blog
AIブログ
”招待講演” 国際人工知能学会ACII2022
ACII2022国際講演会での発表
2022年10月18日-21日に開催されたAffective computing and intelligence interaction(ACII2022)
感情コンピューティングや、マルチモーダル学習における人間と機械の交流に関する国際会議にて以下の論文を発表しました。
※スライドショー版埋め込みあり
Using Convolutional Neural Network for improving the inference of interrogative sentences in a dialogue system
I. INTRODUCTION
A dialogue system has to correctly infer responses to users’ utterances and respond properly. For example, in the case of a questioning utterance, the system should make answers corresponding to the questions. This paper describes a method to classify sentences from users’ utterances into interrogative sentences or declarative sentences as “the inference of interrogative sentences”. Our research focuses on users’ questions and tries to find the way to improve the quality of the inference of interrogative sentences. Generally speaking, an intonation rises in interrogative sentences while it does not in declarative sentences in Japanese. Therefore, the pitch of a sentence can be useful information for the inference of interrogative sentences. On the other hand, there exist some interrogative sentences with rising intonation and some declarative sentences with falling intonation. For example, an interrogative sentence that ends with “Sou desu ne”1 does not have the rising intonation while a declarative sentence that ends with “Sou desu yo” 2 has. To classify these cases correctly, it is useful to focus on the end of a sentence. For instance, however, “Shinjite imasu”3 is a declarative sentence, this sentence becomes interrogative if it ends with “ka” or “yone”4 . This research builds the definition of interrogative sentences proposed in the related research [1] as a baseline model, and proposes the method that adopts Convolutional Neural Network with the last twelve pitches and Japanese characters in Latin alphabet as inputs (which we call Romaji in this paper). We are going to propose the hypothesis that our approach outperforms previously proposed method. To evaluate our method, this research utilizes a rule-based method to compare their performance.
1
interrogatory phrase
2
confirmation phrase
3
I believe you
II. RELATED RESEARCH
One of the related studies [1] discusses that an interrogative sentence is defined by interrogative words, interrogative ending particles, and intonation. This research also proposes the definition of an interrogative sentence. We adopt this setup for the rule-baled method to compare with our model. Some of the previous works on the inference of dialogue acts by machine learning often adopts n-gram words. The research by Isomura and others [4] adopts uni-gram and bi-gram words as inputs of which frequency is more than two times, and the utterance preceding the input. They used the Conditional Random Field (CRF) algorithm and obtained around 76% of precision. Other methods such as the Support Vector Machine (SVM) and Naive Bayes were applied with the same test data as CRF but these methods observed lower precision, 70%, and 60%. This was because they did not use the utterance preceding the input [4]. Further research by Sekino and others [5] utilized Isomura’s method by adding new inputs which are at least one of the number of characters from utterance, that of words, and the order of the utterances. Therefore, the method by Sekino shows better results especially in adding the number of words and the order of the utterances [5]. These works did not discuss the relationship between specific inputs and the inference of a dialogue.
4postpositional particles
III. PROPOSED METHOD
Our approach uses the last twelve pitches and the last twelve Japanese characters in Latin alphabet, we call this as Romaji in this short paper, as inputs for the inference of interrogative sentences from users’ utterances. Figure 1 shows the flow of the implementation of our proposed method. This model uses a general Convolutional Neural Network (CNN) to deal with pitch components as two-dimensional vector. These inputs are processed in multiple layers such as the embedding layer, convolutional layer, pooling layer, and affine layer for the inference of interrogative sentences.
A. Embedding Layers
The embedding layer converts inputs to make them possible to be processed by CNN. The pitch components are convolved by using 3×3 channels. The other input is in string form which makes it impossible to be utilized in CNN. Therefore, the embedding layer changes it into a float form. Finally, the twochannel data which consists of pitch and characters is obtained. The flow of this implementation is shown in Figure 2.
IV. EVALUATION
A. Data
The data used for the experiments has been collected from
voice actor dialogue corpus which contains the free dialogue
between humans [2], and the Japanese voice database as
dialogue corpora [3]. F0 pattern inference is adopted to collect
utterances’ pitch.
B. Rule-based
The baseline is set to evaluate the proposed method according to the definition proposed by Yingrui Ma [1]. The rule is
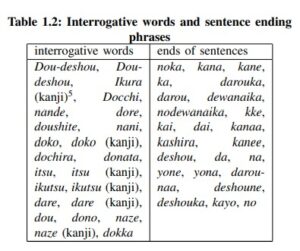
shown in Table 1.

C. Experimental Results
The confusion matrices were used to obtain the precision, recall, and F1 score are calculated to evaluate the methods. The test used randomly chosen 200 samples containing 100 of both interrogative and declarative samples. Table 2 shows the result.
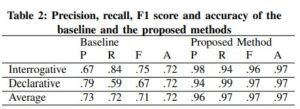
As shown in the table, all the values observed in the proposed method are superior to the baseline method. More specifically, the high record of precision and accuracy in the proposed method implies there is less misclassification than in the baseline method.
The input values are divided and tested by using the same samples to evaluate our proposed method. The inputs are pitch and Romaji transliteration. Table 3 shows the result.
According to Table 3, the result shows that romaji obtained higher scores in all evaluation values than pitch. On the other hand, the proposed method performs better than when using only Romaji.
Additionally we calculated the error rate for each case has been calculated and stored in Table 4.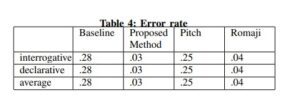

Table 4 shows that the proposed method exhibited smaller error rate and there is a slight difference in the romaji case while other cases had higher error rates. The difference between the ordinary baseline case and our proposed method is 25%.
D. Error Analysis
Rule-based method has misclassified the utterances which are interrogative but have falling or stable intonation, and which are declarative but have rising intonation. On the other hand, our proposed method has misclassified the utterances which are interrogative but have rising intonation while the declarative utterance with falling intonation has been misclassified. From these errors we can conclude that the rule-based method tends to rely on the pitch component while our proposed method tends not to value the pitch component as Table 3 suggests.
E. Discussion
According to the result described in Section C, our proposed method exhibited a lower error rate and higher precision, recall, F1 score and the accuracy than the previously proposed baseline method. These results indicate that our proposed method is more suitable for the recognition of interrogative sentences than the commonly used rule-based method. However, the results has shown that our proposed method obtained high scores in all types of evaluation scores which could be related to overfitting and the analysis of this possible problem should be investigated in the future. Moreover, we can propose the hypothesis according to the results presented in Table 3 and the discussion from the ”Error Analysis” section that the pitch component helps the Romaji component to decide if a sentence is interrogative or declarative when the information from Romaji is not sufficient. It is because our proposed method which is the concatenation of the pitch and Romaji transliteration has recorded slightly higher values in all of the average evaluation scores than Romaji only. In addition, as described in the ”Error Analysis” section, the pitch component is not the main reason of the misclassification in our proposed model. However, no experiments to investigate the relationship between the pitch and Romaji components have been yet implemented and this remains a task for the future. Furthermore, this research has tested our proposed model and the baseline approach only with test data in Japanese while it is better for dialogue systems to be able to perform the task in other languages. By adopting our model to other languages we plan to test if the proposed method is not limited to Japanese language.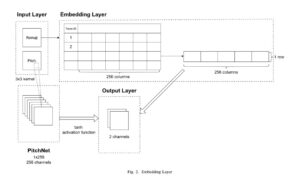
V. CONCLUSION AND FUTURE WORK
This paper proposes a model for a dialogue system to determine whether a sentence from a user’s utterance is interrogative or declarative. A baseline model based on a definition from the existing work [1] is used to evaluate our model. Our method adopted inputs of twelve components of pitches and Romaji transliterations to be fed for a convolutional neural model. An evaluation experiment using a 200 data sample revealed that the proposed model is superior for interrogative utterance classification when compared to a common baseline method and the experimental results confirm our hypothesis that combining pitch and transliteration can improve the performance. In addition, ablation study indicated tha the pitch component can help Romaji to classify sentences. As the future work we can plan to investigate the relationship between the pitch of an utterance and its transliteration. Also we want to experiment with other languages to confirm if the proposed method can extended beyond to check the performance in other languages.
最後
ここまでご愛読いただきありがとうございました!
よろしければ弊社SNSもご覧ください!
Twitter https://twitter.com/crystal_hal3
Facebook https://www.facebook.com/クリスタルメソッド株式会社-100971778872865/
Study about AI
AIについて学ぶ
-

DeepAI提供形態のご紹介
DeepAIは、さまざまな場面でご利用いただけるよう、提供形態をいくつかご用意しております。バーチャルヒューマンを利用することによって、自動化された顧客対応を可...
-

社長AIが社員の質問になんでも答えます!
社員だけでなく、社内外の方とコミュニケーションがとれます。クリスタルメソッドでは、企業の社長さんをDeepAI化するプロジェクトを行っています。社内外でのイベン...
-
芸能人をAIアバターにして活動の幅を広げます
俳優業やイベントの出演などに忙しいタレントさんをDeepAI化 一度自分のAIをつくれば、時間や場所にとらわれることなく、AIが活動してくれます。タレントが常に...

