blog
AIブログ
Pythonを使って機械学習を実装する

機械学習とは、膨大な量のデータから法則性を見つけ出し学習する技術の事を指します。
この機械学習は、Pythonを使用することで簡単に実装することができます。
今回はPythonによる実際のコードを交えながら、機械学習をどのようにして行っていくかを説明します。
機械学習についてはこちらの記事で詳しく解説していますのでご覧ください。
>> 機械学習とは?概要やアルゴリズムを詳しく解説!
機械学習とは?
機械学習には、教師あり学習・教師なし学習・強化学習の3種類、学習方法が存在します。それぞれ見ていきましょう。
教師あり学習
教師あり学習は、既知の正解データに基づいて学習するデータがその正解データと比較して間違っていないかを確かめる機械学習です。この学習方法の中には、回帰と分類の2種類の方法が存在します。
回帰
正解データより法則性を認知して、未知のデータをその法則に当てはめることで値を算出する方法。
参考までに、回帰分析について、以上の動画で視覚的に詳しく解説されています。
分類
複数の区分けによって、データを分割する方法。正解データは、分割時に必要な境界線を明確にするために必要になります。
教師なし学習
教師なし学習は、学習のための正解データを用いずに学習をしてしまう方法です。人工知能が完全な正解を教師なし学習によって取得をすることは困難ですが、多数のデータを学習させることによって読み込んだデータの規則性を導き出すことができます。
明確な答えが提示されていない問題に対しては、教師なし学習をしなくてはいけません。この学習方法にも2種類の方法が存在します。
次元削減
多次元的に示されているデータの次元数を減らすことによって、データを見やすい状態にすることを言います。
クラスタリング
与えられたデータの特徴量から、そのデータ群をいくつかのグループに分けることです。
参考までに、以上の動画でクラスタリングについて視覚的に詳しく解説されています。
強化学習
強化学習は、人工知能が設定された目標に到達するために自律的な反復学習をする方法です。アルゴリズムの選定も人工知能自身が行うため、ほとんど人間の手を介さずに学習することができます。
Pythonについて

機械学習の開発で最も使われている言語はPythonです。まず、Pythonとはどのような言語で、なぜ機械学習の開発によく使われているのでしょうか。そして、実際にどうしたらPythonは使えるのでしょうか。それぞれ解説します。
Pythonの概要
1.文法がシンプルで簡単
Pythonの特徴としてまず挙げられるのが文法のシンプルさです。そのシンプルさ故、初心者から職業プログラマーまで広くに使用されており、Pythonの使用人口がとても多いことが大前提としてあります。そして、多くの機械学習エンジニアやデータサイエンティストは、数学や統計などを専門としていた人が多くプログラムが全く分からないことも珍しくありません。そんな機械学習のスペシャリストたちにもとっつきやすい言語であるというのもPythonが使われている大きな理由の一つです。またYoutubeやInstagramなどの大企業が、サービスの根幹となる部分にPythonを使用していることから、その信頼性も担保されています。
2.ライブラリが豊富
開発中こんな機能が使いたいとなった時、Pythonならばその殆どが既にライブラリとして公開されています。すなわち、他人が作成したプログラムを勝手に利用することが出来るのです。もちろん機械学習向けのライブラリやフレームワークも豊富にあり、このライブラリの豊富さが、Pythonが機械学習の開発で最も使われる所以と言えるでしょう。
Pythonの導入
では、実際にPythonを導入してみましょう。
Pythonを使う方法は色々ありますが、今回は「Google Colaboratory」を使って導入を行います。
「Google Colaboratory」はグーグルが提供するブラウザ上でのPython実行環境で、下記リンクにアクセスすれば、数分もかからずにPythonでの分析を行うことが可能です。導入までの手間、そして使い方の習得が他の方法に比べて圧倒的に楽であり、かつ使い勝手の良いデザイン、GUIなので実際に大学での研究データ分析や商業データ分析など広く使用されています。
[Google Colaboratoryの公式ページ]
>>https://colab.research.google.com/
リンクにアクセスするとチュートリアル画面になるかと思います。実際に使うには、左上の「コード+」という所をクリックし、コードセル(一番左に再生ボタンのようなマークのある空欄)を出します。空欄にコードを書き、左の再生ボタンのようなもの(これが実行ボタンです)をクリックすると空欄内のコードが実行される、という仕様です。
Pythonについてもっと詳しく知りたい!と思った方は、Python公式ドキュメント内のチュートリアルやその他様々なサイトでPythonの基本について解説されていますので、そちらを参照してみて下さい。
また、Pythonに関係して以下の記事があります。ぜひ読んでみて下さい。
[関連記事]
>> Pythonでテキストマイニングをする方法
Python「教師あり学習」実装例

実際に、「教師あり学習」を例にとって機械学習がPythonで行われている様子を見てみましょう。なお、順々に登場するコードを先程紹介したGoogle Colaboratoryのコードセルに1つずつ入れて、順番通りに実行すれば同様の結果が得られます。
① モジュール・学習データ取り入れ
$ python import numpy as np #データを構造的に扱うモジュール import matplotlib.pyplot as plt #データを可視化するモジュール %matplotlib inline from sklearn import datasets #今回学習するデータセット「Iris(あやめデータ)」を取り入れる Learning_Data = datasets.load_iris() #変数「Learning_Data」にあやめデータを格納
まず、データを構造的に扱い、機械学習手法を簡単に使えるようにするためのライブラリ・モジュールをインポートします。
イメージとしては、元々外部にあった「手法一覧」のようなものを手元で扱える状態で置いておくようにする、といった感じです。
なお、「Iris(あやめデータ)」は具体的にはあやめの花150個について、それぞれ数種類の寸法データが記録されているものになります。
② 線形単回帰分析
$ python x = Learning_Data.data[:, 0] #xに0列目「がく片の長さ」 y = Learning_Data.data[:, 2] #yに2列目「花びらの長さ」 データを格納 plt.scatter(x, y) #(x,y)の散布図表示
[結果]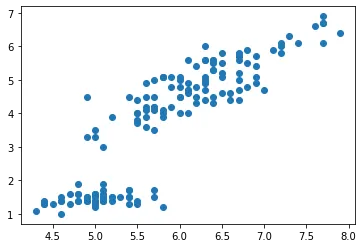
今回はデータの中でも「0番目:がく片の長さ」と「2番目:花びらの長さ」の2種類のデータについて機械学習を行います。
2種類のデータの関係性について調べるために、まず散布図を表示しました。強い正の相関(一方が大きいほど、もう一方も大きい)があるように見えます。
これを線形単回帰分析(データに対して直線的な関係を当てはめる)し、相関(2種データの関係性)について分析します。
$ python from sklearn import linear_model #機械学習モジュール導入 model = linear_model.LinearRegression() model.fit(Learning_Data.data[:, 0].reshape(-1, 1), Learning_Data.data[:, 2]) #データを機械学習モジュールが「学習」 def f(x): return model.coef_[0] * x + model.intercept_ #線形回帰関数(coef~が係数、interceptがy切片) xmin = x.min() xmax = x.max() plt.plot([xmin, xmax],[f(xmin), f(xmax)]) plt.scatter(x, y) [結果]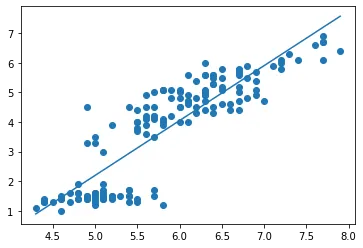
以上のように線形単回帰分析を行うことが出来ました。このようにして直線関係を証明すると、例えばxの大きさ(がく片の長さ)からyの大きさを推測する等、様々なことが可能になります。
③ サポートベクトルマシン
最後に、分類アルゴリズムの1つである「サポートベクトルマシン」についてPythonで実装します。
サポートベクトルマシンは以下の動画のような原理でデータを分割するアルゴリズムです。
下記のページではサポートベクトルマシンについて詳しく解説されていますので、ぜひご確認ください。
>> 機械学習とは?概要やアルゴリズムを詳しく解説!
$ python training_data = Learning_Data.data[:, [1, 3]] target = Learning_Data.target for i, color in enumerate("rgb"): plt.scatter(training_data[target == i, 0], training_data[target == i, 1], color=color) [結果]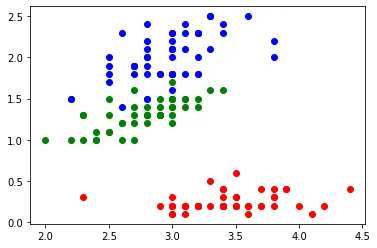
まず、あやめの種類で色分けした散布図を作りましたが、これで種類ごとに特性があることが明らかになりました。
$ python from sklearn import svm model = svm.SVC() model.fit(training_data, target) #サポートベクトルマシンによる学習完了 xmin = training_data[:, 0].min() #ここからは色分けして表示する作業 xmax = training_data[:, 0].max() ymin = training_data[:, 1].min() ymax = training_data[:, 1].max() xs = np.linspace(xmin - 0.1, xmax + 0.1, 300) ys = np.linspace(ymin - 0.1, ymax + 0.1, 300) xmesh, ymesh = np.meshgrid(xs, ys) plt.contourf(xmesh, ymesh, model.predict(np.c_[xmesh.ravel(), ymesh.ravel()]).reshape(xmesh.shape), levels=[-0.5, 0.5, 1.5, 2.5, 3.5], colors=["r", "g", "b"]) for i, color in zip(range(3), "rgb"): plt.scatter(training_data[target == i, 0], training_data[target == i, 1], color=color, linewidth=1, edgecolor="k", marker="o") [結果]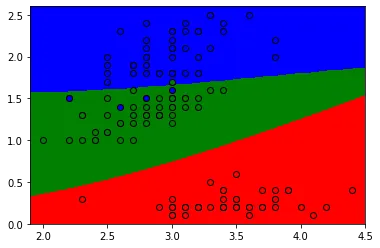
学習データに対してサポートベクトルマシンによる学習を行い、そしてサポートベクトルマシンにより分けられた境界を3色使って表したものが以上の結果になります。
今回は特に各種類ごとの特性が違ったので、ほぼ完璧に各色ゾーン(各種類のゾーン)に例外なくその色の要素が入ることになりました。
こうなると、次の1個に関して仮に種類が分からなくても、寸法だけ見ればどの色のゾーンに居ることになるかは分かるので、それを基にして種類を推測することが可能になります。
[コード引用先]
>> Pythonの機械学習ライブラリ「scikit-learn」で実践する「教師あり学習」「教師なし学習」
Study about AI
AIについて学ぶ
-

AI社員・AI上司とは何か?企業AIアバター活用の最前線【2026年】
2026年、「AI社員」という言葉をビジネスシーンで耳にする機会が増えています。AIが上司になる、AIが同僚として働く——そんな話題が現実のものになりつつある今...
-

Claude Codeの使い方|インストールからAI設計書生成まで完全実演【2026年最新】
この話について 第1話 / 全10話 2026年3月26日|著者: Kei Kawai|読了: 約15分 Claude Codeとは?2026年最新のAI開発ツ...
-

営業ロープレをAI化するメリットとは?課題をまとめて解決します
「営業ロープレをもっと効率的にできないか」という声は、営業責任者や研修担当者から絶えず聞かれます。ロープレは営業スキル向上に効果的な手法である一方、「相手の確保...