blog
AIブログ
マルチモーダルAIとは?詳しく解説

マルチモーダルとは
「multi」+「modal」という言葉を組み合わせたコンピュータ用語
です。あまり聞きなれない言葉かと思いますが、AIの技術進化を語るうえでは外せない言葉です。
高度情報化社会でありAIの成長が著しい現在において、マルチモーダルの重要性も上がっています。
「マルチモーダルAI」が何なのか、マルチモーダルAIの技術開発に特化した弊社が詳しく解説していきます。
弊社ではマルチモーダルAIに特化した技術開発を行っております。
社内のDX,IoTをお急ぎですか?こちらからお問い合わせください。
お問い合わせ
マルチモーダルAIとは

「モーダル」という言葉にはAIへの入力情報の種類(画像、音声、テキストなど)の意味があり、マルチモーダルAI=複数の種類の情報を一度に処理するAI技術と解釈できます。
これまではAIの未発達やコンピュータの情報処理能力の限界からシングルモーダルしかできませんでしたが、機会学習によるAI技術の進化でマルチモーダルが可能になりました。
マルチモーダル技術の活用により情報処理速度は劇的に向上しAIの性能も飛躍的に向上しました。AIの可能性が一気に広がり様々なものに活用されていきました。
そんなマルチモーダルの仕組みや歴史について次項で解説していきます。
マルチモーダルの歴史
マルチモーダルを語るうえでAIのディープラーニング(深層学習)は切っても切り離せません。
まずはディープラーニングについて軽く解説します。
ディープラーニングとは
20世紀までのコンピュータのスペックは低く処理速度や情報処理能力に限界がありました。しかしAIを搭載することによって、「与えられた情報から何らかの規則や共通点を見つけ学習し、分析する」ことが可能になりました。
これが機械学習です。
その機械学習の手法であるニューラルネットワークという分析手法を拡張して高精度の分析や応用が可能になったのがディープラーニングです。人間が得た情報や課題を処理する過程をコンピューターにも学習させ、再現することができます。
機械学習についてはこちらの記事で詳しく解説していますのでぜひご覧ください。
>> 機械学習とは?概要やアルゴリズムを詳しく解説!
これによりAI技術は飛躍的に上昇し、解析する速度や精度も向上したのです。
次の段階は、人間が与えた情報をより正確に見分けることです。
私たちは生活しているうえでたくさんの情報や刺激が常に入ってきます。
目(視覚情報)からは人の顔や風景、文字や色など
耳(聴覚情報)からは人の声や怒鳴り声、車の音や風の音など といった具合です。
従来のAI技術ではそれぞれを単独でしか認識できず、表面的な情報しか抽出できませんでした。
時が経つにつれてディープラーニングで多くの情報を吸収したAIはより細かな認識が可能になりました。
具体例をいくつか挙げていきます。
①画像認識の例
◆従来AI技術・・・バーコードから数字や文字情報を読み取る。画像検出のためのテンプレートマッチング方式の利用
◆ディープラーニング以後のAI技術・・・動物などの人以外の認識が可能になり、高精度で認識ができる
②音声認識の例
◆従来AI技術・・・単語情報と、特定話者対応により事前学習が必要な文章認識タイプの音声認識AI
◆ディープラーニング以後のAI技術・・・音から雑音と人の声とを区別し、声の特徴や抑揚から感情を認識したり、音声情報をテキストに変換することができる
③テキストマイニングの例
◆従来AI技術・・・数値化やコード化されたデータに対してのマイニング。
◆ディープラーニング以後のAI技術・・・大量のテキストデータから必要な情報をすばやく取り出す。
このように、従来AIとディープラーニング以後のAIとの技術比較をしてみるだけでも各段に技術精度が向上したことがお分かりいただけるでしょうか?
これらはほんの一例に過ぎず、今もなおAIはディープラーニングにより学習し、精度を上げています。
しかし、ディープラーニングにより強化されたAIも単一のテキスト情報や視覚情報のみで行なっては精度を上げる限界があります。
そこで“こちらが与えた情報を画像や音、内容などから総合的に判断する”マルチモーダルの技術が必要になります。
画像や音声だけというシングルモーダルの情報だけでは精度が不十分だったものも、複数の情報を加えて総合的に判断することで精度を上げることが可能になりました。
シングルモーダルよりもマルチモーダルのほうが総合的に判断するため、より精度は上がりますが、処理する内容が多くなるために高いコンピュータ技術が要求されます。
また動きや音などたくさんの情報が含まれているものはマルチモーダルに適していますが、画像解析や2次元の分析においてはシングルモーダルでも問題ない場合もあるため、いかに上手く使い分けるかが重要といえます。
皆さんも、ユーザーが入力した質問の内容を理解し、自動で返信内容を作成し読み上げて回答するようチャットボットのサービスを利用したことがあるでしょう。これらもマルチモーダルを使ったAIのサービスになります。
マルチモーダルによって精度が高くなっただけでなく、様々な用途に使用可能になり、AIの可能性が一気に広がったのです。
マルチモーダルでどのようなことが可能になったのか

シングルモーダルにおいてAIは1つの情報のみでしか判別できません。
しかし、人間が五感で情報を処理して判断するように、マルチモーダルを学習することでAIも視覚情報、嗅覚情報、触覚情報、聴覚情報など、様々な情報を複合的に判断することで精度を上げました。
ここではマルチモーダルが可能にしたことをご紹介します。
活用事例1.行動認識技術による防犯対策、トラブル発生の防止
行動認識技術とは、マルチモーダルによって人の数だけでなく、人間の骨格までも検知してどの人がどんな行動をしているのかまでも認識する技術のことです。
主に監視カメラの防犯対策技術に導入されており、画像情報/音声情報/行動情報を総合して判断を行います。
例えば男性2人が向かい合って何かを話し合っていると場合、
画像情報のみだと会話と言い合いの区別がつかず、行動情報のみ、例えば映像から肩を叩く動作を認識してもふざけてるのか暴力行為なのか判断できず、音声情報のみでは詳細な状況を理解することが難しいです。
様々な情報をマルチモーダルで考えることによりAIが正確に物事を判断し、いち早く危険を察知して知らせることでトラブルを最小限に食い止められます。
活用事例2.生産工場などでの異変検知
マルチモーダルは人間でいう五感だけでなく、振動や異音、温度などにも応用することができます。
通常では起こりえない振動をAIセンサーが感知するように学習させたり、正常な温度を学習させることで、異常な数値を検知した際に警報や管理人に知らせることが可能です。
これらは生産工場などに導入されています。
・画像認識技術を使って正しい規格か、異常な物体が混じっていないかの検品作業
・音声認識技術を使って機械が摩耗していないか、故障していないかの確認
メンテナンス時に異音や変な振動がないかのチェックなど、幅広く活用できます。
これらは消費者に守るだけでなく、生産工場の商品の質を守るため、また安全を保証するためにも重要な役割を担っています。
活用事例3.コロナウイルス対策
世界中で猛威を振るっているコロナウイルス。
その感染力の高さから外出を控えるように言われていますが、出社しなければならない場合や買い物などやむを得ない場合は少なからずあります。
その場合もマルチモーダルが活用されています。
特にお店や飲食店などは消毒を積極的におこなっているところも多いですが、人間の目だけでは完全に消毒できているのか判断が難しい場合があります。
そこでマルチモーダルを使います。マルチモーダルは映像に映っている物体や人間の動きを認識できますので、人間の行動情報から消毒し忘れている場所を示したり、Co2の量を検知して空気の入れ替えのタイミングを伝えることができます。
また、従業員の体温や表情の変化を検知して、いち早く体調不良に気付くことで、ウイルスの繁殖や感染拡大を防ぐことができます。
活用事例1のように、今は屋外でマスクを外して大声で会話する行為が嫌われていますので、そういった行為をおこなっている人がいれば早急に発見、対応することができます。
活用事例4.自動運転
近年、車の自動運転の研究が盛んですが、これらにもマルチモーダルが活用されています。
人間は運転する際に五感で様々な情報を読み取り瞬時に判断しています。
前方の信号だけでなく急な人の飛び出しやその場の交通状況に応じた走りを要求されるため、カメラセンサーによるアシスト技術が存在していた当時でも、AIによる運転の自動化は難しいと思われてきました。
しかし、マルチモーダルが使われるようになってからは、物体認識だけでなくクラクションや踏切などの音、歩行者が幼児や高齢者などの詳細な区別、総合的な判断が可能になりました。
これにより、白線や障害物、前方との車間距離などの情報を認識した自動運転が実験的におこなわれており、近い将来には完全な自動運転技術が確立されるといわれています。
また、運転手と会話するAIも開発されており、カーナビゲーションを声で操作可能にすることで、余所見をして前方から視線を外すことがなくなったり、AIが運転手に音声で様々な交通情報を与えてくれます。
他にもAIセンサーが運転手の視線や挙動から眠気を感知したり、苛立ちを感知して事前に休息を提案するなど、事故や危険を未然に防ぐようなシステムが開発されています。
これらもマルチモーダルの開発による恩恵が大きいものになります。
マルチモーダルの今後

すでに様々な製品にAIが搭載されており、非常に可能性に満ちているマルチモーダルですが、今後はどのようにマルチモーダルが発展していくのか考察してみましょう。
医療×マルチモーダル
すでに医療の分野においてAIの導入が進められていますが、その中でも最も期待されているのが病気予測です。
患者のカルテや診断状況を過去のデータと照らし合わせ、マルチモーダルで判断することにより、医者でも見逃してしまっていた病気の早期発見や適切な対応が可能です。
詳しくはこちらでも解説しています。第8回「AIが診断支援と病気予測を行う日へ」
特に、コロナウイルスの影響により直接接触を嫌う傾向にありますので、AI技術を搭載したロボットが今後は活躍すると考えられています。
工場×マルチモーダル
AIの得意分野の一つは二次元分野です。
カメラを利用しての検品作業や異物検知などはすでに多くの工場で導入されています。
ディープラーニングによって、画像認識AIや音声認識AIは90%を超える高い技術精度を誇っています。
これらを活かして製造ロボットの管理や検品作業もAIでこなしていましたが、今後は従業員の勤怠管理やシフト管理などもAIでまかなうことが出来れば、大幅な人件費削減・コストカットにつながります。
ただの製造業務だけをおこなっていたロボットに様々なマルチモーダルを搭載することで、複数の技術的業務をさせることも可能です。
しかし、AIで人手不足が解消できるとともに、雇用される人数も減ってしまう問題があります。
単純な労働はAIに任せる代わりに、AIのメンテナンス業や機械に詳しい専門職のニーズが増えると予測されています。
コミュニケーション×マルチモーダル
AIが次の段階として目指しているのが、「自然なコミュニケーション」です。
チャットボットや人型ロボットのように、一定のフレーズに対しては反応することができても、複雑な会話や臨機応変に返事をするというのは難しかったのです。
しかし、ディープラーニングによるAI技術の向上によって様々なケースの会話を学習しています。
マルチモーダルによって会話する人間の表情や声をマルチモーダルで総合的に判断するところまで来ています。
より研究が進めばその場の状況や相手の心情を察して返事をするという、より自然で高度なコミュニケーションが可能になるとされています。
こういったコミュニケーションロボットは、介護施設で身寄りのないご老人の話相手だったり、企業の受付窓口だったりと様々な場面での活躍が期待されています。
マーケティング×マルチモーダル
様々な市場や顧客情報を分析して売れる仕組みを作るマーケティング業務ですが、マルチモーダルを使えばより多角的な面での分析が可能になります。
単純な売り上げの数字だけを見るよりも、動画を使っての顧客情報の流入や表情の調査、会話情報などから顧客満足度や次の売り上げ予測が容易に可能になります。
AIによる客観的な分析と過去何十年、何百年という情報量は人間では到底処理しきれない数字です。
こういったデータ関連はAIが得意とするところですが、今までにない新しいことを企画したり、何かを生み出すことに関しては人間のほうが向いています。
近い将来には集計や分析はAI、企画や立案は人間、といったような分業制を取り入れるかもしれません。
クリスタルメソッドのマルチモーダルへの取り組み
各企業や研究機関においてマルチモーダルは日々開発されています。
各企業が開発したAIのディープラーニングの内容はそれまでの研究の成果であり財産です。
そんな弊社もマルチモーダルの開発に注力しており、高い成果を出しています。
ここではそんな研究の成果の一部をご紹介します。
弊社では、マルチモーダルAIに特化した研究開発を行っております。
社内のDX,IoTをお急ぎですか?こちらからお問い合わせください。
お問い合わせ
マルチモーダル感情認識
弊社の音声認識は高い精度を誇っており、実際の企業様に検品の際の異音判定や、機械の動作音の確認など幅広く採用されています。
その音声認識の技術をコミュニケーションにも活用すべく、人間が発する声を分析し、話している内容と声の調子から相手の感情を認識するという技術に応用しています。
正確に人間の言葉を認識し、会話の抑揚や強弱を分析する高い技術が必要になりますので、AIが正しく意味を理解できていないケースもあります。
しかし、弊社は微妙な感情の違いも細かく読み取り、違和感のないコミュニケーションに成功しています。
※実際の音声サンプルがございます。
音のAI・深層学習
対話型AIへの導入
弊社では「ロボットをより人間に近づける」をテーマに日々AIの研究開発をおこなっております。
その中でも代表的なものが対話型AI “HALさん”です。
プロモーション動画はこちら
現在、AIは多数の電子機器に搭載されており、なくてはならない存在です。
日本のAIの普及数は5千万世帯と言われており、AIの利用者数は約8千万人にものぼります。
これは人口の約70%が何かしらのAIを使っているという計算になります。
この数字はもっと伸びると予想されており、一家に1台AIを搭載したお手伝いロボットが家庭にいる未来もそう遠くないでしょう。
そんなAIロボットを企業でも家庭でも積極的に採用していただくべく、AIについて日夜研究を続けています。
中でも注目しているマルチモーダルは、AIとのコミュニケーションにおいて非常に重要だと考えております。
これまでのシングルモーダルでは「顔色を窺う」「空気を読む」といった人間独自のコミュニケーションをAIは理解できません。
しかし、人間は細かい表情の違いや、発した言葉以外の情報を読み取って、初めて本当のコミュニケーションが成立しています。
この細かい感情を読み取るためにはマルチモーダルが不可欠です。
目線、眉の動き、表情の強張り、口元の動き、声の大きさ、抑揚、発した言葉の内容。
これらをマルチモーダルで総合的に判断することで、より人間に近いコミュニケーションが出来るようになります。
対話型AI HALさんもこれらを意識した研究がされており、一定のオフィス業務に関しては実働可能なレベルに達しています。
ご依頼があれば、各業務や様々な業種に特化した機能を備えることも可能になります。
今はまだモニター越しですが、さらに研究が進めば人型ロボットのようにアンドロイド化した対話型AI HALさんが実現します。
アンドロイドそれぞれにHALさんを搭載することができれば、日常会話が出来る高性能なお手伝いロボットとして人間と共存できる日がくるでしょう。
感情認識以外のマルチモーダルの研究も同時に進めており、AIは便利なロボットではなく、生活をともにする家庭のパートナーとなる日もそう遠くないかもしれません。
マルチモーダルAIで様々なことが可能になった
ここまでマルチモーダルの意味と歴史、マルチモーダルの今後や弊社の取り組みについて解説してきました。
マルチモーダルが確立されたことで精度が飛躍的に上昇し、様々な可能性が広がりました。
業務用ロボットの開発はもちろんですが、今は一般の方にもAIが広く浸透しており、家電のみならず自宅をAIで管理するといったこともあるかもしれません。
そうなった際に、AIと人間が自然にコミュニケーションを取り、共存できるような未来を描きながら、日夜研究開発に精進してまいります。
この記事を読んで、AIやマルチモーダルに興味を持っていただければ幸いです。
人工知能学会金融情報学会第20回での発表について
感情によるマルチモーダルAIを利用したIPO株価推定
1. 研究の動機
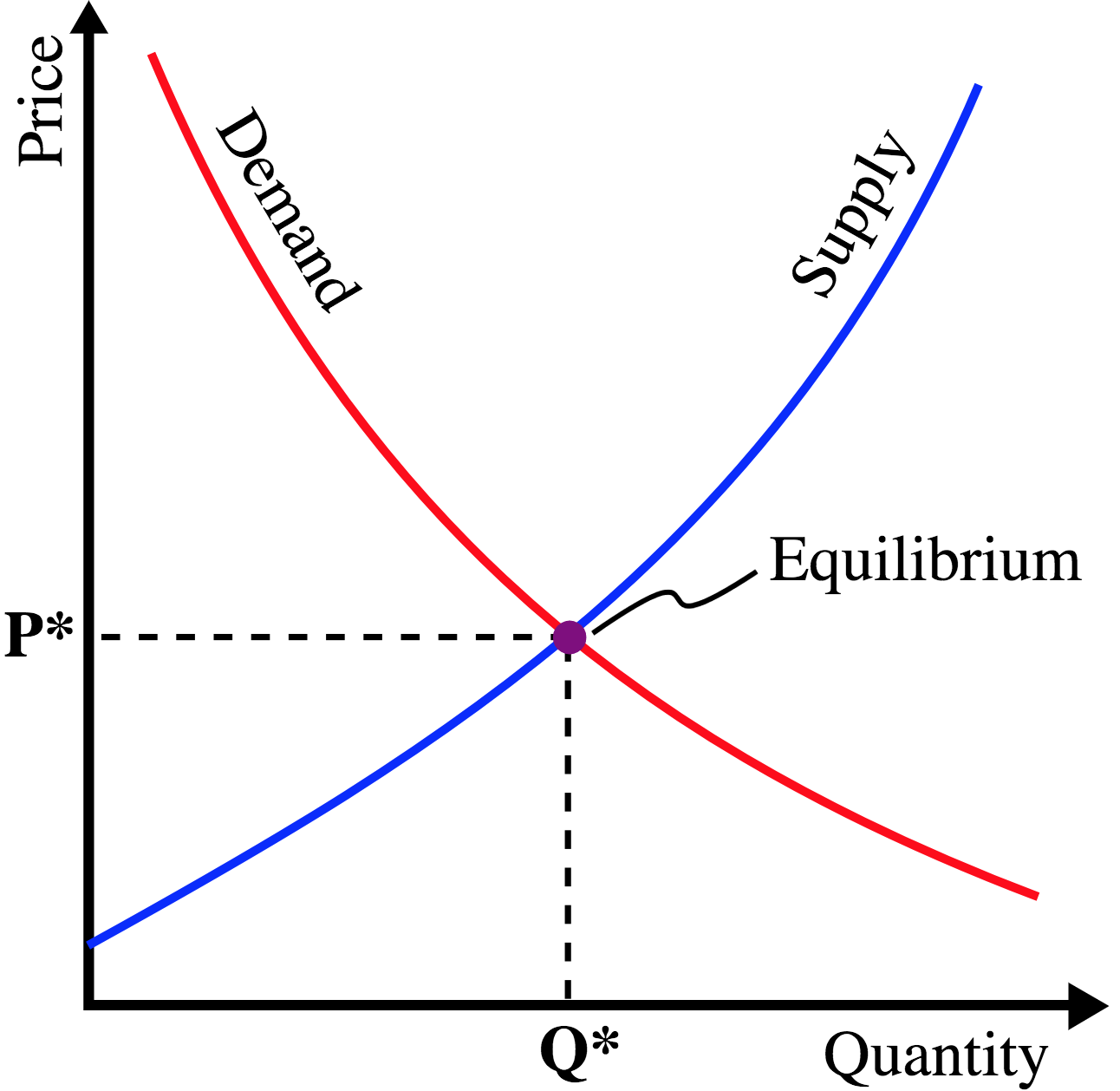
従来の経済学では、需要と供給によって決まった価格を判断基準として、人間は売買行動を実行している。一方、感情によって売買行動をとるという研究も存在している。非言語の情報が株価にどのような影響を与えるのだろうか。価格以外の要因によるIPO時の株価変動について検証する。
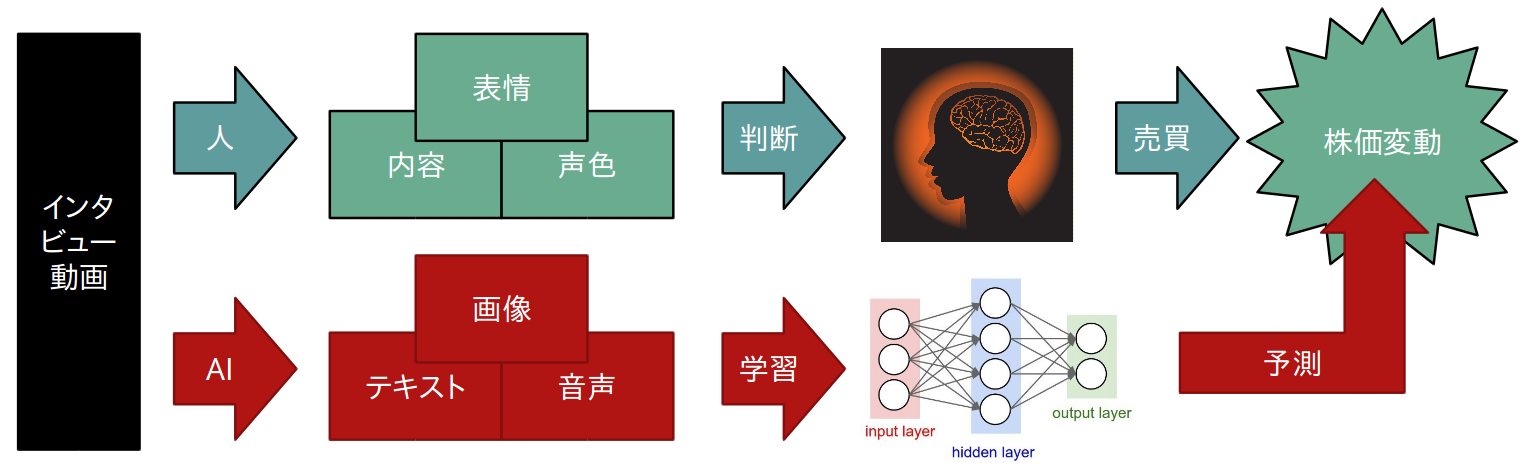
2. 研究発表の対象 研究概要
音声・画像・テキストなど、複数のデータからマルチモーダルな学習モデルを構築し、新規上場企業のインタビュー動画と株価変動の相関について検証。登壇者の表情や声色、発表内容から、株価の変動を予測する。
番組全体のデータが翌営業日の価格変化に相関があるかをSVM・ロジスティック回帰を使用して検証する。
番組放送中のデータが一分足の価格変化に相関があるかをRandom Forest・XGBoost・DNN・LSTMを使用して検証する。
3. ストックボイスTVについて(IPO)
STOCK VOICE TVとは、新規株式公開等に際して、企業の代表者などが自社の事業計画等を発表する放送である。放送時間約13分で、大方の放送は後場に開始する。

4. データ準備
Ⅰ. ストックボイスのサイトをスクレイピングし必要情報を抽出
Ⅱ. YouTubeから動画データを一括取得
Ⅲ. YouTubeからⅡの会社証券コード・会社名・上場日等の必要情報をプログラミングにより取得・作成
Ⅳ. ストックボイスTVの動画を映像と音声に分離
Ⅴ. 1分足の検証のため、ダウンロードした動画を1分ごとに分割
Ⅵ. 区切った動画をGoogle Speech APIに入力しテキストを取得
Ⅶ. 1分毎に区切った音声をGoogle Speech APIに入力し、テキストを取得
一分準備データ
Ⅷ. 日足評価用に全体音声、テキストを用意
Google Webストレージに音声データをアップロードし、テキスト表現を取得
5. 各種特徴量抽出・株価データ準備
- テキストデータは、Google Emotionによって特徴量抽出する。
- 音声データは、感情特徴量を利用する。 パワー・MFCC
- 映像データは、一分評価用・全体評価用ともに5秒ごとに特徴抽出Microsoft Emotion APIを利用する。(複数人の場合は平均を取得)


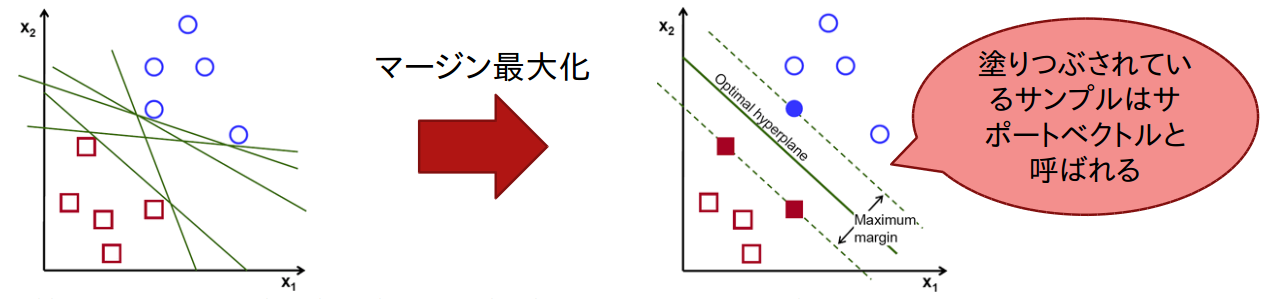
6. SVM(Support Vector Machine)
SVMの最大の特徴は、マージン最大化を行うことである。マージンの最大化により、比較的データ量が少ない場合でも汎化性能を高めやすい。カーネルトリックを用いることで、非線形に拡張することが可能である。
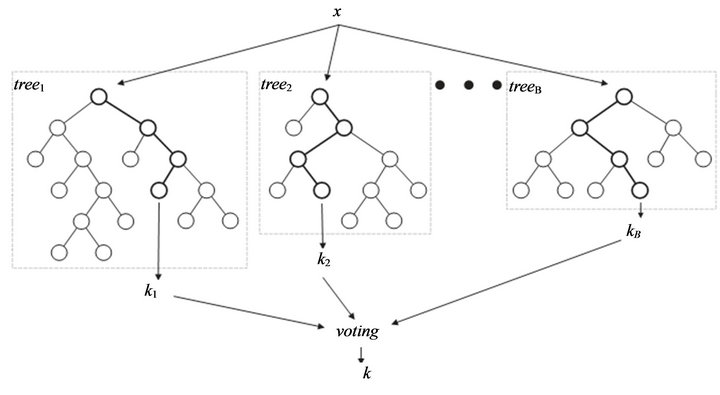
7. Random Forest
Random Forestでは決定木を大量に生成し、以下のように出力を決定する。
→分類問題:多数決
→回帰問題:平均値
また、各特徴量の重要度を算出することができる。
参照:https://aichamp.wordpress.com/2017/03/09/treatment-of-categorical-variables-in-h2os-drf-algorithm/
8. XGBoost
XGBoostは、Kaggleと呼ばれる、データ分析のコンペティションが多数開催されているプラットフォームでよく使用される。GBDT(Gradient Boosting Decision Tree)を使用していて、計算速度やモデルの予測精度の面で優れている。R、Python等で利用可能である。
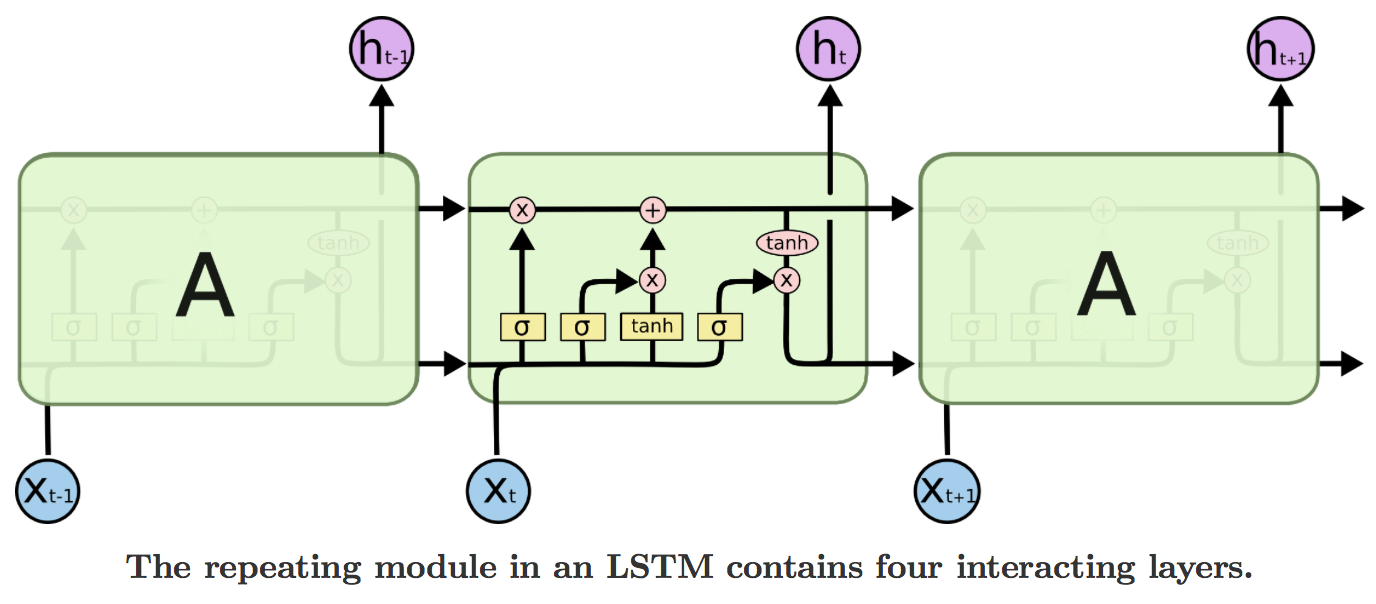
9. LSTM(Long Short-Term Memory)
LSTMは文章や音声等、時系列データを扱うことができるRNNsの拡張である。RNNsの勾配消失問題が緩和され、長期依存する時系列も扱える。Tensorflow, Chainer等のフレームワークで比較的楽に実装することが可能である。
参照:https://becominghuman.ai/only-numpy-deriving-forward-feed-and-back-propagation-in-long-short-term-memory-lstm-part-1-4ee82c14a652
10. 検証(日足)
・データ:ストックボイスTVから取得した196社分のデータ
196社のうち、123社がIPO銘柄、73社がNew Stage銘柄
全データのうちテストデータの割合が2割の場合、3割の場合の検証をした
またIPO銘柄のみの場合、全銘柄を使用した場合の検証もした
・モデル:ロジスティック回帰・SVMを使用
・予測:翌営業日の株価が上昇しているか否か
・評価指標:2値分類の正答率
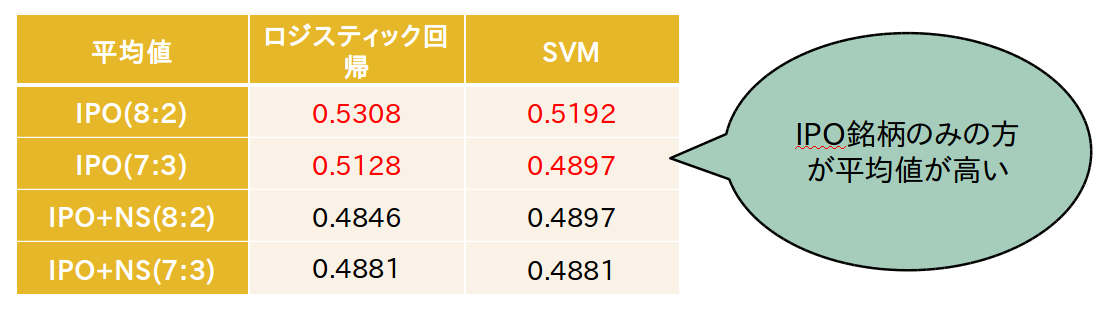
11. 結果(日足1、日足2)
IPO銘柄のみでの検証結果は、銘柄数が少ないため、結果にばらつきが生じた。ロジスティック回帰がSVMを上回る結果となった。
IPOとNew Stage銘柄での検証結果は、銘柄数が少ないため、結果にばらつきが生じた。IPO銘柄のみの場合よりも、予測精度の平均値が低かった。


12. 結果(日足の考察)
日足の検証結果のうち、平均値を以下にまとめた。ロジスティック回帰は53%の水準である。登壇者の表情等がIPO時とNew Stage時で異なる可能性がある。
13. 結果(1分足)
・データ:ストックボイスTVから取得した138社分のデータ
・予測:放映中における各1分間の株価変動を予測
クラス0:株価の変動が1pip以内の場合
クラス1:株価の変動が1pipより上昇
クラス2:株価の変動を1pipより下落
ストックボイスTVの放映中に株価の変動がない場合は、次に株価の上昇・下降があった時点の価格や、公募価格を参考にする。
・評価指標:3クラス分類の正答率
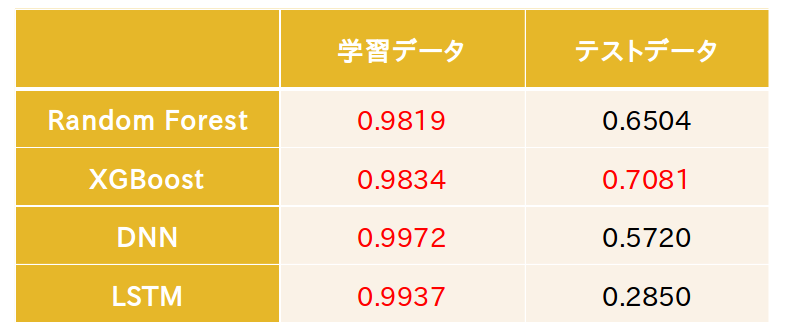
14. 検証(1分足)
1分足での検証結果は、LSTMはテストデータの予測精度が非常に悪かった。すべての手法においてOverfittingしているように見える。(学習データとテストデータの値差)
下図はXGBoostの予測結果である。
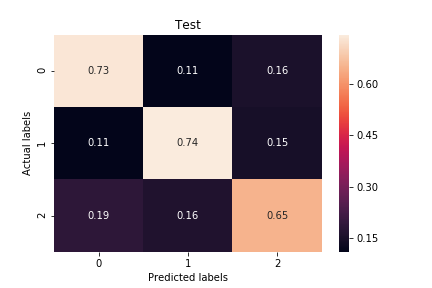
15. 検証・結果
一分・Xgboost70%の精度AIが予測した値が一番よかった会社が以下の会社である。
証券コード 6195:ホープ 上場日 2016/6/15
放送開始後上がり続けている。(動画を参照)
16. 考察
改善ポイント
- 発話区間を区切り、意味のあるコンテクストに変更 (ひとまとまりの発話内容が終わった次点の1分足の予測)
- 映像を解析し、プレゼンのOCR読み取りを行い、内容を解釈することにより価格推定に結び付ける
- 発話内容を感情ではなく、決算短信や有価証券報告書などで推定する
ここまでご愛読いただきありがとうございました!
よろしければ弊社SNSもご覧ください!
Twitter https://twitter.com/CrystalmethodZ9
Facebook https://www.facebook.com/クリスタルメソッド株式会社-100971778872865/
Study about AI
AIについて学ぶ
-

ディープフェイク=怖いだけじゃない?実は“必要とされる理由”と未来の可能性
ディープフェイク=怖いだけじゃない?実は“必要とされる理由”と未来の可能性 ディープフェイク技術。名前を聞くと、どこか怖いイメージを持っている人も多いのではない...
-

未来が爆誕する場所へ——テクノロジーで体感せよ!大阪・関西万博2025
「未来がここにある——テクノロジーで読み解く大阪・関西万博2025」 2025年、大阪にやってくるのは単なる「博覧会」ではない。それは、未來の社会をまるごと体験...
-

AIエージェントの登場!AI企業が目指す“自律型AI”。人間はもうインターフェースなのか?
かつてAIは、ただの道具だった。与えられたプロンプトを実行し、間違いなくタスクを処理する”静かな天才”。だが今、その構図が静かに崩れ始め...