blog
AIブログ
Pythonでテキストマイニングをする方法を詳しく解説します!
テキストマイニング(text mining)とは、テキスト(text:文章)とマイニング(mining:採掘)を合わせた造語で、膨大なテキストデータの中から価値のある情報を抽出する一連の作業のことを指します。
具体的には「自然言語処理」と呼ばれる技術を用いて、まず文章を「それ自体で意味をもつ最小単位(→形態素)」に分割します。この技術を自然言語処理の中でも「形態素解析」と呼びます。形態素解析を行った後、例えば「どの単語の登場回数が多いか」「時系列で見ると何か規則はないか」など価値創造につながる情報を統計学の知識等を用いて集計・抽出し、本来の目的に活かします。
自然言語処理、形態素解析に関する詳細記事は下記事項をご確認ください。
[関連記事]
>> 自然言語処理(NLP)とは?AI技術自然言語処理方法解説
[関連記事]
>> 形態素解析について、Python実装を交えて解説します!
テキストマイニングについて更に詳しく解説している記事もありますのでこちらも是非ご覧ください。
[関連記事]
>> テキストマイニングとは?ツールや実例まで解説
[関連記事]
>> テキストマイニングとは?実際の例について解説
そして、テキストマイニングを行う方法はいろいろありますが、その中でもおすすめなのが、Pythonを使う方法です。
その理由は充実しているモジュールにより、他言語よりも短いコードでテキストマイニングを行えるからです!
テキストマイニングの手法は以下のようなものがあります。
各技術についてざっくりと説明すると、
形態素解析
-先程説明した通り、文章を意味を持つ最小単位(→形態素)に分割する、テキストマイニングにおいて最初の一歩であり非常に重要な自然言語処理技術です。他4つの手法も、全て形態素解析を行うことが前提です。
センチメント分析
-例えばレビューや動画・ブログのコメント等の文章データからその人が持つ感情を読み取る技術です。
クラスター分析
-各個体の複数種類のデータ(例:人間各個体の「身長」「体重」「年齢」「居住地域」)から似ている性質の個体をグルーピングする統計学的手法です。
主成分分析
-クラスター分析と同様のデータに対して、似ている性質を持つ「変数」がないか分析し、それらをまとめて表す新たな「変数」を作成する統計学的手法です。この時、新たに作る変数の総数は既存の変数の総数よりも少なく、より低次元で(少ない変数で)対象を説明できるようになります。
ワードクラウド
-長めの文章、例えばスピーチ原稿やあるアカウントの今までの全てのコメント等から各単語の出現回数をカウントし、そして出現回数に応じた大きさの単語を一枚に並べて表現する手法です。
今回はこの5つの手法について、Pythonでの実装方法を解説します。
Pythonの導入
テキストマイニングにかかわらず、機械学習の開発で最も使われている言語はPythonです。まず、Pythonとはどのような言語で、なぜ機械学習の開発によく使われているのでしょうか。そして、実際にどうしたらPythonは使えるのでしょうか。それぞれ解説します。
(Python実行環境がある方等は飛ばして読んでいただいても支障はございません。)
1.文法がシンプルで簡単
Pythonの特徴としてまず挙げられるのが文法のシンプルさです。そのシンプルさ故、初心者から職業プログラマーまで広くに使用されており、Pythonの使用人口がとても多いことが大前提としてあります。そして、多くの機械学習エンジニアやデータサイエンティストは、数学や統計などを専門としていた人が多くプログラムが全く分からないことも珍しくありません。そんな機械学習のスペシャリストたちにもとっつきやすい言語であるというのもPythonが使われている大きな理由の一つです。またYoutubeやInstagramなどの大企業が、サービスの根幹となる部分にPythonを使用していることから、その信頼性も担保されています。
2.ライブラリが豊富
開発中こんな機能が使いたいとなった時、Pythonならばその殆どが既にライブラリとして公開されています。すなわち、他人が作成したプログラムを勝手に利用することが出来るのです。もちろん機械学習向けのライブラリやフレームワークも大量豊富にあり、このライブラリの豊富さが、Pythonが機械学習の開発で利用さえる頻度が高い所以と言えるでしょう。
では、実際にPythonを導入してみましょう。
Pythonを使うには、「Anaconda」や「Pycharm」といった実行環境をインストールしたり、コマンドプロンプトから実行したり色々な方法がありますが、今回は「Google Colaboratory」を使って導入を行います。
[参考リンク]
>> Google Colaboratory
「Google Colaboratory」はグーグルが提供するブラウザ上でのPython実行環境です。
ブラウザで(上記リンクに)アクセスすれば、数分もかからずにPythonでの分析を行うことが可能です。導入までの手間、そして使い方の習得が他の方法と比較すると圧倒的に楽であり、かつ使い勝手の良いデザイン、GUIなので実際に大学での研究データ分析や商業データ分析など広く使用されています。
リンクにアクセスするとチュートリアル画面になるかと思いますが、実際に使うには、左上の「コード+」という所をクリックし、コードセル(一番左に再生ボタンのようなマークのある、空欄)を出します。空欄にコードを書き、左の再生ボタンのようなもの(これが実行ボタンです)をクリックすると空欄内のコードが実行される、という仕様です。
初心者の方でPythonについてもっと詳しく知りたい!と思った方や、この後に出てくるテキストマイニング技術のコードについて仕組みまで理解したい!と思った方は、Python公式ドキュメント内のチュートリアルやその他様々なサイトでPythonの基本について解説されていますので、そちらを参照頂ければ後に出てくるコードも理解できるものになるかと思います!
[参考リンク]
>> Python チュートリアル(Python公式)
形態素解析
最初の説明の通り、形態素とは、言葉が意味を持つまとまりの単語の最小単位のことで、形態素解析とは文章を形態素に分割してそれらの品詞や用法等の情報を回収・分析することです。
Pythonを用いて形態素解析を行う際には、既に構築・開発されている形態素解析システムを使います。
形態素解析システムにも様々な種類がありますが、今回は最もメジャーな形態素解析システムであるMeCabのPython版、Mecab-Python3を使用します。
またMeCabはC++で実装されている形態素解析システムですが、他システムと比べて簡略なコードで済み、動作も高速で精度も良いことから他言語で再構築が行われています。その内の1つに「Janome」というコード全てをPythonによって再度記述した、Mecab同様のアルゴリズムを持つ形態素解析システムが存在します。全てPythonで記述されていることから、Pythonでの導入・利用が簡便である一方、実行速度においてMecabに少し劣ります。
今回は、入力された文字に対して「分かち書き」を行う方法と、更に詳しく形態素解析を行う方法を説明します。
まず、「分かち書き」について、その概念と手法について説明します。「分かち書き」は形態素解析において最も基礎的な操作で、具体的には「与えられた文章を形態素単位に分割し、『/(スラッシュ)』等で区切って文章を表現する」ことを指します。この分割作業を行った後に、各形態素について品詞や意味・用法を特定する作業がいわゆる「形態素解析」です。
まずMecabをインストールします。
#Mecab-Python3 導入コード
!pip install mecab-python3 #インストール
!pip install unidic-lite #辞書インストール
以上のコードにより下準備ができたので、以下のコードを実行して分かち書きを実行してみましょう!
今回は、2つの一般的な日本語の文章と、1つ英文も混ぜて検証してみることにします。
#分かち書き実践
import MeCab #Mecabインポート
wakati = MeCab.Tagger(“-Owakati”) #分かち書きモードのインスタンス作成
print(wakati.parse(“AIと機械学習と人工知能、これらはそれぞれ少しずつ違う概念です。”).split())
print(wakati.parse(“今日のお昼ご飯は「ラーメン」です。”).split())
print(wakati.parse(“I will do my best.”).split())
すると、出力は以下のようになります。
#出力結果
[‘AI’, ‘と’, ‘機械’, ‘学習’, ‘と’, ‘人工’, ‘知能’, ‘、’, ‘これ’, ‘ら’, ‘は’, ‘それぞれ’, ‘少し’, ‘ずつ’, ‘違う’, ‘概念’, ‘です’, ‘。’]
[‘今日’, ‘の’, ‘お’, ‘昼ご飯’, ‘は’, ‘「’, ‘ラーメン’, ‘」’, ‘です’, ‘。’]
[‘I’, ‘will’, ‘do’, ‘my’, ‘best’, ‘.’]
「形態素」とは意味をもつ最小単位のことですが、形態素解析システムにより、その結果は少し異なります。例えば、他の形態素解析システムに京都大学が制作した「JUMAN」が挙げられますが、このリンクからブラウザ上でJumanの形態素解析を試すことができます。このデモソフトで、今回1つめに解析した「AIと機械学習と人工知能、これらはそれぞれ少しずつ違う概念です。」を解析した所、以下のような結果を返しました。

特に赤い丸で記した部分は、先程のMecabによる解析の際は「少し」「ずつ」と2つの形態素に分かれていましたが、Jumanによる解析では「少しずつ」と1つの形態素であると判別されました。
このように、文章の形態素分割方法は形態素解析システムごとに少しずつ異なります。これは形態素解析システムの参照する辞書・コーパスの違いやアルゴリズムの違いに由来するものですが、必ず一方が正解ということはなく、目的に応じて解釈を変え、使うシステムやパラメータ把握・調整する必要があります。より詳しい仕組みが知りたい方は以下の記事を参照して下さい!
[関連記事]
>> 形態素解析について、Python実装を交えて解説します!
また、3つ目に解析されている英文は、単語ごとに区切られているだけであることが分かります。英文の形態素分割は、言語の特性上「短縮表示の切り離し」や「固有名詞の判別」を行えば、あとは単語ごとに切り離すだけであり、日本語のそれと比べて簡単です。
先程のJumanの解析結果のように、分かち書きだけでなく品詞や用法、読み方等も表示される形態素解析をMecab-Python3で実行してみましょう!
#形態素解析をMecab-Python3で実行
tagger = MeCab.Tagger() #tagger変数を形態素解析を行うインスタンスに設定
print(tagger.parse(“AIと機械学習と人工知能、これらはそれぞれ少しずつ違う概念です。”))
print(tagger.parse(“I will do my best.”))
すると、以下のように結果を返します。
#出力結果
AI AI AI AI 名詞-普通名詞-一般 0
と ト ト と 助詞-格助詞
機械 キカイ キカイ 機械 名詞-普通名詞-一般 2
学習 ガクシュー ガクシュウ 学習 名詞-普通名詞-サ変可能 0
と ト ト と 助詞-格助詞
人工 ジンコー ジンコウ 人工 名詞-普通名詞-一般 0
知能 チノー チノウ 知能 名詞-普通名詞-一般 1
、 、 補助記号-読点
これ コレ コレ 此れ 代名詞 0
ら ラ ラ 等 接尾辞-名詞的-一般
は ワ ハ は 助詞-係助詞
それぞれ ソレゾレ ソレゾレ 其々 名詞-普通名詞-副詞可能 2,3
少し スコシ スコシ 少し 副詞 2
ずつ ズツ ズツ ずつ 助詞-副助詞
違う チガウ チガウ 違う 動詞-一般 五段-ワア行 連体形-一般 0
概念 ガイネン ガイネン 概念 名詞-普通名詞-一般 1
です デス デス です 助動詞 助動詞-デス 終止形-一般
。 。 補助記号-句点
EOS
I I I I 名詞-普通名詞-一般 0
will will will will 名詞-普通名詞-一般 0
do do do do 名詞-普通名詞-一般 0
my my my my 名詞-普通名詞-一般 0
best best best best 名詞-普通名詞-一般 0
. . 補助記号-句点
EOS
形態素ごとに品詞など様々な情報が表示されていますが、Mecabでは、形態素ごとに以下の情報を返しています。
- surface:表層形(表示されている形)
- part_of_speech:品詞(品詞情報が1つ、細分類情報が3つの計4つの情報)
- infl_type:活用型
- infl_form:活用形
- base_form:基本形
- reading:読み
- phonetic:発音
また2つ目の英文は品詞が正しく識別されていません。このことから、Mecabは英語の形態素解析には対応していないことが分かりますが、これはMecabの使っている辞書・コーパスが英語に対応していないことが原因に挙げられます。
次節からの技術は、テキストマイニングにおいてはこの形態素解析の情報がないと何も出来ません。それだけ形態素解析が重要な技術であることが分かります。
形態素解析の基本の仕組みや他システムについて気になった方は是非こちらの関連記事をご覧下さい。
[関連記事]
>> 形態素解析について、Python実装を交えて解説します!
センチメント分析
最初に説明した通り、センチメント分析はレビューや動画・ブログのコメント等の文章データからその人が持つ感情を読み取る技術です。
センチメント分析ではセンチメント分析システムoseti、そして形態素解析システムMeCabを利用します。
この分析を行うと、osetiではこの文章がポジティブなのかそれともネガティブなのか二択で判断します。そして、「(この文章が)Positiveである確率」と「Negativeである確率(=1 – P(ポジティブ))」、そして確率が大きい方はどちらか表示されます。
・下準備
→分析に必要なライブラリをインストールします。
%%capture capt
# MeCabのインストール
!apt install mecab libmecab-dev mecab-ipadic-utf8
!pip install mecab-python3
# mecab-ipadic-NEologdのインストール
!apt install git make curl xz-utils file
!git clone –depth 1 https://github.com/neologd/mecab-ipadic-neologd.git
!echo yes | mecab-ipadic-neologd/bin/install-mecab-ipadic-neologd -n -a
# 参考記事: https://qiita.com/Fulltea/items/90f6ebe6dcceaf64eaef
# 参考記事: https://qiita.com/SUZUKI_Masaya/items/685000d569452585210c
!ln -s /etc/mecabrc /usr/local/etc/mecabrc
# 参考記事: https://qiita.com/Naritoshi/items/8f55d7d5cce9ce414395
# 感情分析のためのライブラリ
!pip install -q asari oseti pymlask
# asari==0.0.4 requires Janome==0.3.7
# see https://github.com/Hironsan/asari/issues/9#issuecomment-695706645
!pip install Janome==0.3.7
・センチメント分析対象の文章を作成
→変数list_textに格納します。今回の例でいうと、5つの文章がそれぞれ分析対象になります。
list_text = [
‘この人は、この世の中で、いちばんしあわせな人にちがいありません。’,
‘芝居小屋もすばらしいし、お客さんもすばらしい人たちでした。’,
‘もし中世の時代だったら、おそらく、火あぶりにされたでしょうよ。’,
‘みんなのうるさいことといったら、まるで、ハエがびんの中で、ブンブンいっているようでした。’,
‘われわれ人間が、こういうことを考えだすことができるとすれば、われわれは、地の中にうめられるまでに、もっと長生きできてもいいはずだが’
]
・センチメント分析
→いよいよ分析結果が出ます。asariからSonarインスタンス関数を呼び出し、.pingメソッドでセンチメント分析を行います。
%%capture capt
from asari.api import Sonar
sonar = Sonar()
list(map(sonar.ping, list_text))
[参考記事]
>> Python で日本語文章の感情分析を簡単に試す (with google colab)
[結果]
[{‘classes’: [{‘class_name’: ‘negative’, ‘confidence’: 0.10382535749585702},
{‘class_name’: ‘positive’, ‘confidence’: 0.896174642504143}],
‘text’: ‘この人は、この世の中で、いちばんしあわせな人にちがいありません。’,
‘top_class’: ‘positive‘},
{‘classes’: [{‘class_name’: ‘negative’, ‘confidence’: 0.035517582235360945},
{‘class_name’: ‘positive’, ‘confidence’: 0.964482417764639}],
‘text’: ‘芝居小屋もすばらしいし、お客さんもすばらしい人たちでした。’,
‘top_class’: ‘positive‘},
{‘classes’: [{‘class_name’: ‘negative’, ‘confidence’: 0.5815274190768989},
{‘class_name’: ‘positive’, ‘confidence’: 0.41847258092310113}],
‘text’: ‘もし中世の時代だったら、おそらく、火あぶりにされたでしょうよ。’,
‘top_class’: ‘negative‘},
{‘classes’: [{‘class_name’: ‘negative’, ‘confidence’: 0.2692695045573754},
{‘class_name’: ‘positive’, ‘confidence’: 0.7307304954426246}],
‘text’: ‘みんなのうるさいことといったら、まるで、ハエがびんの中で、ブンブンいっているようでした。’,
‘top_class’: ‘positive‘},
{‘classes’: [{‘class_name’: ‘negative’, ‘confidence’: 0.050528495655525495},
{‘class_name’: ‘positive’, ‘confidence’: 0.9494715043444746}],
‘text’: ‘われわれ人間が、こういうことを考えだすことができるとすれば、われわれは、地の中にうめられるまでに、もっと長生きできてもいいはずだが’,
‘top_class’: ‘positive‘}]
それぞれの文において、
{classesタプル[{ネガティブ, ネガティブである確率},{ポジティブ, ポジティブである確率}], 対象テキスト, 確率が高いもの}
の形式で分析結果が表示されていることが分かります。確率が高いもの(→センチメント分析システムの最終判断)を太字で示しました。
しかし、このデータセットにおいて例えば4つ目の「みんなのうるさいことといったら、まるで、ハエがびんの中で、ブンブンいっているようでした。」は、ネガティブな文章のように見えますが今回「Positive」判定を受けており、分析精度についてはまだまだ不安定な所があるようです。
このようにして、センチメント分析では文章が持つ感情を判断することが可能です。
クラスター分析
クラスター分析は、各個体の複数種類のデータ(例:人間各個体の「身長」「体重」「年齢」「居住地域」)から似ている性質の個体を発見しグルーピングする統計学的手法です。
例えばクラス全員分のテスト結果をクラスター分析すると、理系科目が得意なクラスター(集団)、文系科目が得意なクラスター(集団)のような出力が得られることが多いです。
また、クラスター分析には2種類、「階層的クラスタリング」と「非階層的クラスタリング」があります。
「階層的クラスタリング」は、最初全体で「性質の差について、最も2つに分けられそうなもの」を探して全体を分割し、その後分割されたグループ単位で同じことを繰り返していく(分割法)かあるいは、サンプルを個々をそれぞれ1つのクラスターと見て、性質的距離の近いものからくっついていって最終的に1つになる(凝集法)手法の2種類が存在します。
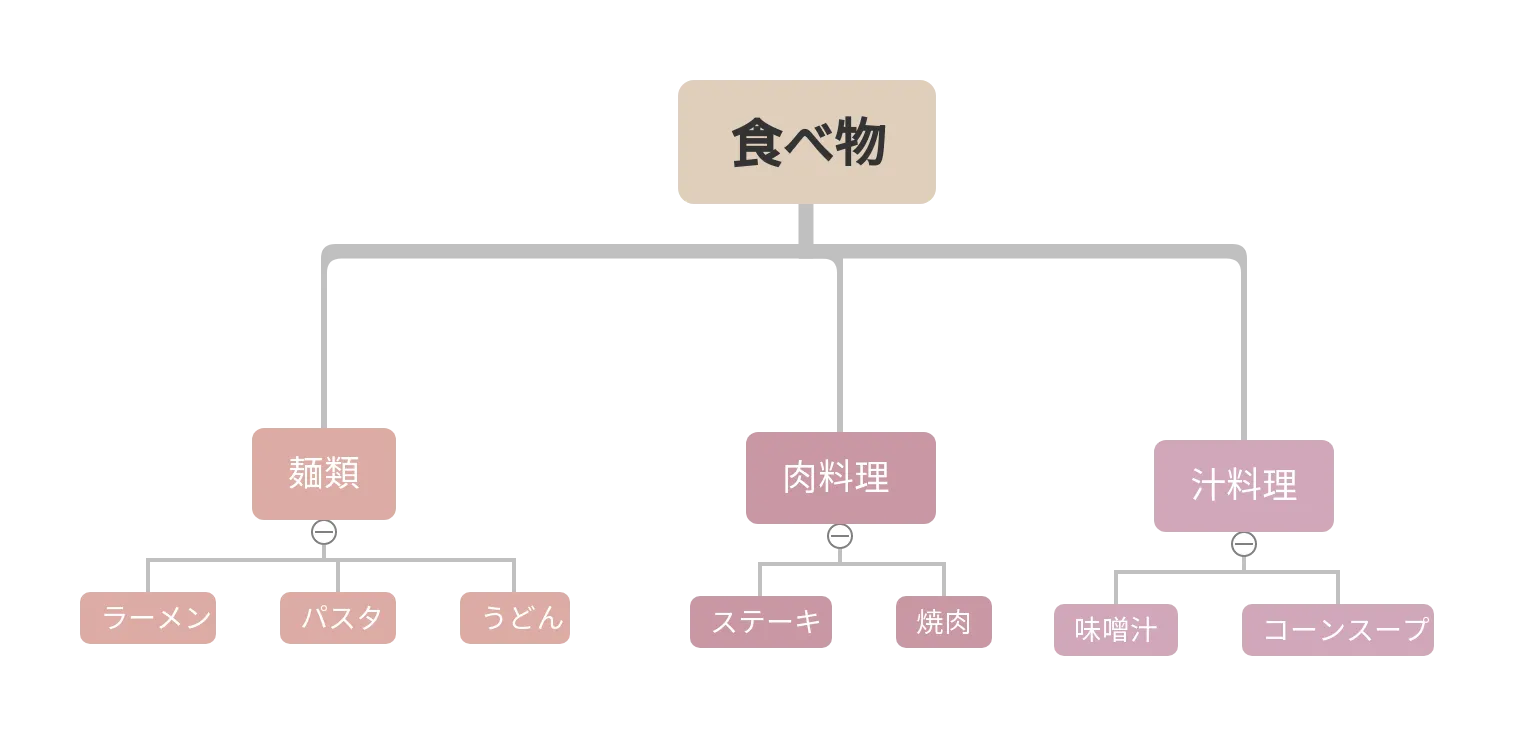
例として以上の食べ物に関するクラスター関係図(デンドログラム)を挙げますが、「食べ物」から始めて「麺類」や「味噌汁」にクラスターを分割していく手法が「分割法」、「ラーメン」や「コーンスープ」という小さなクラスターを近いもの同士組み合わせ続けて最終的に1つのクラスターにする手法が「凝集法」です。
一方、「非階層的クラスタリング」はこのような方法はとらず、予め決めたグループ数に準じた分け方を探して全体を一気に分割します。
そして今回は「階層的クラスタリング(凝集型)」をPythonで実行します。
1. Google Drive接続~下準備
今回はGoogle Colaborateで実行し、データをcsvファイルから取り入れるため、以下のようにしてまずGoogle Driveに接続します。
from google.colab import drive
drive.mount(‘/content/drive’)
必要なモジュールをインポートし、ドライブからデータを取り込みます。
import numpy as np
import pandas as pd #データ構造取扱モジュール
import scipy.cluster.hierarchy as sch #クラスター分析のためのモジュール
import matplotlib.pyplot as plt #グラフ描画
from sklearn.cluster import AgglomerativeClustering #モデル学習のためのモジュール
df = pd.read_csv(“/content/drive/MyDrive/sample_data (2).csv”) #データ取り込み
print(df.tail(20)) #20個、データを見てみる
【結果】
今回は、以下のように各個人(計100人)について「性別」「年齢」「職業」「年収」「マンション家賃」の情報を持つデータセットを利用します。
性別 年齢 職業 年収[万円] マンション費用[万円/月]
80 男 46 芸能関係 577 9
81 女 48 商社 577 7
82 女 57 医療関係 577 6
83 女 38 公務員 577 6
84 男 49 商社 650 8
85 女 59 医療関係 580 11
86 女 40 医療関係 580 12
87 男 45 公務員 900 33
88 女 40 マスコミ 700 20
89 男 27 IT関係 800 15
90 男 55 IT関係 1000 38
91 男 50 芸能関係 1100 26
92 男 34 政治家 1200 40
93 男 68 金融機関 990 35
94 男 40 IT関係 780 20
95 男 32 商社 700 19
96 男 47 自営業 830 35
97 女 48 政治家 950 29
98 女 48 商社 900 33
99 女 29 製造業 1000 20
2. デンドログラム描画
次に、「デンドログラム」といういわゆる樹形図に近いものを描画します。
なお、今回のデータは各個人の「職業」「年齢」「家賃」「年収」「マンション家賃」の情報が入っているので、「年収」と「マンション家賃」に特に注目して凝集型クラスター分析を行います。
結果としてトーナメント表のようなデンドログラムが完成しますが、下から上に向かってクラスターのサイズが大きく、数が少なくなっていく様子が視覚的に分かるようになっています。
#クラスタリング軸設定(年収vsマンション費用)
X = df.iloc[:, [3, 4]].values
#樹形図作成用インスタンス
dendrogram = sch.dendrogram(sch.linkage(X, method = ‘ward’))
#樹形図可視化
plt.title(‘Dendrogram’)
plt.xlabel(‘Salary vs Apartment Cost’)
plt.ylabel(‘Euclidean distances’)
plt.show()
[結果]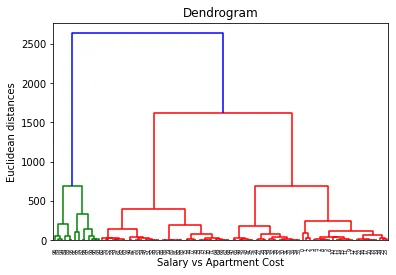
横軸に平行な直線(縦軸の値をAとする、Aは任意)を引いた時のデンドログラムとの交点の数が、縦軸の値=Aの時のクラスター数を表しています。例えば、縦軸の値(クラスタリングの程度)が1500の時のクラスター数は、交点の数=3個です。今回はクラスター数を5個にしてクラスター分析を行おうと思います。
3. モデル学習、クラスター表示
# モデル訓練
hir_clus = AgglomerativeClustering(n_clusters = 5, affinity = ‘euclidean’, linkage = ‘ward’)
y_hir_clus = hir_clus.fit_predict(X)
前回、クラスター数を5でクラスター分析をすると決めたので、今回のモデル学習(機械にデータを与え、パターンを学習させる)のパラメーター「n_clusters」を5に設定しました。なお、「affinity」は距離、「linkage」はクラスター結合方法を意味するパラメータです。
import numpy as np
import matplotlib.pyplot as plt
from matplotlib import cm
# クラスターの配列情報
cluster_labels = np.unique(y_hir_clus) # 一意なクラスター要素
n_clusters = cluster_labels.shape[0] # 配列の長さ
# クラスター可視化
for i in range(len(cluster_labels)):
color = cm.jet(float(i) / n_clusters) #クラスター別に色指定
plt.scatter(X[y_hir_clus == i, 0], X[y_hir_clus == i, 1], s = 50, c = color, label = ‘Cluster’+str(i)) #散布図描画
plt.title(‘Clusters of customers’) #タイトル、ラベル等指定
plt.xlabel(‘Salary’)
plt.ylabel(‘Apartment Cost’)
plt.legend(loc=”best”)
plt.show()
最後にクラスター別に色付けして散布図を表示します。この作業を行うことで、クラスター分類が上手くいったかどうか判別することが可能です。
[結果]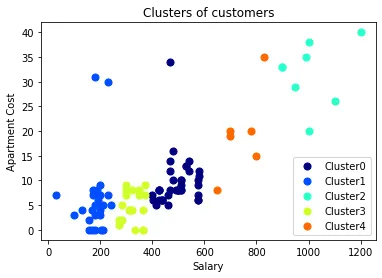
横軸が収入、縦軸が家賃です。デンドログラムによって綺麗に別れる個数を調べた甲斐があり、クラスターごとに集団が別れて固まっているように見受けられます。綺麗に上手く分類することが出来ました。
[コード引用]
>> 階層的クラスタリング、モデル学習
主成分分析
主成分分析とはクラスター分析と同様のデータに対して、似ている性質を持つ「変数」がないか分析し、それらをまとめて表す新たな「変数」を作成する統計学的手法です。主成分分析をすることで、より少ない変数でデータを扱うことが可能になります。
では、まず主成分分析を行うコードを解説します。
モジュールのインポート
import numpy as np #データ構造を扱うためのモジュール
from matplotlib import pyplot as plt
%matplotlib inline #データ・分析結果可視化モジュール
データの読み込み
今回は以下のような不動産データを扱います。
# 名前
# 家賃(~5万:1, 5~7万:2, 7~9万:3, 9~11万:4, 11万~:5)
# 建物面積(~50m^2:1, 50~75m^2:2, 75~100m^2:3, 100~125m^2:4, 125m^2~:5)
# 土地面積(~50m^2:1, 50~75m^2:2, 75~100m^2:3, 100~125m^2:4, 125m^2~:5)
# 築年数(~5年:1, 5~10年:2, 10~15年:3, 15~20年:4, 20年^:5)
data = np.array([
[‘house-A’,3,5,4,3],
[‘house-B’,3,4,4,2],
[‘apartment-A’,1,2,2,5],
[‘apartment-B’,3,2,2,4],
[‘house-C’,4,3,3,3],
[‘apartment-C’,3,2,3,4],
[‘house-D’,5,5,5,2],
[‘apartment-D’,4,2,1,5],
[‘apartment-E’,3,3,2,5],
[‘house-E’,5,5,4,2],
])
d = data[:,1:].astype(np.int64) #型変換
X = (d – d.mean(axis=0)) / d.std(ddof=1,axis=0) #データを標準化
XX = np.round(np.dot(X.T,X) / (len(X) – 1), 2) #相関行列表示
print(XX)
【結果】
#相関係数行列
[[ 1. 0.55 0.46 -0.6 ]
[ 0.55 1. 0.87 -0.82]
[ 0.46 0.87 1. -0.91]
[-0.6 -0.82 -0.91 1. ]]
相関行列まで算出してみました。
ここで、主成分分析の流れは以下のようになることを確認して下さい。
- データ読み込み
- 相関行列確認
- 固有値・固有ベクトル算出
- 主成分数選択
- 主成分分析
- グラフ可視化
現在は2の「相関行列」まで求め終わっています。「相関行列」とは、要素の組み合わせごとの相関係数(比例の度合い)を行列の形式で並べたものですが、この相関行列の「固有値」「固有ベクトル」を求めることで主成分分析をすることが可能です。具体的には、各要素のばらつき(分散)が最大になるように新たな軸(→主成分)を作ることが主成分分析ですが、この主成分を求めることと相関行列の固有値を求めることが同値であるので以上のような手法が取られています。
主成分分析
# 相関行列の固有値、固有値ベクトルを求める
w, V = np.linalg.eig(XX)
# 第1主成分を求める
z1 = np.round(np.dot(X,V[:,0]),1) * -1
# 第2主成分を求める
z2 = np.round(np.dot(X,V[:,1]),1)
結果をグラフ表示
# グラフ用オブジェクトの生成
fig = plt.figure(figsize=(12, 8))
ax = fig.add_subplot(111)
# グリッド線を入れる
ax.grid()
# 描画するデータの境界
lim = [-2.5, 2.5]
ax.set_xlim(lim)
ax.set_ylim(lim)
# 左と下の軸線を真ん中に持っていく
ax.spines[‘bottom’].set_position((‘axes’, 0.5))
ax.spines[‘left’].set_position((‘axes’, 0.5))
# 右と上の軸線を消す
ax.spines[‘right’].set_visible(False)
ax.spines[‘top’].set_visible(False)
# 軸の目盛の間隔を調整
ticks = np.arange(-2.5, 2.5, 0.5)
ax.set_xticks(ticks)
ax.set_yticks(ticks)
# 軸ラベルの追加、位置の調整
ax.set_xlabel(‘Z1’, fontsize=16)
ax.set_ylabel(‘Z2’, fontsize=16, rotation=0)
ax.xaxis.set_label_coords(1.02, 0.49)
ax.yaxis.set_label_coords(0.5, 1.02)
# データのプロット
for (i,j,k) in zip(z1,z2,data[:,0]):
ax.plot(i,j,’o’)
ax.annotate(k, xy=(i, j),fontsize=16)
# 描画
plt.show()
[参考記事]
>> Qiita-Python主成分分析
[結果]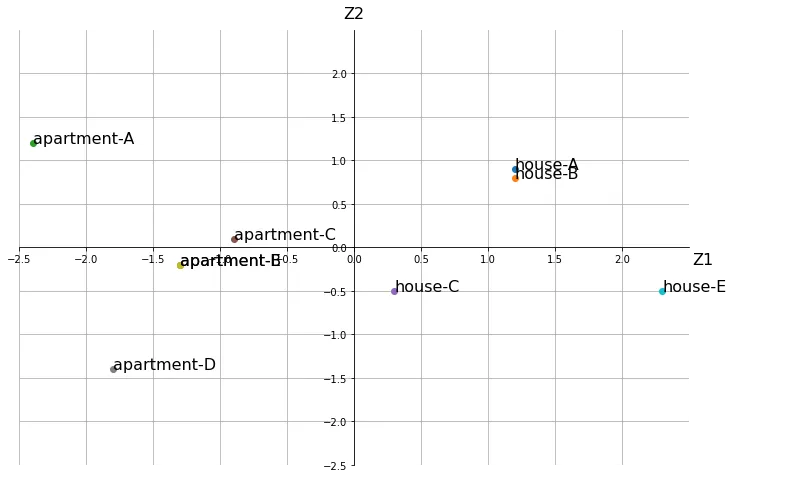
結果的に以上のような散布図が得られました。元々は5つも変数を持っていましたがこの操作により変数を2つにし、散布図として視覚的に状況が分かるようになりました。基本的には第1主成分がデータの総合指標を表すようになっているので、今回5つの指標があった不動産について、house-Eが最もパフォーマンスの高い物件であることがここから分かります。
ワードクラウド
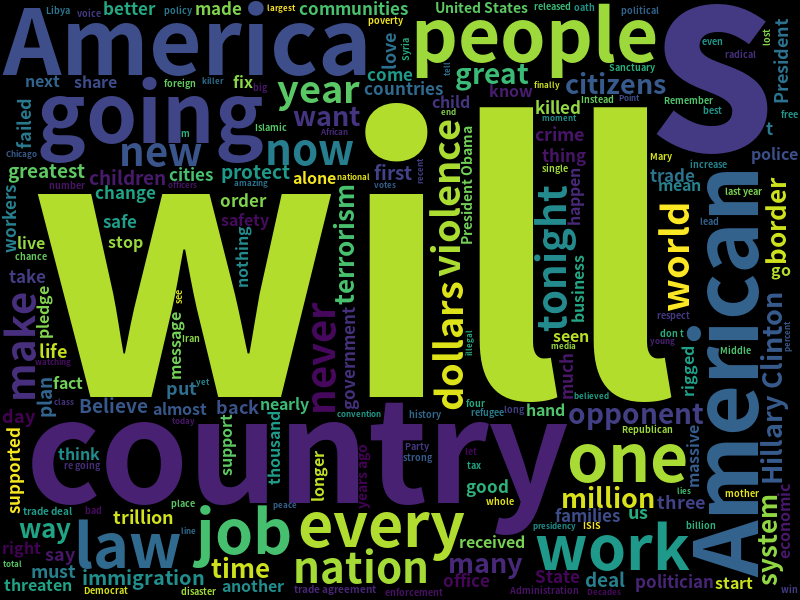
ワードクラウドは、文章内での単語の出現回数をもとに、重要な単語を色や大きさを用いて主張した図を作成することです。
(以下作成した図(背景黒))コードを付きでご紹介します。
実行方法
- モジュール「wordcloud」をインストール
- モジュールのimport
- テキストマイニングしたい文章の読み込み
- ワードクラウドの作成
インストール
コマンドプロンプト、端末、ターミナルなどで下記を入力pip3 install WordCloud
インポートfrom wordcloud import WordCloud
テキストファイルの読み込みtext_file = open(“test.txt”) #test.txtは入力テキストファイルのパス textdata = text_file.read()#テキストの読み込み
ワードクラウドの作成wordcloud = WordCloud(background_color=”white”, font_path=”C:\Windows\Fonts”,#windowsの場合 (/usr/share/fonts)#ubuntuの場合 width=1200,height=900).generate(textdata)wordcloud.to_file(“./sample.png”)
上から順に背景色(白)、フォント(HelveticaNe)、画像サイズ(横1200、縦900)を指定しています。
最後に./sample.pngに出力しています。
今回入力は、トランプ前大統領の就任演説です。こちらから見れます。
以下出力(背景 白)
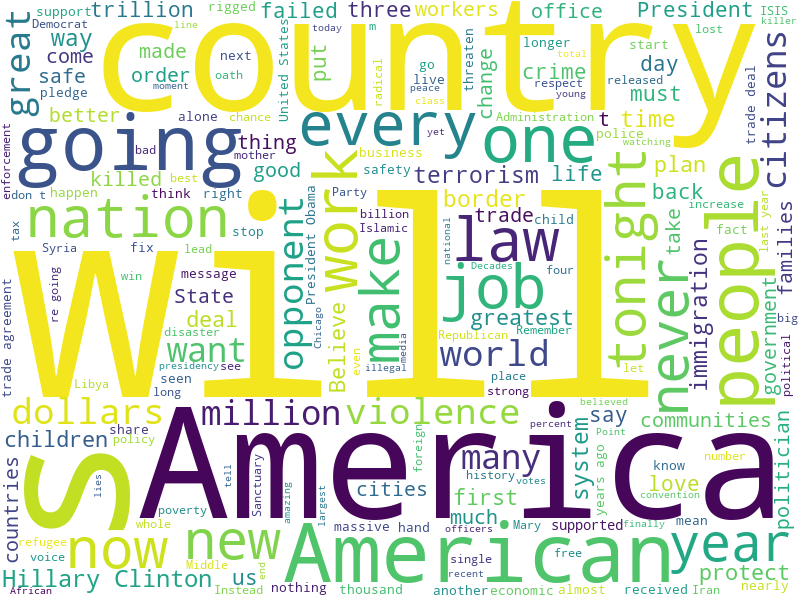
「アメリカ」という単語が目立ちますね。トランプ前大統領が主張していたアメリカファーストが見て取れます。
日本語の場合は形態素解析で紹介したMeCabなどを用いて「分かち書き」を行い「*」などを「スペース」に変更して入力することでwordcloudを作成できます。
このようにテキストマイニングを行いワードクラウドを作成することで、視覚的に重要な単語、内容を確認することができます。
以上でPythonによるテキストマイニングの紹介は終わります。
最後まで読んで頂きありがとうございました!
クリスタルメソッド公式note:https://note.com/crystalmethod/
X:https://x.com/YCrystalmethod
YouTube:https://www.youtube.com/@haltalktube
TikTok:https://www.tiktok.com/@crystalmethod.jp
Study about AI
AIについて学ぶ
-

営業ロープレをAI化するメリットとは?課題をまとめて解決します
「営業ロープレをもっと効率的にできないか」という声は、営業責任者や研修担当者から絶えず聞かれます。ロープレは営業スキル向上に効果的な手法である一方、「相手の確保...
-

AIロープレとは?営業・接客・面接練習での活用法を解説します!
人手不足が深刻化し、新人教育の「早期戦力化(イネーブルメント)」が企業の最重要課題となる中、教育現場に破壊的なイノベーションが起きています。 従来のコミュニケー...
-

AIロープレツールの選び方|比較ポイントと主要ツール比較を解説
「AIロープレを導入したいが、どのツールを選べばいいかわからない」という声をよく聞きます。AIロープレツールは種類が増えており、対応している業種・機能・価格もさ...