当者から絶えず聞かれます。ロープレは営業スキル向上に効果的な手法である一方、「相手の確保...
-

AIロープレとは?営業・接客・面接練習での活用法を解説します!
人手不足が深刻化し、新人教育の「早期戦力化(イネーブルメント)」が企業の最重要課題となる中、教育現場に破壊的なイノベーションが起きています。 従来のコミュニケー...
-

AIロープレツールの選び方|比較ポイントと主要ツール比較を解説
「AIロープレを導入したいが、どのツールを選べばいいかわからない」という声をよく聞きます。AIロープレツールは種類が増えており、対応している業種・機能・価格もさ...