blog
AIブログ
AIと音声合成の関係について説明します!
こちらは、弊社の音声合成エンジンでつくった、標準語を関西弁に変換したものです。
このように音声合成エンジンでは、テキストをコンピュータに読ませるだけでなく、ピッチを変えたりすることも可能です。
本記事では、「音声合成」について、実際に弊社で開発しているものの例を交えて説明していきたいと思います。
音声合成とは?
音声合成とは、あるテキストに対して音声を生成する技術のことです。
その歴史は古く、1800年以前から機械によって人間が発声する音と同じ音を生成しようとする試みは行われていました。
その頃の機械は人間の声道、唇、舌などの発声に関わる器官を模したものでしたが、その後、計算機の性能の向上により、統計的手法が用いられるようになり、音声合成へのアプローチは大きく変化したといえます。
特に、隠れマルコフモデル (hidden Markov model; HMM) を用いたシステムはHMM音声合成と呼ばれ、1990年代合成音声が実用化され始めた頃から広く研究、利用されてきました。
近年、HMMに替えて、ディープニューラルネットワーク(deep neural network; DNN)、すなわち深層学習を用いる手法が活発に研究、利用されるようになり、音声合成の分野も大きな変革期を迎えているといえます。
音声合成を行うAIの背景
本節では、音声合成を行うAIの背景について説明させて頂きます。
AIを構成する重要な要素のひとつとして人間の脳構造を模したニューラルネットワーク(Neural Network, NN)と呼ばれるものがあります。現在はこのニューラルネットワークを発展させた畳み込みニューラルネットワーク(Convolutional Neural Network, CNN)と呼ばれるネットワークがディープラーニングで広く使われております。
当初、CNNは画像認識の分野で大きな成果を収めたネットワークだったのですが、その性能の高さから最近では音声の判定など様々な問題へ応用されています。
当初、音の学習でもCNNが用いられていたのですが、時間的に静止した画像データの処理に大きな強みを持っていたCNNに対して、時間軸を有する音声データは経時的な処理を必要としました。そのため、CNNを改良したネットワークを開発することが必要となり、再帰型ニューラルネットワーク(Recurrent Neural Network, RNN)が登場しました。
RNNでは、音声データ中のある時刻での波形を学習する際、その直前の時刻の学習として得られたパラメータを(隠れ層からの入力として)利用するという仕組みが加えられました。これによって音声データの連続的な変化をひとまとまりにした、より意味のある学習が可能となりました。
しかし、RNNにも学習の減衰や計算力の爆発的増大などという新たな問題が浮上したため、さらなる改良が必要となりました。そこで生まれたのが、LSTM(Long Short-Term Memory)というネットワークです。これは前述のRNNの学習減衰と計算量の増大を抑制したもので、現在、弊社の音声合成AIに組み込まれているネットワークとなります。
声質変換とは?
ここでは、AIにおける音声合成の活用事例として「声質変換」をご紹介します。
この声質変換はある人の音声データを学習させることで、入力音声・テキストをあたかも学習として入力した人がしゃべっているように変換できる技術です。
よりかみ砕いた表現をすれば、「AIによって作られたある種のボイスチェンジャー」と考えてもらえればイメージがわきやすいのではないかと思います。
従来、声質変換を行うためには、入力となる音声情報と出力となる音声情報を結びつけるために多くの情報を必要としていました。
しかし、AIを用いることで必要な情報量は格段に削減され、決して音声情報が多くなくともモデルを作ることができるようになりました。
この技術を応用して、一般的に音声情報が多くない一般人を模したAIを作ることができるようになったため、亡くなった人の「失われた声」や結婚式などの「当時の思い出」を再現することができるのではないかと期待され、研究が進められています。
では、音声合成の例として弊社で開発したAIを用いてハスキーな女性の声をプレーンな声に変換した、「声質変換」についてご紹介させていただきます。以下の音声はハスキーな女性の声をプレーンな声に変換している例です。
ハスキーな女性の声
プレーンな女性の声に変換したもの
いかがだったでしょうか?
他にも、音のAIの活用例として声質変換の他に入力文章の読み上げを行う朗読や、異音検知など様々な応用事例があり、日夜研究が進められています。
ノイズ抑制
もう一つ、音声合成の活用例として有名なのが「ノイズ抑制」いわゆるノイズキャンセルです。
「ノイズ抑制」は低品質な音声からフィルタリングを行うことで高音質な音声を生成させる技術です。具体的な例として、劣化したマイクから入力されたノイズが混じった低品質な音声であっても、正常なマイクから入力されたような高音質でクリアな音声へすることができます。
以下に雑音の混じった音声と、弊社のAIを用いてフィルタリングを行いノイズを抑制した音声の例をご紹介します。
[上]ノイズ抑制前の雑音の混じった音声 [下]ノイズ抑制後の高品質な音声
音声解析に重要なメルスペクトログラム
音は空気中を伝わる波の重なりで出来ている、というような説明を耳にしたことはないでしょうか。
コンピュータでは、音声ファイルを周波数の異なる波形の重なりで表現しています。深層学習では、このような個々の音声の波形を以下のような「メルスペクトログラム」へと変換し、テキストデータの対応関係を学習させることで、テキストデータの入力から音声を合成して出力できるようになります。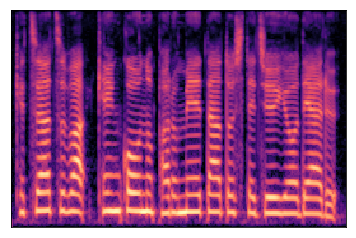
メルスペクトログラムでは、横軸が時間、縦軸が周波数、色が音の大きさ(振幅)として表現されます。音の大きさは黒から白にかけて大きくなっていきます。
音声合成の活用場面
では、音声合成はどのような場面で利用できるのでしょうか?
まず、弊社で開発しておりますHAL3, DeepAICopyにこのような技術が使われています。
(HAL3, DeepAICopyについて詳しくはこちらをご覧ください。HAL3, DeepAICopy)
HAL3, DeepAICopyはいずれも人とコミュニケーションをとることを前提としています。
全く人と同じように違和感なくAIともコミュニケーションを取れるようにするためには、「機械音っぽさ」のない自然な音声が必要不可欠です。そこで、先に説明した音声合成の技術が利用されています。
また、機械による電話応対、カーナビの音声の指示などで今まで人が読み上げていた部分もAIで代替することができます。
さらに、福祉の面でも活用が期待されます。例えば、現在目の見えない方や失語症の方へのサポートとしてアプリなどの読み上げサービスが数多くありますが、音声合成によって、より自然なイントネーションでテキストを読み上げることができます。
病院での音声合成
厚生労働省の2017年の資料によれば、日本の雇用者総数は約5800万人であると言われています。産業別にその雇用者数を分類しますと、製造業が約1006万人でトップを走り、それに続くのが卸売業・小売業の約988万人、そして医療福祉の約786万人となります。このつの分野は日本社会を支える重要な柱ですが、少子高齢化により、慢性的な人手不足に悩まされている現状があります。
私たちの健康を支える病院は特にそうした人手不足課題と先細りの問題が指摘されている組織の一つです。この人手不足は病院経営の問題だけではなく、医療サービスの品質にも直結する大きな問題となります。日本医療労働組合連合会の調査資料によれば、医療事故の原因として報告されている最も高い原因項目は「人手不足による忙しさ」とあります。ひとりの医師や看護師にキャパシティを超える仕事が課せられている結果、医療ミスのリスクが高まる事を意味しています。
厚生労働省の資料にも「病床あたりの看護師数が高い程、患者の安全性が高まる」という統計が示されていますから、病院の人手不足問題はこれから先、必ず解決に向けて歩まねばならない社会課題だと言えます。この気難しい社会課題に対して、限られた作業の効率化と正確性を絶え間なく行えるAIというテクノロジーは大変有効であり、活路となり得ます。
病院においてAIが活躍する領域は、第一にルーティンワークを伴う場所です。一定のルールのもとに特定の反応が要求される医療事務の領域は、特にAIが得意とする動作性を有しています。単純作業とルーティンワークが減少すれば、余剰分の人員や予算を他の場所に回せますので、安定した病院経営と医療サービスの品質維持に貢献をします。
病院の現場では、医師や看護師の「声」や「仕草」が、患者にとって非常に重要な意味を持ちます。柔らかな声や仕草によって自然な会話が行われれば、診断や治療も促進される事になるのです。そこで、弊社が焦点を当てているひとつの領域が「音声合成」です。
弊社は対話AI「DeepAICopy」に代表されるように、自然な声を自動生成する音声合成の分野に力を入れています。
現在は実在する人間の声や容姿、そして仕草を取り込むという深層学習を行っていますが、ゆくゆくは音声を脳波と連携させるアプローチも視野に入れています。
音声合成の品質をより高める事で、より自然なコミュニケーションのスタイル確立を目指すのです。
弊社での取り組み
弊社ではこの技術を応用し、アクセント推定や音韻区切れ検出などを研究することにより、業界内で高い水準の音声を生成することに成功しております。
従来の音声合成モデルでは、学習時に使用するテキストや音声の種類によって、合成される日本語音声のアクセントがおかしくなってしまうといった問題がありました。
そこで、従来の音声合成モデルではテキストのみを学習させていたのに対し、弊社の音声合成モデルTTS(text to speech) はテキストに加えてアクセントの情報を学習させることによって、合成される日本語音声のアクセントを改善しました。
弊社の対話型AI DeepAIにも利用されています。
https://crystal-method.com/deepaicopy/
「従来の音声合成モデルを使用して合成した音声」と「テキストとアクセントを学習させた音声合成モデルを使用して合成した音声」のサンプルを以下に添付いたします。
【従来の音声合成モデルで合成した音声】
・「母の誕生日に、手紙と鞄をあげました。」→「誕生日」のアクセントがおかしい
・「ご飯を食べようとした時、塩を入れ忘れたことに気づいた。」→「ご飯」のアクセントがおかしい
・「あの店のハンバーガーは大きすぎるから、一人では全部食べられないよ。」→「食べられないよ」のアクセントがおかしい
【テキストとアクセントを学習させた音声合成モデルで合成した音声】
・「母の誕生日に、手紙と鞄をあげました。」
・「ご飯を食べようとした時、塩を入れ忘れたことに気づいた。」
・「あの店のハンバーガーは大きすぎるから、一人では全部食べられないよ。」
また、被験者に、「従来の音声合成モデルを使用して合成した音声」と「テキストとアクセントを学習させた音声合成モデルを使用して合成した音声」を聴いてもらい、それぞれの合成音声の質を5段階で評価した結果を以下に添付いたします。
以上のように、テキストに加え、アクセントを学習させた音声合成モデルを使用することによって、合成音声のアクセントを改善することができ、より人間の発話に近い音声を合成することができます。こちらで説明した弊社の最新の音声合成モデルは弊社の対話型AI HAL3の「朗読機能」にも使用する予定です。HAL3の操作方法などの詳しい説明については、こちらからフォームを送っていただくと、HAL3の資料をダウンロードすることができます。
また、以下のページにも様々な音のAIに関する弊社の取り組みをまとめておりますので、興味がございましたら是非ご覧ください。
音のAI・深層学習
よろしければ弊社SNSもご覧ください!
Twitter https://twitter.com/crystal_hal3
youtube https://www.youtube.com/channel/UCEGsdLiq1FHjsr-9ghbEqKQ
Study about AI
AIについて学ぶ
-

AI社員・AI上司とは何か?企業AIアバター活用の最前線【2026年】
2026年、「AI社員」という言葉をビジネスシーンで耳にする機会が増えています。AIが上司になる、AIが同僚として働く——そんな話題が現実のものになりつつある今...
-

Claude Codeの使い方|インストールからAI設計書生成まで完全実演【2026年最新】
この話について 第1話 / 全10話 2026年3月26日|著者: Kei Kawai|読了: 約15分 Claude Codeとは?2026年最新のAI開発ツ...
-

営業ロープレをAI化するメリットとは?課題をまとめて解決します
「営業ロープレをもっと効率的にできないか」という声は、営業責任者や研修担当者から絶えず聞かれます。ロープレは営業スキル向上に効果的な手法である一方、「相手の確保...