blog
AIブログ
テキストマイニングとは?やり方やツールまで解説
テキストマイニングという言葉をご存じでしょうか?
テキスト=文字列を対象に分析することを指しますが、「ただ文章を分析するだけなの?」「人間でもできることなんじゃないの?」「どの程度の精度なの?」と疑問に感じる方もいらっしゃるかもしれません。
この記事では、AIの受託開発企業のコンピュータの専門家が、テキストマイニングの意味ややり方、無料で利用できるツール等についてわかりやすく解説していきます。
極力専門用語を使わず、初心者の方にもわかりやすくテキストマイニングについて解説しますので、ぜひ最後まで目を通していただければ幸いです。
テキストマイニングとは?
テキストマイニング(text mining)とは、テキスト(text:文章)とマイニング(mining:採掘)を合わせた造語です。
膨大なテキストの山を分析し、貴重な情報をマイニングする(掘り当てる)という意味で近年、自然言語処理の分野で非常に注目されているHOTな技術分野です。
詳しく説明すると、構造化されていない大量のテキストデータを様々な属性に特定できるソフトウェアにより分析するプロセスのことです。
また、テキストマイニングはテキスト分析とも呼ばれますが、この二つの用語を分ける人もいます。その場合、テキスト分析はテキストマイニングの技術を使用し、データを分類するアプリケーションのことを言います。
自然言語処理とは何か?詳しく知りたい方はこちらの記事で詳細に解説していますので、是非ご覧ください。
>>自然言語処理(NLP)とは?AI技術自然言語処理方法解説
テキストマイニングとデータマイニング
テキストマイニングと似た言葉の1つとして「データマイニング」があります。
データマイニングは主に顧客情報などの分析などに使われるツールであるのに対し、テキストマイニングはテキストデータの中から有益そうな言葉を掘り出し、企業の今後の方針の決定や問題改善などに用いられるツールとして使われています。データマイニングでは、対象となるデータはほとんどが数値など量的に表すことのできるものでした。量的に表すことができるデータであれば、数値計算が得意な機械が扱える領域の話であるため、人間があえて行うことではなかったのですが、自然言語で書かれた文章の分析は機械にとっては分類しづらく、不得意な領域でした。
ところが今回のトピックの題にもあるように、近年、機械が自然言語を把握し分析する能力を持つようになりました。
これまで分析することが難しかった問い合わせフォームなどで収集した顧客のコメントや、SNSへの投稿を分析することができるようになります。これまで人の目で確認しなければならないほどバリエーションのあるコメントから、「満足した」「不満だった」「気に入らなかった」などという言葉をマイニングし、分析することで、容易に今後どのように改善していくかを判断することができるようになります。ウェビナーなどでも使われることが増えていくかもしれません。
昨今のAI技術の発展により、一度に大量のテキストデータを、より高精度に分析することができるようになったことで、テキストマイニング分野の盛り上がりは拍車をかけています。
テキストマイニング手法の分類
テキストマイニングの分析手法はセンチメント分析、共起分析、対応分析、主成分分析の4つの方法に分けられます。それぞれの分析手法について解説します。
◆センチメント分析
センチメント分析とは、sentiment(感情)を分析する手法です。レビューや感想などが、ポジティブなものかネガティブなものかを判断することができます。またTwitterなどのSNSの投稿についても活用されています。
◆共起分析
共起分析とは、ある単語が別のある単語と一緒に使用される度合いを分析する手法です。具体的には、「みかん」に対する「あまい」「すっぱい」など単語の組み合わせを分析することで、みかんの強み・弱みを分析することができます。
◆対応分析
対応分析とは、別々の結果を一緒にまとめて表すことで関係性を分析する手法です。例えば自社と複数の他社のブランドの特徴を散布図にすることで、各社の特徴を比較、分析することができます。
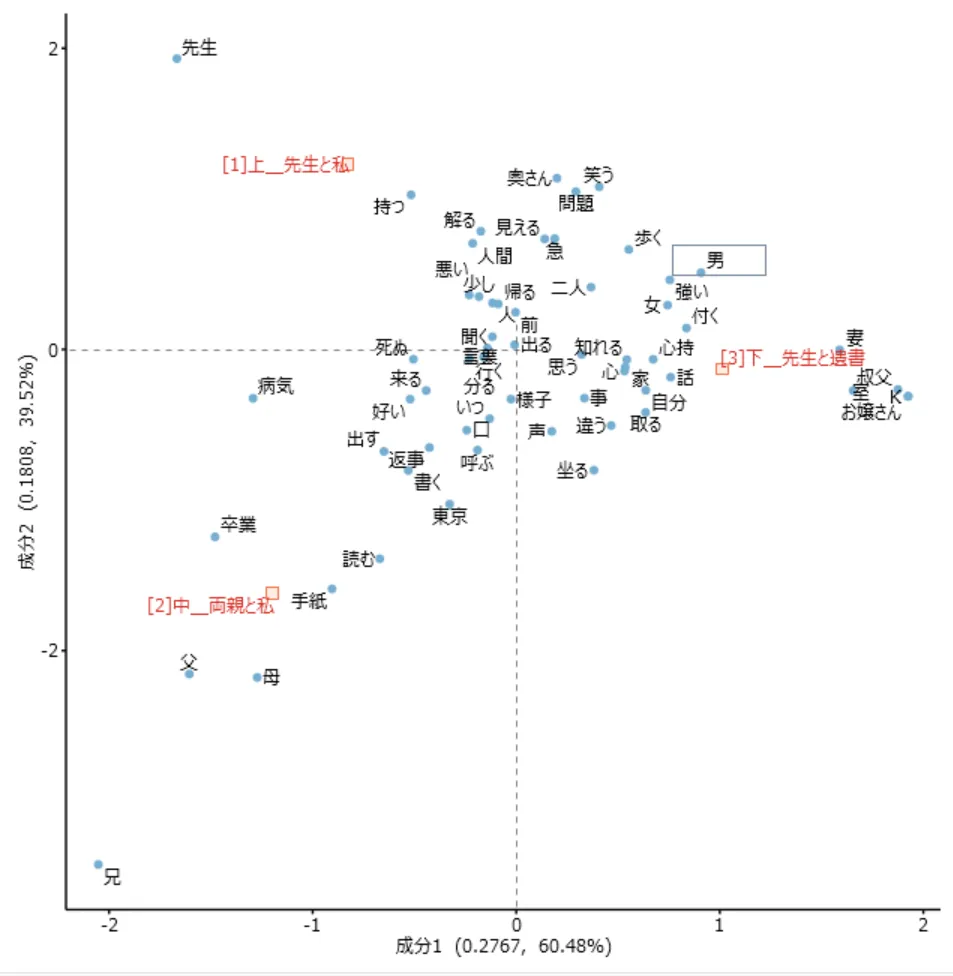
例として小説「こころ」の各章を象徴する特徴語となる単語の対応分析の図を示します。
原点(0, 0)から見て、「上_先生と私」などの各章の方向にあって、原点に近いと意味ない言葉、原点から離れている語ほど、その章を強く特徴する単語となっています。
◆主成分分析
主成分分析とは、膨大なデータを分析する際、いくつかの項目でデータで擬似的に簡易表現する分析手法です。データ量を減らすことで分析しやすくなる反面、一部の情報を切り捨ててしまいます。例えば、Webページ内容を評価する際に、閲覧数、文字数、画像枚数のみに着目すれば分析しやすくなります。しかし、モバイルに対応しているかどうかなどの考慮すべき情報が落ちてしまう可能性があり、注意が必要です。
代表的な分析手法
具体的な分析手法として、主成分分析のひとつであるTF-IDFとLDAを紹介します。
TF-IDF
TF-IDFはTFとIDFという単語にわけられます。TFはTerm Frequencyの略で、文書中の「ある単語」が「どれくらい多い頻度で出現するか」を表し、IDFはInverse Document Frequencyの略で「(逆に)どれくらい少ない頻度で存在するか」を表します。
TF値の意味
一つの文章の中の特定の種類の単語を一つの文章全体の単語の種類数で割った値をTFとします。このようにして文章の中の頻出単語を抽出し文章の単語による特徴を把握していきます。
TF値の計算式
ある文書djに出現する単語tiについて考える場合、出現回数を表す関数をfとするとTF値は以下の式のようになります。TF値は文書、単語ごとに定義されるので、同じ単語であっても文書が異なる場合は、値が一致するということではありません。

出現回数が多いほどTF値は大きくなり,出現回数が低いほどTF値は小さくなります.
ここまでの話から,単純に文書内にたくさん出現している単語ほど,その文書をよく表しているといったことになりそうですが、そのようなわけではありません.例えば、日本語の中でよく含まれているような助詞の「の」のような単語は抽出して文章を特徴づけてもあまり意味が無いということが分かるでしょう。
そこで,「その単語が他の文書にはないレアな単語である」ことを表すIDF値が重要となります。
◆IDF値の意味
次にIDFの説明をします。IDFは逆に文字の多さではなく文字のレアリティに注目します。IDF値は文書集合の中のある単語が含まれる文書の割合の逆数を表します.単語が他の文章にも多く出現しているほどIDF値は小さくなり,単語が他の文章にあまり出現していないほどIDF値は大きくなります。

◆IDF値の計算式
ある文書集合における単語tiについて考える場合,dfを単語tiが出現する文書数とすると,IDF値は以下の式から計算できます.TF値と違い,IDF値は単語ごとに存在することに注意が必要です.TFと同様にIDFの値を数式として表すと
のようになりますが、文書内に一度も出現しない単語のIDF値を計算しようとした場合,0除算(division-by-zero)が発生してしまう.そのため,分母に+1を追加した以下の式を使用するのが一般的です。

そしていよいよTF-IDFの紹介に入ります。
◆TF−IDF値の意味
TF-IDF値はTF値とIDF値をかけ合わせて計算します。このようにすることで、ある文書内での出現回数は多いが他の文書には出現しない単語のTF-IDF値は大きくなり、それ以外の単語についてはTF-IDF値は相対的に小さくなります。上記で算出したTF値とIDF値をかけ合わせることで,単語毎の重要度を算出し、文章の中から文章の特徴と成る単語を抽出しつつ、その抽出した単語が特徴になりえないようなありふれた単語であるということを防ぐ、という作業を行います。またTF-IDF値は文書ごと,単語ごとに存在します。
TF-IDFの計算は以下のようになります。
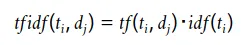
LDA
LDAは「Latent Dirichlet Allocation」の略称で、日本語では「潜在的ディリクレ配分法」と言います。具体的にはLDAは文章を、その文章が含む単語の内容をつかむことで文章全体のトピックを決める方法です。
例えば分類分けをしてしまうと、「C.ロナウド、世界で最も稼いだアスリート」と言うような記事があった時、この記事は「スポーツ」と「経済」どちらかしか含まれませんが、LDAはこのような場合でも「スポーツ」、「経済」のトピックを記事に付与することによってどちらの可能性も損ないません。
みなさんが使っているようなニュースサイトでも「経済のニュース」、「スポーツのニュース」、「芸能のニュース」というようなそれぞれのトピックの内容を適切に読者に伝えるためにもこのようなアルゴリズムが裏で活用されています。
テキストマイニングのやり方
ここでは、テキストマイニングのやり方についてわかりやすく解説します。
テキストマイニングは以下の順序で行います。
1.データの前処理
コンピューターが解析できるように、文章を単語ベースに分けるなど前処理(自然言語処理)を行います。
2.分析・解析
前処理(自然言語処理)を施したデータをもとにテキストマイニングの目的に合わせた手法で分析、解析を行います。
3.可視化
分析したデータを人が視覚的に把握できるようにするため、ワードクラウドを作成するなどします。
以下がデータを可視化した例です。

上で述べた前処理(自然言語処理)に用いられる主な解析方法には形態素解析、構文解析、意味解析、文脈解析があります。
自然言語処理についてより詳しく知りたい方は自然言語処理(NLP)とは?|クリスタルメソッドをご覧下さい。
また、上で述べたテキストマイニングの目的に合わせた解析、分析手法については以下でわかりやすく解説します。
日本語の構文解析
◆CaboCha
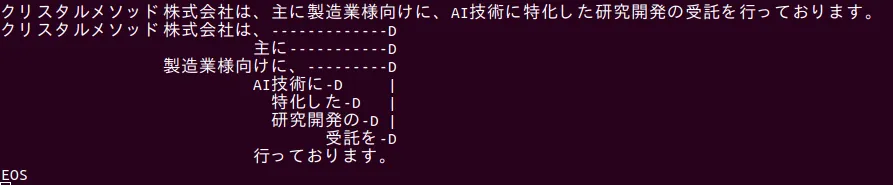
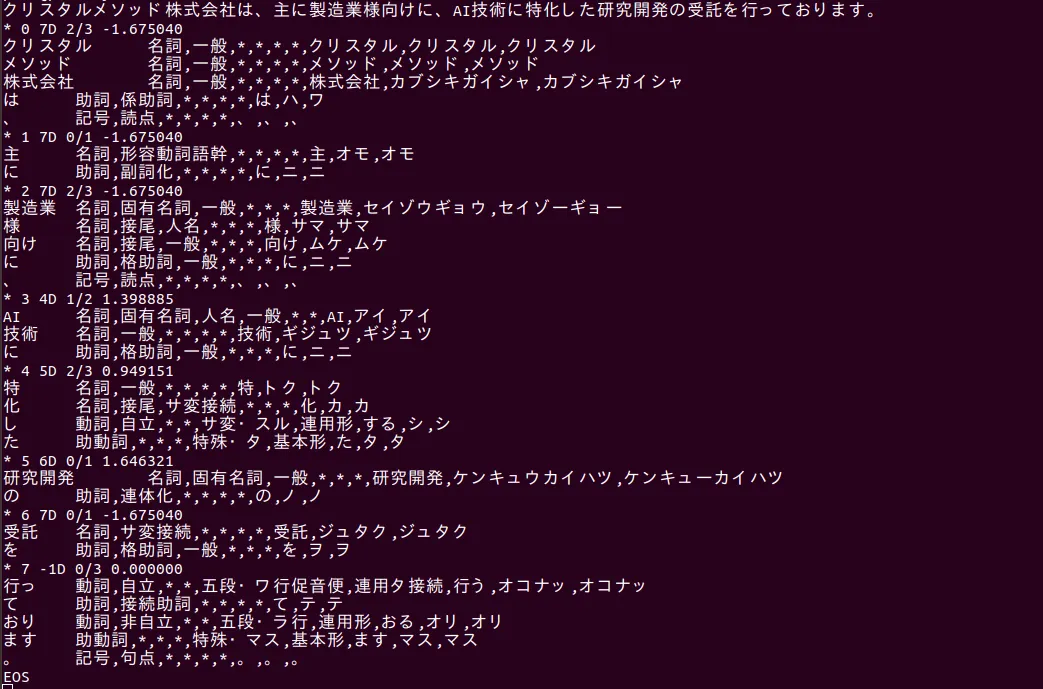
形態素解析、構文解析、意味解析、文脈解析すべてを行ってくれるのが、CaboChaというツールです。南瓜(CaboCha)は、工藤拓氏と松本裕治氏により開発されました。CaboCha は, Support Vector Machines に基づく日本語係り受け解析器で、フリーソフトウェアとなっています。係り受け解析器というのは文章を形態素に分けた後に、単語間の修飾関係を解析することです。SVMとは、機械学習アルゴリズムの一つ。高精度のデータ分類ができると言われているものです。C/C++/java/python/ruby/perlのインターフェースが提供されています。
CaboCha|南瓜からインストールを行うことができます。
実際に使ってみると以下のようになります。
◆JUMAN/KNP
KNPは、京都大学のJUMANをベースとした係り受け関係による構文解析器であり、1993年に公開がされたものです。KNPは日本語文の構文・格・照応解析を行うツールとなっており、形態素解析ツールJUMANの解析結果(形態素列)を入力として、文節および基本句間の係り受け関係、格関係、照応関係をアウトプットしてくれます。
KNPを試してみる
簡単に試すことができます。

と出力をしてくれます。
テキストマイニングツール・機能
テキストマイニングは主に企業がデータ解析のために使われますが、紹介したKHcoderは、個人でも簡単に使えて様々な文章解析ができそうな気がしますよね。
無料で使えるテキストマイニングソフトのKH Coder以外にも、より簡単にiPhoneなどスマホでマイニングを行う機能を持ったアプリや、GoogleのNatural Language APIのようなツールはより実践的な解析を行えるソフトウェアもあります。
◆Googleの構文解析
Natural Language APIでは表のような「感情分析」、「エンティティ分析」、「エンティティ感情分析」、「コンテンツ分類」、「構文分析」を利用することができます。
| 分析項目 | 分析内容の概要 |
|---|---|
| 感情分析 | 文章が「ポジティブ」か、「ネガティブ」か、「ニュートラル」(普通の状態)か分類します。 |
| エンティティ分析 | 指定されたテキストに既知の固有名詞や普通名詞が含まれているかどうかを調べて、その名詞に関する情報を返します。 |
| エンティティ感情分析 | エンティティ分析をし、テキスト内でのその名詞の感情的を分析します。また、そのエンティティに対する執筆者の考え方がポジティブか、ネガティブか、ニュートラルかを判断します。 |
| 構文解析 | 言語情報を抽出し、指定されたテキストを一連の文とトークン(通常は単語の境界)に分解して、それらのトークンをさらに分析できるようにします。 |
| コンテンツ分類 | テキストをコンテンツカテゴリに分類します。 |
Natural Language APIを利用してサービスを行うことも可能です。
web上などで行ったアンケートを分析する際に、否定的な意見と、肯定的な意見に分類することができるため、自社の製品やサービスの向上をすることが楽になります。
また、Natural Language APIを利用した、Dialogflowと呼ばれるサービスをgoogleは提供しており、簡単にチャットボットを作成することも可能となっています。
◆エラスティックサーチ
エラスティックサーチ(Elasticsearch)とは、大量の文書データから任意のキーワードやフレーズで全文検索を行うことができるソフトウェアのことで、分散検索/分析エンジンで、Apache Lucene を基盤として構築されています。オランダのエラスティック(Elastic)社が開発しています。
Elastic Cloudとは、Elastic社がAWSや「Microsoft Azure」「Google Cloud」などのパブリッククラウド上でエンタープライズサーチの機能などをマネージドサービスとして提供するサービスで、クラウドで利用することが可能です。
オープンソースとして公開されていましたが、現在は、プロプライエタリソフトウェアとなっています。
ログ分析、フルテキスト検索、セキュリティインテリジェンス、ビジネス分析、およびオペレーショナルインテリジェンスのユースケースなど、幅広く使用ができるようになっており、クラスタ構成と呼ばれる複数のコンピュータが連結をしているため、大規模なシステムでも利用を行うことができ、MySQL(RDBMS) 、Redshift(データウェアハウス)、DynamoDB(NoSQL)などと比べて、複雑な検索を高速に実行することができ、分析や検索用のデータを保管することが可能です。また、Elasticsearch は、Java、Python、PHP、JavaScript、Node.js、Ruby など、さまざまな言語をサポートしています。
このようなデータマイニングツールは簡単に導入できるものであり、企業はツールの使い方次第でより実践的に顧客の情報を収集・多くの分野で活用をすることができるようになるのです。
Pythonでのテキストマイニング
テキストマイニングを行う方法はいろいろありますが、その中でもおすすめなのが、Pythonを使う方法です。
その理由は充実しているモジュールにより、短いコードでテキストマイニングを行えるからです!
Pythonでテキストマイニングをするコードを以下で紹介しているのでぜひご参照ください。
>>Pythonでテキストマイニングをする方法を詳しく解説します!
以下のテキストマイニングの手法をご紹介しています。
- 形態素解析
- クラスター分析
- センチメンタル分析
- 主成分分析
- ワードクラウド
以下は、トランプ前大統領の就任演説を用いてワードクラウドを実際に作成したものです。

トランプ前大統領の就任演説は以下から確認できます。
トランプ前大統領の就任演説
「アメリカ」という単語が目立ちますね。トランプ前大統領が主張していたアメリカファーストが見て取れます。
日本語の場合は形態素解析で紹介したフリーソフトのMeCabなどを用いて「分かち書き」を行い「*」などを「スペース」に変更して入力することでwordcloudを作成できます。
このようにテキストマイニングを行いワードクラウドを作成することで、視覚的に重要な単語、内容を確認することができます。
エクセルでのテキストマイニング
ここまでご紹介したテキストマイニングですが、実はエクセルでもテキストマイニングができます。
エクセルでのテキストマイニングの手順
- 文章の単語化(形態要素分解)
- 単語を集計
- ワードクラウドを作る
文章の単語化
エクセル単体では、文章の単語化(形態素要素分解)を行う必要があります。
形態素解析を行うツールとしては、MeCabやJanomeなどのツールが有名です。
また、表記ゆれを統一することでより正確に解析できます。半角、全角 大文字、小文字 など 例)WEB web
単語を集計
文章を単語ごとに分割することで、単語の出現期数をカウントすることができるようになりました。
エクセル単体で出現回数をカウントするには「COUNTIF関数」を使います。
しかし、条件が複雑になったり、データ量が膨大だとエクセルの関数だけでは集計が困難になってきます。
このような場合は、エクセルと連動して利用できる集計用のソフトウェアを使うことができます。無料で使えるものもあります。
ワードクラウドを作る
テキストマイニング自体は完了していますが、次は人が視覚的に把握できるように頻出する単語を文字の大きさや色に反映してわかりやすくします。
テキストマイニングを無料で行いたい、エクセルでのテキストマイニングを実際に行いたい、より詳しくやり方を知りたいという方は以下の記事をご覧ください
>>【無料で行える】エクセルを使ったテキストマイニングのやり方とは?|クリスタルメソッド
また、エクセルでのテキストマイニングを行う外部サイトなどもありますので、そちらを活用してみるのもよいかもしれません。
テキストマイニング処理の事例

テキストマイニングは「データ収集」「データ前処理」「構造データ化」「加工・検討」の4ステップで行います。
夏目漱石の「こころ」を例に実際の処理の流れを説明していきます!
1. データ収集
データ収集のやり方は、まず分析するテキストが格納されているファイルを作成します。主にエクセルなどのファイルでダウンロード出来ることが多いですが、目的のWebページやアプリケーションによって取得方法は異なり、各々で調べる必要があり、場合によっては購入する必要があります。しかし昨今は無料で入手することができるフリーテキストがたくさんあるため、それを活用するのも良いでしょう。
今回は簡単のため、KH Coderのチュートリアルパッケージに含まれている「こころ」の文章ファイルを使用します。
2. データ前処理
次に収集したデータの前処理を行います。これにより日本語の複雑な文法を読み取って自動的に機械が扱いやすいような形へと処理できます。
今回はKH Coderをダウンロードした時に付属されるMeCabというソフトで形態素解析という分析を行います。
3. 構造データ化
非構造化データから構造化データに抽出しますが、これはMeCabで整えられた単語群を取得して個数を含む数値的な情報や単語動詞の位置関係の情報をKH Coderが受け取ります。
4. 加工・検討
最後に自分が把握したい情報を分析・可視化しやすくするために構造化データに変換し図示するようにします。
今回はKH Coderの共起ネットワークを表示する機能を用いて結果を視覚化します。共起ネットワークとはテキストマイニングされた語を以下のようにedge(線)で結ばれたnode(円)とした表現した図です。円の大きさは語の出現回数を示していて、同じ色の円は距離がその語動詞が近い抽出語同士であることを意味しています。
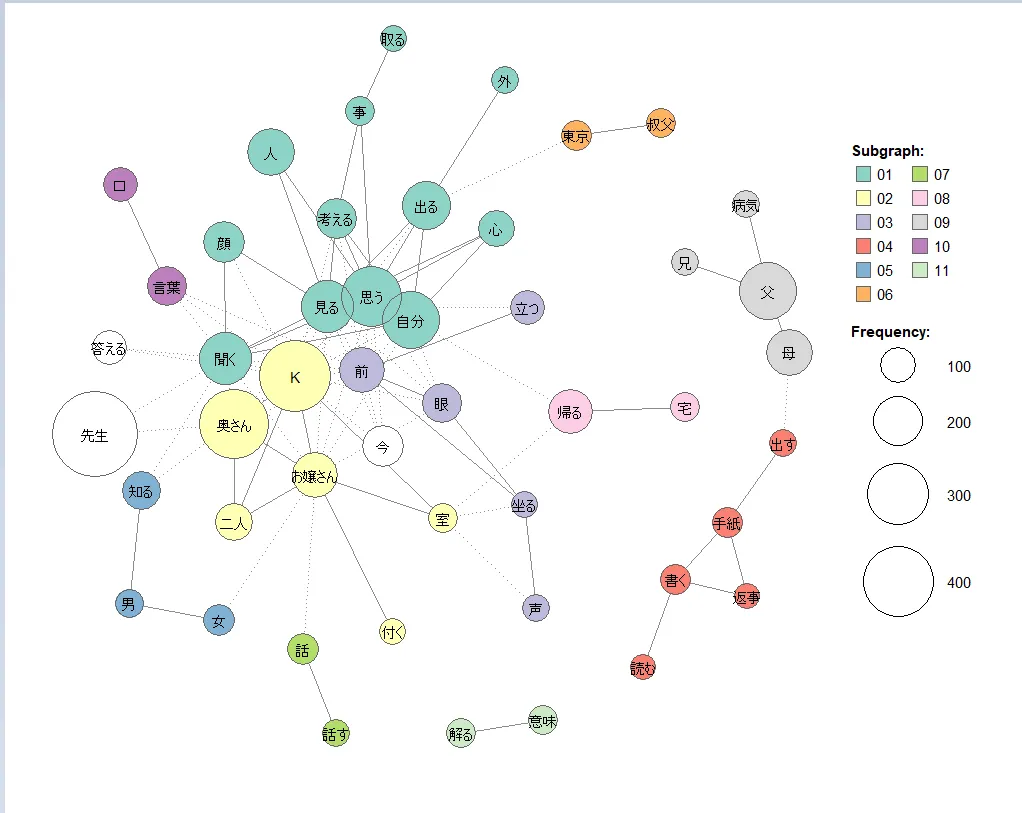
共起ネットワーク図から分かるように、「こころ」が一人称視点で描かれる作品であることより「自分」という語は大きくまた関連する語としては「見る」、「思う」といったような「自分」の中の心情描写に必要な意味を持った単語が多いことが分かります。また話の展開的に「K」が大きな円を描くことは想像しやすいのですが、「お嬢さん」ではなく「奥さん」が大きい円で、「K」との距離が近いというのは興味深い結果となったと思います。
「こころ」を題材に、テキストマイニングを紹介しましたが、流れを把握することはできたでしょうか?
実際にはデータの収集に手間取ったり、分析したデータをどのように加工して読み取るかなど、様々な点で工夫が必要で、欠点もまだ多く様々な企業・研究者が検証を重ねている最中なのです。今後の成長が大きく期待されています。
テキストマイニングについての実際の例について、もっと詳しく知りたい方はこちらをご覧ください。
>>テキストマイニングとは?実際の例について解説
テキストマイニングの歴史
今後が期待されるテキストマイニングですが、その歴史についても少しご紹介いたします。
テキストマイニングはもともと統計学などを利用してデータを分析するデータマイニングから派生したものです。そのため、データマイニングを端に、歴史を振り返ります。
1960年〜:データマイニングの始まり
1960年代に企業がコンピュータを導入し始めました。
しかしコンピュータを購入できたのは大企業などだけで、しかも経理や給与計算などの基本的な事務処理機能しか担いませんでした。
ですが、データの蓄積は可能だったことから、分析したデータをビジネスに活用できないだろうかと考えられ始めました。
1980年〜:データマイニングの活用
1980年代になると、一般企業もコンピュータが導入できるほど安価になり品質も向上しました。
コンピュータの発展・普及に伴い、販売や生産、在庫管理など、幅広い業務がコンピュータでできるようになることで、大量のデータが管理されることになります。
こういった大量のデータを有効活用するために、データを分析するデータマイニングが本格的に登場し、発展することになるのです。
1990年〜:データマイニングからテキストマイニングへ
1990年代から2000年前後にかけて、データマイニングから派生したテキストマイニングが登場しました。
その背景には、コンピュータが一般家庭でも購入できるほど安価で、かつ高性能・高機能なものになり、データ容量も大きなものになったことが挙げられます。
それと同時に、大量のデータを、より高精度に分析する技術が必要になり、テキストマイニングが注目されだしたのです。
〜2022年:インターネットの普及とテキストマイニングの高精度化
さらに、インターネットが普及したことで一般家庭も気軽にデータの閲覧やアップロードが可能になりました。
しかしながら、これまでコンピュータが扱うのは数値データが主流だったため、テキストを扱うのは難しかったのです。しかしハードウェアの向上による、機械学習や深層学習といったような新しい技術の登場と発展により、機械は数値以外の、自然言語のような定性的なテキストデータを扱うことができるようになりました。そうして今までは機械ができず人間が行うしか無かったような、文章の中から必要な単語だけを判断して抽出したり、ディープラーニングによって前後の文脈から判断するといった機能を持つことが可能になり、テキストマイニングは非常に高精度になりました。
近年はパソコンやスマートフォンの登場により、遠い都市からでも誰でも自由に情報を発信することができるようになりました。中でもSNSの普及によって人々が何気ない情報を発信し、毎日とてつもない量の情報が生まれています。テキストマイニングは、このように人間が生み出す自然言語を含む大量のデータの鉱山の中から、新しいビジネスに活用できる情報というお宝をマイニングし、ますます人々の役に立つツールとなっています。
テキストマイニングが変える私達の生活
さて、結局テキストマイニングは私達の生活をどのように変えてくれるのでしょう?
もっとも大きな恩恵としては、やはり私たちが使うサービスや品質の向上です。
企業はビジネスの成長のためにも人々に対してよりよいサービスを提供する事が大きな目的です。そこで消費者やユーザーのリアルな声を取り入れることはとても重要なことですが、このテキストマイニングはまさにそういった情報収集に適した技術です。あなたがもし、「主演の〇〇さんは綺麗だ」と独り言でつぶやいてもこれまでは何も起きませんでしたが、テキストマイニングがより活用されるようになれば、あなたが独り言の内容をツイッターでツイートをするだけでも、テレビや広告代理店などがその情報を汲み取り分析することにより、あなたの好きな人がどんどん活躍するようになるかもしれません。
企業は、普段は課題や改善点を見つけるために、消費者アンケートの回答や街の声を聞くといったようなステップを踏む必要がありました。論文を読み込んで解決策を模索することも大変な手間であると思います。しかしテキストマイニングの技術によって、それらをせずとも顧客のニーズをいち早く見つけ汲み取ることができたり、結果を早く見つけることができることにより、次のPDCAが回しやすくなり、より良いサービスを提供することができます。
また、マスメディアに限らず製造業や街中の飲食店というようなあらゆる業界のあらゆる企業があなたの声を拾い、普段あなたが抱えていた煩わしさを解消するような新商品、新サービス、新ツールの登場や、商品自体の品質の向上が期待できるようになるでしょう。
テキストマイニングまとめ
ここまでテキストマイニングの定義、私たちにどんな変化をもたらすのか、実際の流れについて解説してきました。
SNSで個人が発信できるようになり、世の中には大量のテキストデータで溢れかえっています。
個人の独り言やつぶやきが多い中で、企業にとっては貴重なデータである可能性もあり、そうしたデータを分析して生み出されるサービスや製品・webツールはきっと私たちの生活をより豊かにしてくれることでしょう。
またよろしければ弊社SNSもご覧ください!
クリスタルメソッド公式note:https://note.com/crystalmethod/
X:https://x.com/YCrystalmethod
YouTube:https://www.youtube.com/@haltalktube
Study about AI
AIについて学ぶ
-

AI社員・AI上司とは何か?企業AIアバター活用の最前線【2026年】
2026年、「AI社員」という言葉をビジネスシーンで耳にする機会が増えています。AIが上司になる、AIが同僚として働く——そんな話題が現実のものになりつつある今...
-

Claude Codeの使い方|インストールからAI設計書生成まで完全実演【2026年最新】
この話について 第1話 / 全10話 2026年3月26日|著者: Kei Kawai|読了: 約15分 Claude Codeとは?2026年最新のAI開発ツ...
-

営業ロープレをAI化するメリットとは?課題をまとめて解決します
「営業ロープレをもっと効率的にできないか」という声は、営業責任者や研修担当者から絶えず聞かれます。ロープレは営業スキル向上に効果的な手法である一方、「相手の確保...