blog
AIブログ
Transformerとは?AI自然言語学習の技術を解説
皆さん、「AI」や「深層学習モデル」という単語を耳にすることが最近増えてきたのではないかと思います。
しかし、その仕組みについて知りたいと感じても、「私には難しそう…」と敬遠してしまっている方も多いのではないでしょうか?
本記事ではAIの最新技術「Transformer」について、数式を用いず分かりやすく説明し、その応用についても紹介します!
本記事で概要を掴んでいただき、さらに詳しく知りたい方にはぜひ原論文をお読みいただければと思います!
Transformerとは
Transformerとは、2017年に発表された”Attention Is All You Need”という自然言語処理に関する論文の中で初めて登場した深層学習モデルです。それまで主流だったCNN、RNNを用いたエンコーダ・デコーダモデルとは違い、エンコーダとデコーダをAttentionというモデルのみで結んだネットワークアーキテクチャです。
それによって、機械翻訳タスクにおいて
- 英独翻訳において28.4BLEU, 英仏翻訳において41.0BLEUというそれまでで最良のBLEUスコアを取得(40以上で高品質とされている)
- それまでの学習モデルと比較して、大幅な学習時間の短縮を実現
というような速いのに精度が高いという特徴を持ち、非常に使い勝手のよいものとなっています。
はじめは機械翻訳などの自然言語処理(NLP)モデルとして紹介されていましたが、モデルが簡潔なこともあり、もちろん機械翻訳以外の分野でも高い実用性を誇ります。
基本知識

ディープラーニング(深層学習)
ディープラーニング(深層学習)とは、大量のデータを機械に学習させることで、機械が人間のように判断できるようにするにはどのパラメータに着目すべきかを学習させる人工知能技術のひとつです。ディープラーニングのアルゴリズムは、大まかにディープニューラルネットワーク(DNN)と畳み込みニューラルネットワーク(CNN)、再帰型ニューラルネットワーク(RNN)の3種類があります。詳しくは深層学習について説明します!をご覧ください。
自然言語処理(NLP)
自然言語処理(NLP)とは、人間が日常のコミュニケーションで使う曖昧さのある話し言葉や、新聞などの書き言葉を含む自然言語をコンピューターで分析、処理する技術です。この技術により、例えばSNSでの口コミなど不規則な情報も分析することができます。詳しくは自然言語処理(NLP)とは?できることなどを分かりやすく解説もご覧ください。
Attention
Attentionとは、簡単にいうと文中の単語の意味を理解するのにどの単語に注目すればいいのかを表すスコア、もしくはそれを出す機構です。入力されたデータに重み付けをして重要性を考慮したベクトル量として出力します。例えばある画像が入力されて画像の説明を出力するとします。そのときAttention機構は既に生成された単語のコンテクスト情報を前の隠れ層から受け取り、次に画像のどこに注目すべきなのかを推論します。
これがTransformerで重要な役割を担います。
Transformerの構造
本モデルは、Attentionのみを使用して学習しても高い精度で翻訳ができるというもので、高い精度や学習コストの低さから、非常に優れているモデルです。
Transformerは①エンコーダ・デコーダモデルをベースとしており、②Self-Attentionと③Position-wise Feed-Forward Networkが組み込まれています。
①エンコーダ・デコーダモデル
翻訳などの、文章を他の文章に変換するモデルでよく使用されています。
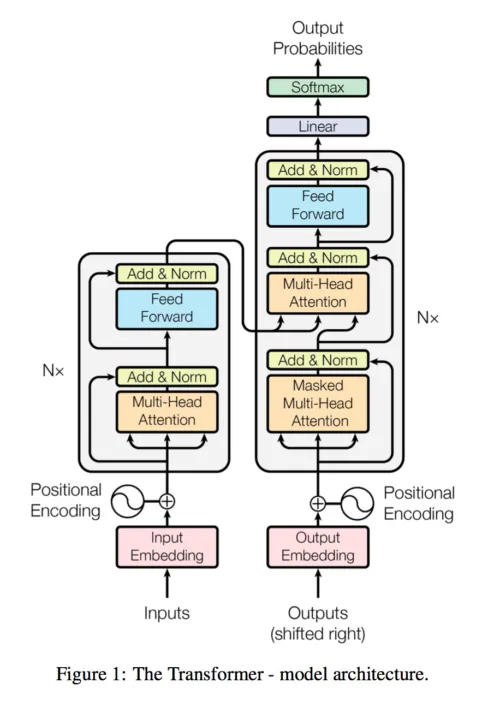
Ashish Vaswani,Noam Shazeer,Niki Parmar,Jakob Uszkoreit,Llion Jones,Aidan N. Gomez,Łukasz Kaiser,Illia Polosukhin 2017 Attention Is All You Need 3 より画像の引用
上図では、左半分がエンコーダ、右半分がデコーダを表しており、例えば、英語の文章を日本語の文章に翻訳させたい場合、エンコーダに英語の1文(I like apples)を入力します。
◆エンコーダ
例えば、処理を6回繰り返す場合、エンコーダのメイン部分はN=6(層が6個)の同じ処理をする層で構成されています。
入力文章を赤のEmbedding層で圧縮、Position Encoding層で入力の位置(単語が文のどこにあるか、など)を付加し、メイン部分に入力されます。
メイン部分の各層には、Multi-Head Attention層とPosition-wise Feed-Forward Network層の2つのサブ層があります。それぞれのサブ層の後には残差接続と正規化処理(Add & Norm層)が採用されています。
6層分処理を繰り返し、出力をデコーターへと渡します。
◆デコーダ
デコーダのメイン部分もN=6の同一の層で構成されており、メイン部分までの処理はエンコーダと同様です。
メイン部分の各層には、エンコーダの2つのサブ層に加えて、1つ目のサブ層からの出力を受け取るMulti−Head Attention層が追加されています。エンコーダと同様にそれぞれのサブ層はAdd & Norm層によって正規化されています。
最初のMulti-Head Attentionはmasking(入力文章の単語のうちの一部をハイフンなどで置き換えること)されており、Position Encoding層からの情報をマスクする(隠す)役割を担っています。
②Multi-Head Attention層(Self-Attention層)
Multi-Head AttentionはSelf-Attentionのモデルを並列で行っている構造です。
Self-Attentionとはある1文の単語だけを使って計算された、単語間の関連度スコアのようなもので、一つの文章のなかでの単語の関連づけをするための概念です。
入力された文章は単語ごとに区切られてから、エンコーダに入力されていきます。
すると、文章の前から順に1単語ごとに処理されていくのですが、モデルが各単語を処理するときに、他の単語の位置を調べてこの単語のエンコードをより精度の高いものにしてくれます。以下の画像のように1つの文章の中の単語(今回はit)がその文章中の何を示しているのかを探し、翻訳の際にその関係性を考慮してくれます。単語の意味を考慮している、という点で優れています。

http://jalammar.github.io/illustrated-transformer/ より引用
ここで行われていること
- エンコーダの各入力ベクトルから、Query・Key・Valueの3つのベクトルを作成する。
- 入力文の各単語を実数ベクトルに変換する。
例えば、入力文を「I like baseball.」としたとき、まずはじめに各単語をembeddingして実数ベクトルにしています。 「I like baseball.」→「I / like / baseball 」→「[0.10, 0.20, 0.30] / [0.40, 0.50, -0.60] / [0.70, -0.80, 0.90] 」 というようなイメージです。 - 作成した3つのベクトルを用いて、入力文の各単語間の関連性を表すスコア(Self-Attention)を計算します。 入力文の各単語を、焦点を当てている単語に対してスコアリングします。 スコアは、特定の位置で単語をエンコードするときに、入力文の他の単語にどれだけ焦点を合わせるかを決定します。 このスコアは、Queryと、スコアリングするそれぞれの単語のKeyの内積をとることによって計算されます。
- スコアをある値で割り、(デフォルトは8とされています)次に結果をソフトマックス関数に渡します。ソフトマックス関数はスコアを正規化して、合計が1になるようにします。
このソフトマックススコアは、ある位置で各単語がどれだけ表現されるかを決定します。その位置にある単語のソフトマックススコアが最も高くなりますが、他の単語についても勿論数値は出されます。 - 各値ベクトルにソフトマックススコアを掛け、焦点を当てたい(文章の中で似た意味を持つ)単語の値をそのまま維持し、無関係な単語をより無関係なものにします。(単語の関係性を0〜1の係数に変換します)
- 5で計算したスコアを合計します。 これによりこの位置(最初の単語)での出力(ベクトル)が生成されます。これを続けることで、以下のような各単語間の関連度スコアを算出します。これがSelf-Attentionにあたります。IlikebaseballI0.850.050.10like………baseball………「I」という単語は当然それ自身である「I」との関連度が高いですが、他の単語との関連性も0ではないということを表しています。(例えば「That is a pen.」という文章においてThat = pen なのでこの2単語の関連性は非常に高いです。)
結果は行列であり、Self-Attention層は、この行列を次のFeed Forward Neural Networkに送ります。
◆Multi-Head Attention
Transformerが登場した論文では、この、Multi-Head-Attentionと呼ばれるメカニズムが大きなポイントとなっています。Multi-Head-Attentionとは上記のSelf-Attentionを複数個並列で行っているメカニズムです。
例えば「Thinking Machines」という言葉を入力とします。
- 各単語をベクトルに変換します。(embedding)
- 8つのAttention headに分けます
- 8つのAttention headそれぞれについてSelf-Attentionの項目で説明したことと同じ計算をします。
- 各計算の合計に当たるZ行列を重み行列と掛け合わせたものがMulti-Head self-Attention層の出力となります。
③Position-wise Feed Forward Network層
Position-wise Feed Forward Network層はエンコーダ及びデコーダの各層に含まれており、ReLUを挟んだ2つの線形変換で構成されています。
文中の単語ごとに独立して順伝搬ネットワークを構築するため、単語間の影響を受けずに並列処理を行うことができます。ただし、層間の重みは共有されます。
Transformerの発展モデル
冒頭でも述べたとおりTransformerの登場はディープラーニング界、特に自然言語処理の分野の急速な発展に繋がりました。
Transformerを用いたモデルとしてはBERT・Reformer・Conformer・T5・DeFormer・PaLMなどが上げられます。
◆BERT
BERTと呼ばれるものは2018年にGoogleが開発したものです。
BERTは、様々な言語タスクで、当時の最先端のモデルの性能を上回る性能を見せました。特徴の一つとして、文脈を考慮した分散表現を生成できるということがあり、BERTではAttentionという手法により、離れた位置にある情報も、適切に取り入れることができました。文脈を深く考慮したような処理が可能となっています。BERTには事前学習で、大量の文章のデータを用いて汎用的言語を学習したあと、少数のラベル付きデータを用いて、BERTを特定のタスクに特化するようファインチューニングをします。
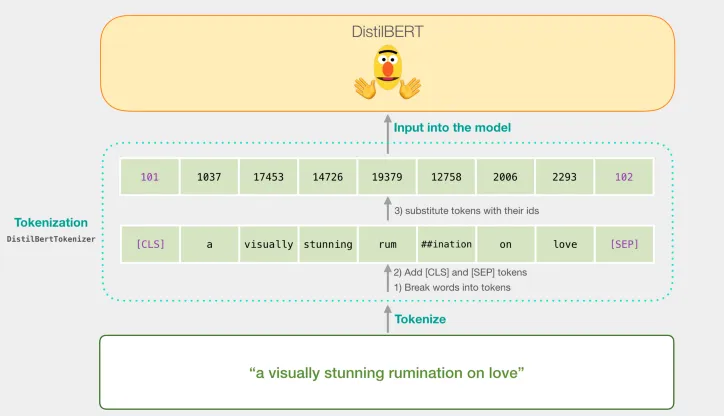
Deep Transformer Models for Time Series Forecasting: The Influenza Prevalence Case より引用
トークナイザは文章をトークンに分割して、BERTに入力できる形に変換するために使います。文章をトークン化、符号化しました。符号化されたデータをBERTに入力し、それぞれのベクトルを得ます。
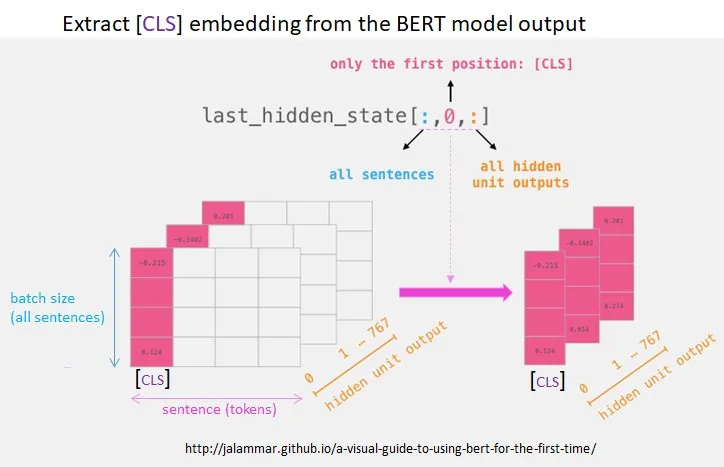
Deep Transformer Models for Time Series Forecasting: The Influenza Prevalence Caseより引用
lat_hidden_stateは三次元配列であり、BERTの最終出力はlast_hidden_state[i,j]の一次元配列で与えられ、これがトークンの分散表現を与えます。
BERTアップデートにより、会話型のクエリやより複雑な条件を含んだ検索クエリに対しても、正確に検索結果を返せるようになっているため、Googleは2019年10月25日に英語圏での、最新の自然言語処理技術”BERT”を検索エンジンに採用したと発表しています。また同年12月10日には日本語圏を含む70以上の言語においても導入されたことがGoogleより発表されています。
BERTについては、こちらの記事でも解説しています!
◆Reformer
Reformerは、Transformerを改良し、処理を軽量化したモデルです。TransformerはRNNのLSTMモデルなどと比べて処理が速いのですが、ウェブサイト1ページを丸々翻訳するなどの重いタスクや短い文章でも精度を高くしたい場合は、Transformer層を重ねて何度も処理を繰り返す必要があり、どうしても処理が重くなってしまう問題がありました。
そこで、開発されたのがReformerというモデルで、「Reversible Residual layers」や「Local-Sensitive-Hashing(LSH)」という手法を用いることで、Transformerの課題であった「各レイヤーでの学習状態を保存する必要がある」、「ウェブページや小説などの長い入力では精度が落ちる」といった課題に対して「可逆的なレイヤーを用いてネットワークを逆から計算できるようにする」、「可能なすべてのベクトルのペアを検索するのではなく、類似したベクトル同士をマッチングさせて処理をすることで計算を効率化する」といった対策をしたことで、より効率的なモデルとなりました。
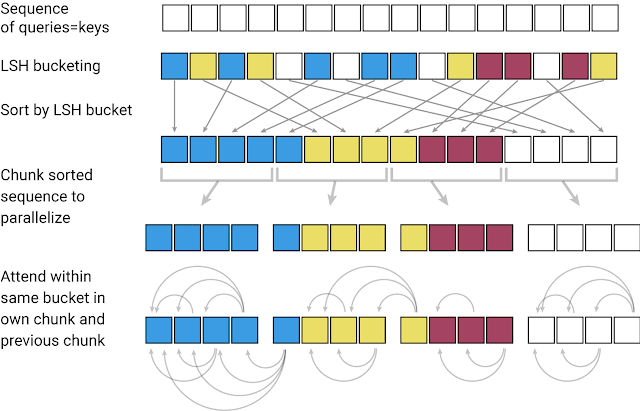
論文(REFORMER: THE EFFICIENT TRANSFORMER)から引用
◆Conformer
Conformerは、2020年に発表された、TransformerとCNNを組み合わせたモデルです。特徴としては、文章の中の遠い関係性の単語間の情報(グローバルな情報)を学習するのが得意なTransformer、近い関係性の単語間の情報(ローカルな情報)を学習するのが得意なCNNを組み合わせて音声認識に応用したことで、これまで音声認識で主流だった、RNNをベースにした手法に比べて、少ないパラメータでも高い精度での音声認識ができるようになりました。
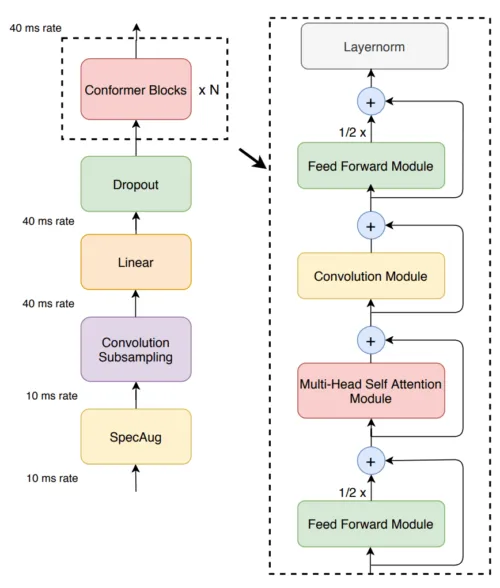
論文(Conformer: Convolution-augmented Transformer for Speech Recognition)から引用
◆T5(Text-to-Text Transfer Transformer)
T5は、2020年にGoogleが発表した、Transformerのモデル構造やパラメータなどを見直し、より活用しやすく、精度を高めたテキスト生成モデルです。大きな特徴として、どんな入力に対しても回答をテキスト形式で返す点があげられます。
一般的な自然言語処理タスクには、「翻訳」「質問に対する回答」「文章生成」などがあります。
例えばですが、「質問に対する回答」については、「回答のテキスト,回答が正解である確率の数値」のように、出力が数値である場合もあります。こうなると数値を出力するわけではない「翻訳」や「文章生成」のタスクとは全く別の学習が必要になってしまうという問題がありました。
しかし、T5は「どんな入力に対してもテキストを出力する」という形式をとり、「質問に対する回答」については、「回答のテキスト,回答が正解である確率の数値のテキスト」を出力することで、違う自然言語処理タスクでも学習し直す必要がなくなり、タスクの垣根を超えてモデルを使用することができるようになりました。
また、その精度も優れており、GLUE(言い換えや質疑応答などの自然言語処理の様々なタスクの評価テスト)やSuperGLUE(より難易度の高いGLUE)で当時の最高精度を達成しました。
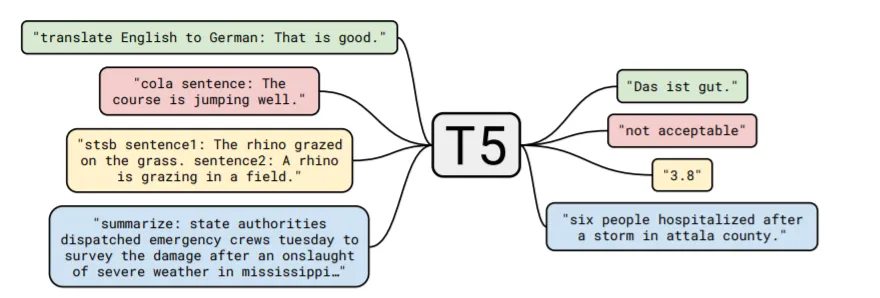
論文(Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer)より引用
◆DeFormer
DeFormerは事前に学習させたTransformerベースのモデルをより高速に実行できるように、分解の要素を取り入れたモデルです。
通常のTransformerでは、Q&A形式のタスクにおいて、質問とインプットされた文章の全てにAttentionをかけてしまうことで、メモリの無駄遣いなどから速度が遅くなる問題がありました。しかし、実際には下位層では全てにAttentionをかける必要がないことから、下位層を分解して考えることで、Q&Aタスクにおいて事前学習を繰り返す必要がなくなり、使用メモリの削減やモデルの高速化を実現しました。
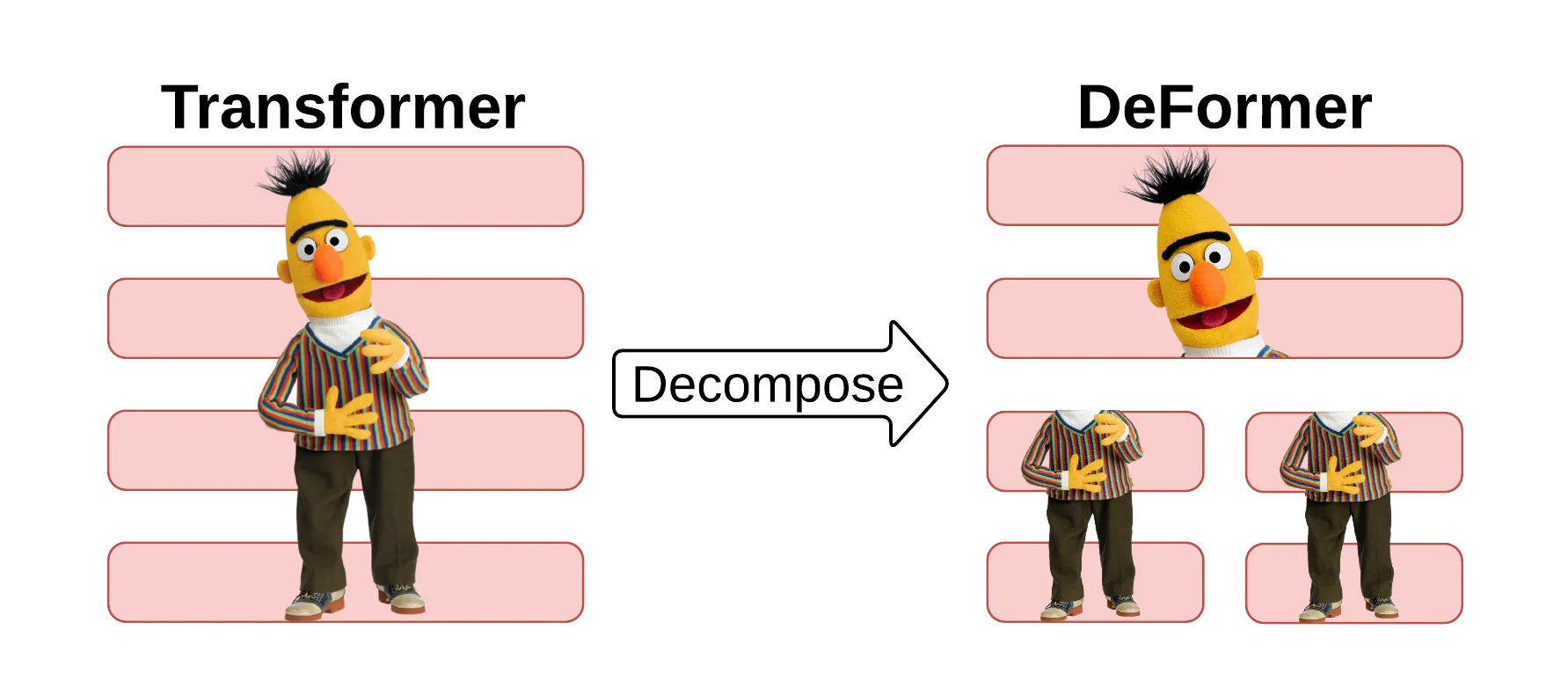
論文(DeFormer: Decomposing Pre-trained Transformersfor Faster Question Answering)から引用
◆PaLM
PaLMは2022年4月にGoogleの研究者らが発表したモデルです。標準的なTransformerモデルを元に、有効性があるとされている改善がいくつかなされています。論理推論問題では、答えへの道筋を言語化してアウトプットとして出すChain of thoughtsという手法を使い性能向上に成功しています。他にも幅広い言語タスクで性能向上に成功しています。
PaLMはPathways language Modelの略であり、Pathwaysとは複数のTPU Podにまたがった計算を効率的に実行するシステムです。パイプライン並列化に頼ることなく大量のデバイス間で非同期にデータを送受信・更新することで効率化に成功しています。
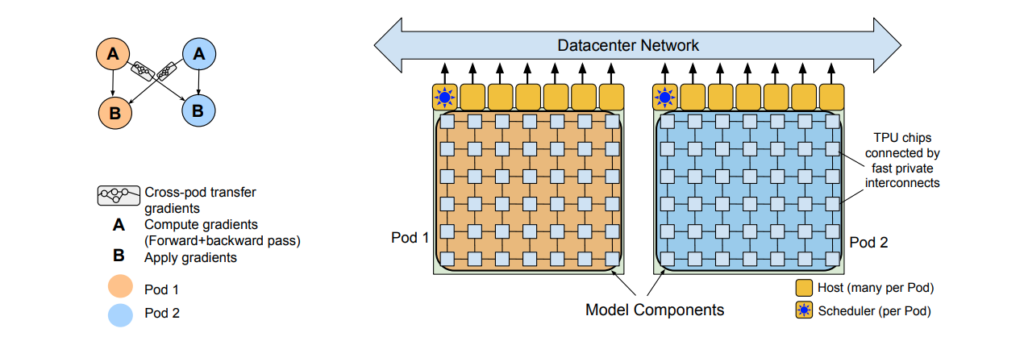
論文(PaLM: Scaling Language Modeling with Pathways)から引用
Transformerの実装フレームワーク
アメリカの企業「Hugging Face」社が提供している「Transformers」というフレームワークを用いることでtransformerのモデルを試すことが出来ます。PyTorch, TensorFlow, JAXといった人気のディープラーニングライブラリ向けの、Pythonモジュールとなっていて、自分で使用するだけでなくカスタマイズすることができるのも特徴です。
transformers(Hugging Face社サイト)は様々な用途に仕様することができ、20000を超えるトレーニング済みモデルで備えた数十のアーキテクチャからなります。トレーニング済みなのでどんな人でも簡単に扱うことができるようになっています。
自然言語処理にはMasked word completion with BERTやName Entity Recognition、コンピュータービジョンにはImage classification with ViTやObject Detection with DETRといった豊富な種類のモデルを利用することができます。
詳しい内容はTransformers – Hugging Faceからご覧頂けます。
他には、Kerasを用いてTransformerを実装をしてみたい方は、Qiitaに”Kerasで実装するTransformer”の記事があるのでご覧ください。こちらのリンク ”https://qiita.com/gacky01/items/b4dc0b507688e678ac85”で調べてみてください。
Transformer事例紹介
最後に、これまで紹介したモデルの例を紹介します。
◆Transformerのみの事例
[時系列データ予測]
論文(Deep Transformer Models for Time Series Forecasting:The Influenza Prevalence Case)では、週単位の地域別インフルエンザ様疾患(Influenza-like Illnesses:ILI)比率を予測するため、Transformerが活用されています。基本的な構成はTransformerと同様です。
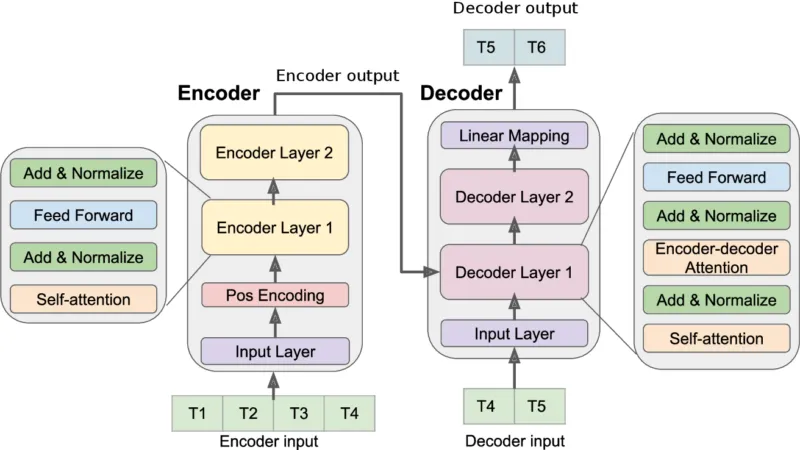
論文(Deep Transformer Models for Time Series Forecasting:The Influenza Prevalence Case)から引用。
上図では、T1〜T4までの時系列データをEncoderに入力し、DecoderにT4とT5の時系列データを入力することで、T5とT6の時系列データを予測しています。
[音楽生成]
論文(MUSIC TRANSFORMER: GENERATING MUSIC WITH LONG-TERM STRUCTURE)では、時系列の音データを入力に、Transformerによって音楽を創造するチャレンジも行われています。処理パフォーマンスの面で課題はありますが、将来的に音楽生成ツールとしてTransformerが活躍することが期待されます。
[物体検出]
論文(End-to-End Object Detection with Transformers)では、CNNで画像を処理したあとにTransformer構造に渡すことで、物体検出をより簡単に学習する手法が紹介されています。小さい物体に対しての検出力はまだ高くないようですが、自然言語処理以外でもTransformerは多くの分野で活躍する可能性のあるモデルだといえるでしょう。
◆Reformer(軽量化されたTransformer)の事例
論文(REFORMER: THE EFFICIENT TRANSFORMER)では、100万語のテキストを16GBで処理することができると紹介されています。
また、Google Colaboratoryに英語の自動生成のための環境が揃っており、また、日本語の文章を学習させると日本語文の自動生成が可能です。
◆Comformer(CNNとTransformerを組み合わせたもの)の事例
Conformerが発表されたこちらの論文(Conformer: Convolution-augmented Transformer for Speech Recognition)では「LibriSpeech」という自動音声認識用コーパスでのベンチマークが、それ以前のTransformerとCNNを用いた最新のモデルよりも高い精度を出したということが紹介されています。
また、論文(Pushing the Limits of Semi-Supervised Learning for Automatic Speech Recognition)ではConformerとラベル付きのデータを用いたことで音声認識タスクの精度が向上したということが示されています。半教師あり学習を行う目的としては、大量のデータに対してラベルをつけて教師あり学習を行うのはかなりの労力を必要とするので、ラベルのついてない大量のデータセットを使用することで、教師ありのタスクの性能向上を支援するところにあります。論文の中では、半教師付き学習のためのデータとしてパブリックドメインのオーディオ書籍のデータベースを用いて、音声認識タスクのLibriSpeechでSoTA(その時点での最高精度のモデル)となっています。
◆GPT-2とGPT-3の事例
論文(Language Models are Few-Shot Learners)ではGPT-3についての概要が説明されています。
2015年に、イーロン・マスクを筆頭とした、起業家、実業家などから援助をうけて立ち上がった、AIを利用する、アメリカの非営利団体のOpenAIが2019年に公表したのが、GPT-2というものです。とても便利な一方、悪用されるのではないだろうかという観点から最初はすべてを一般公開とはいたらなかったのですが、約9ヶ月語には一般公開にいたりました。GPT-2及びGPT-3はTransformerがベースなっています。2020年にはGPT-3が登場しています。GPT-3は事前学習済みで、文章生成を行うものであります。GPTは自然な文章をつくることを目的としています。例えば人間がかいた文章に肉付きを加えることが可能となっています。人間が書いた文章から感情を読み取ることも可能であり、モデルのサイズが大きくなるほど性能がよくなっています
画像はこちらの論文(Language Models are Few-Shot Learners)より引用しています。
数学の定理を知らないAIに、言葉から数学を学ばすことが可能となってきていて足し算などが可能となっています。一方、GPT-3での技術はまだまだ発展途上ともいわれ、アイスクリームを冷蔵庫に入れた時に、溶けるかどうかというと質問に対しては、人間であれば、溶けないと答えるところ、AIは溶けると答えてしまうため、人間にはまだ追いついてない部分がいくつかありますが、将来的に人間と同じようになることが考えられるでしょう。
クリスタルメソッドでのtransformerを用いた取り組み
弊社でのTransformerを用いた事例を2つ紹介します。
◆音声認識での事例
動画プレーヤー
00:00
01:23
上の動画は、弊社の音声認識・話者推定システムの動作サンプルです。このシステムは音声認識と話者推定を行いますが、このシステムにもTransformerが利用されています。
音声認識とは音響モデルと言語モデルの2つの要素からなります。音響モデルは音波波形を音素へ変換し、言語モデルは音素を文章へと組み立てます。
例えば「今日はいい天気です」という音声は以下のようなステップで文章に変換されます。
音声波形(〜〜〜)
→[音響モデル]
→音素(kyo u wa i i te N ki de su)
→[言語モデル]
→文章(今日はいい天気です)
この2つのモデルの内、言語モデルの方にTransformerを用いています。
既に解説した通り、Transformerはアテンションを使って前後の単語から正解のヒントになる情報を得るように学習することができます。そのため文脈によって答えが変わるようなケースにも柔軟に対応することができます。
以下の例では、急行と休講を文脈で判断し、適切な文章を得ることができています。
入力:kyu u ko u no ga shi ta ka ra o ku re ru to o mo Q ta ra ma sa ka no kyu u ko u wa ra .
出力:急行逃したから遅れると思ったらまさかの休講笑。
このようにTransformerは、弊社のシステムをはじめ、実際の現場で既に利用されているのです。
◆文章生成での事例
クリスタルメソッドでは、GPT-2、GPT-3を使ったシステムも開発しています。ここではGPTを用いた簡単な例を紹介します。
GPTは自然な文章を自動で作成することを目的としたAIです。弊社のシステムとは異なりますが、例えば「個人情報の流出」に関してGPTに文章を生成させてみましょう。
以下がGPTの出力です。
個人情報流出の危険性について以下のように挙げられます。
個人情報流出のリスクを回避するためには、やはり外部とのやりとりを最小限にし、安全にインターネットを利用することが必要になります。そして、その上で、より良いインターネット環境を提供してくれるのが、インターネットサービスプロバイダーです。インターネットサービスプロバイダーによって提供されるサービスや、契約の仕組み等に大きな違いがあります。インターネット上では、webサイト閲覧やメールの受信、ホームページへのリンクの掲載といったような、多くのユーザーがパソコンを利用します。さらに、その利用が、個人の嗜好や生活スタイルなどを反映するという側面もあります。このように、webサイトの利用にパソコンが必要かというと、必ずしもそうとは言い切れません。 しかし、webサイト利用者にとっても、さまざまな利用者が存在し、それぞれに目的のwebサイトを利用できます。したがって、webサイトの利用が、パソコンの利用に限定してしまうのは、非常に残念なことです。また、インターネットサービスプロバイダーの提供するサービスの多くは、個人と個人が結ぶサービスであるという側面があるため、利用者は、情報の保護を意識する必要があります。 個人と個人が結ぶwebサービスは、利用者同士が意思の疎通を図ることができます。しかし、webサイト利用者が、個人間のやりとりでトラブルを起こしたり、個人情報を流してしまったりなど、個人間のトラブルを起こさないように、webサービス利用者にも気を使う必要があります。(続く)
このように、Transformerを応用したGPTはある程度自然な文章を生成することができるのです。
Transformersについて
Transformersは、自然言語処理(NLP)と機械学習において非常に人気のあるオープンソースライブラリです。このライブラリは、最先端のNLPモデルを利用しやすい形で提供しており、様々なタスクに対応できるようになっています。
Transformersは、以下のような特徴があります。
多様なアーキテクチャのサポート: Transformersは、BERT、GPT-2、RoBERTa、T5、DistilBERT、ALBERTなど、最先端のNLPアーキテクチャをサポートしています。
タスク対応力: Transformersは、文章の分類、感情分析、質問応答、要約、機械翻訳、テキスト生成など、多様なNLPタスクに対応しています。
プリトレーニング済みモデル: Transformersは、各アーキテクチャに対して、大量のデータを使って事前に学習されたモデルを提供しています。これにより、ファインチューニングを行うだけで、独自のタスクに適用できます。
転移学習の容易さ: Transformersは、転移学習を行いやすくするように設計されています。事前学習済みのモデルを独自のデータセットで短時間でファインチューニングすることができます。
言語サポート: Transformersは、英語をはじめ、多様な言語をサポートしています。これにより、異なる言語のタスクにも簡単に適用できます。
コミュニティ: Hugging FaceのTransformersは、アクティブなコミュニティに支えられており、開発者が質問したり、問題を報告したり、新機能を提案したりすることができます。
Transformersを使用するには、Pythonプログラミング言語が必要です。
【まとめ】Transformerとは

自然言語、つまり人間の言語を、一旦機械語に変換した後、人間の言語になおして、出力してくれます。翻訳家のお仕事をしてくれていると考えるとわかりやすいかなと思います。
自然言語処理のもととなっているものはすべて、このTransformerが元となっており、Transformerの理解は、自然言語処理を詳しく学ぶ上で役立つでしょう。
みなさんおなじみの翻訳DeepL、普段お世話になっているGoogleでの検索エンジンの向上など我々も沢山の恩恵を受けています。
最近では、自然言語処理の分野では、人間と遜色なのないレベルまで近づいてきており、実際、2021年には、アメリカのマイクロソフト社、Googel社、それぞれのディープラーニングモデルが、自然言語処理のベンチマークとされる人間のスコアは89.8を共にそれぞれ上回りました。
2019年、NTT社はセンター試験の英語の試験での点数が向上していることを示しています。
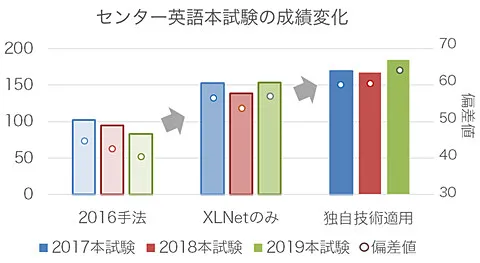
大学のレポートのコピペチェックにも使われており、他レポートとの関連度などが分かるようになってきています。
Transformerは現在では、様々な分野に応用が効くようになってきているので今後の進歩がますます目が離せませんね!
この記事を呼んでいただき弊社での取り組みに興味を持っていただけた方は是非SNSのほうも確認していただけると幸いです。
クリスタルメソッド公式note:https://note.com/crystalmethod/
X:https://x.com/YCrystalmethod
YouTube:https://www.youtube.com/@haltalktube
Study about AI
AIについて学ぶ
-

営業ロープレをAI化するメリットとは?課題をまとめて解決します
「営業ロープレをもっと効率的にできないか」という声は、営業責任者や研修担当者から絶えず聞かれます。ロープレは営業スキル向上に効果的な手法である一方、「相手の確保...
-

AIロープレとは?営業・接客・面接練習での活用法を解説します!
人手不足が深刻化し、新人教育の「早期戦力化(イネーブルメント)」が企業の最重要課題となる中、教育現場に破壊的なイノベーションが起きています。 従来のコミュニケー...
-

AIロープレツールの選び方|比較ポイントと主要ツール比較を解説
「AIロープレを導入したいが、どのツールを選べばいいかわからない」という声をよく聞きます。AIロープレツールは種類が増えており、対応している業種・機能・価格もさ...