blog
AIブログ
AIによる物体検出の手法やモデルを解説します
皆さん、「AI」という単語を耳にすることが最近増えてきたのではないかと思います。しかし、その仕組みについて知りたいと感じても、「私には難しそう…」と敬遠してしまっている方も多いのではないでしょうか?
ここでは、画像内の物体について特定する技術であり、近年多く活用されているAIの物体検出について、説明していきたいと思います!
そして、実際の活用事例についてもご紹介します。
物体検出とは

先程軽く触れた通り、物体検出(物体検知)とは画像を取り込み、画像の中から定められた物体の位置と種類、個数を特定するという技術です。
物体の種類を分類するのは、画像分類でも行えます。しかし、物体検出ではそれに加え、
- 物体の領域の位置を絞り込む方法
- 認識対象以外の物体を排除する方法
というような手法を取り入れることで、対象物の位置・個数の検出を可能にしています。
画像分類について詳しく知りたい方はこちらから
画像分類について徹底解説!
物体検出の利用場面

物体検出は外観検査によく使われており、製造業や建設業、また医療などといった幅広い分野で活躍しています。
身近な例では、顔などの検出のためにスマートフォンのカメラにも利用されています。
また、自動運転の分野でも歩行者の検出に利用されています。
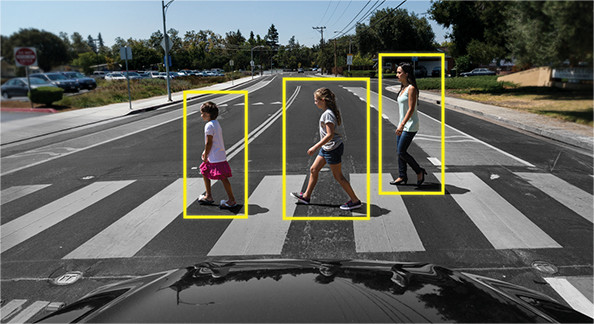
このように物体検出は現在もこれからの時代もとても重要な技術となっています。
物体検出モデルの紹介
物体検出は主に「CNN(畳み込みニューラルネットワーク)」というものを利用しています。(CNNとは、ディープラーニングで用いられるネットワークの中で最も有名なもので、画像処理に対してとても有効に利用できます。)
物体検出といってもいくつかもの手法があります。今回はその中から抜粋して紹介いたします。
◆R-CNN(Regional CNN)
R-CNNは、ディープラーニングを用いた物体検出の先駆け的な存在です。次のような手順で画像中の物体を検出しています。
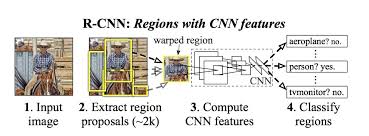
- 画像を入力する
- 画像の中から、物体が写っている領域の候補(Region Proposal)を抽出する(約2000個)
- CNNを用いてそれぞれの候補の特徴量を計算する
- それぞれの領域に何が写っているか分類する
これによって今まで(ディープラ−ニングを用いない方法)より高精度の物体検出ができるようになりました。しかし、それぞれの項目ごとで別々に学習する必要があり、学習に非常に時間がかかり、メモリの消費量も大きいという課題がありした。
これを解決するために新たにFast R-CNN、そしてFaster R-CNNという物体検出法が開発されました。Faster R-CNNの開発により、画像の入力から物体の検出まで一気に学習・推定ができるようになり、学習時間・メモリの消費量ともに大幅に削減されました。
R-CNN 論文:https://arxiv.org/pdf/1311.2524.pdf
Fast R-CNN 論文:https://arxiv.org/pdf/1504.08083.pdf
Faster R-CNN 論文:https://arxiv.org/pdf/1506.01497.pdf
◆YOLO
YOLOは、You Only Look Onceの略で、処理速度が非常に早いという特徴を持った物体検出法です。そのため、リアルタイムの物体検出をすることができます。
YOLOの物体認識の手法はR-CNNとは異なり、予め画像全体をグリッド分割しておき、各領域ごとで物体の種類と位置を求めます。
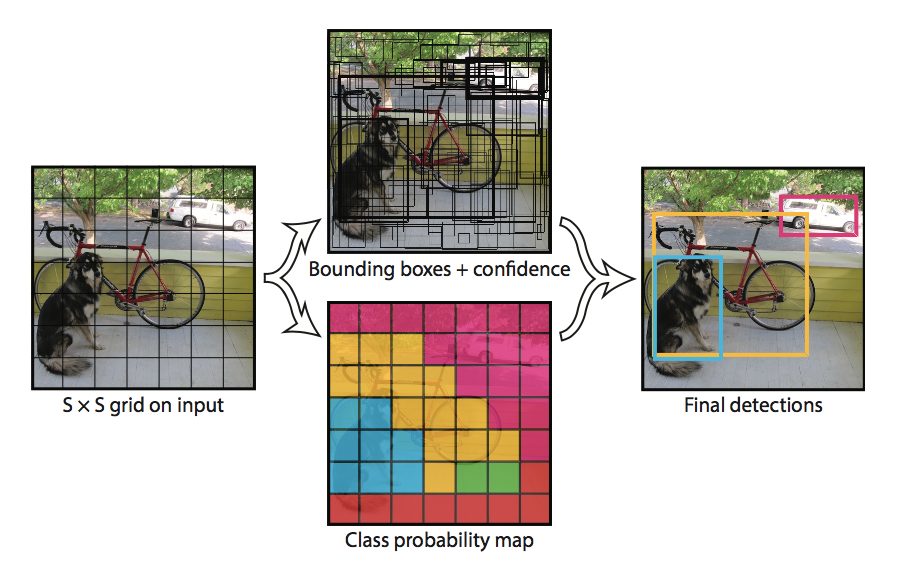
そのため、Faster R-CNNと比べると識別の精度は落ちます。特に物体が多数写っている場合精度が低くなります。しかしYOLOでは学習時に一枚の画像の全ての範囲を使うため、背景の誤検出は抑えることができます。

YOLOは最新のv5まで出ており、現在進行形で成長している物体検出方法です。
YOLOv5は、pythonで動作し、自作データセットを簡単に学習する事ができるのも特徴です。
論文:https://arxiv.org/pdf/1506.02640.pdf
◆SSD
SSDはSingle Shot MultiBox Detectorの略で、精度はFaster R-CNNと同等程度あり、処理速度も早いという特徴を持った物体検出法です。YOLO同様、リアルタイムでの物体検出が可能です。
物体検出の手法はYOLOと同じ手法を用いています。しかしながら、画像内に物体が多数あったとしても、YOLOより比較的正確に検出することができます。
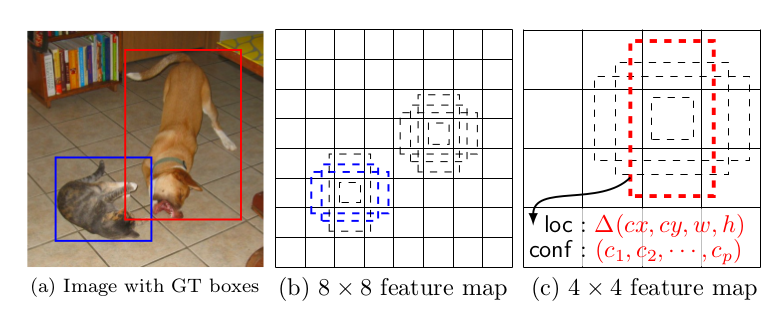
論文:https://arxiv.org/pdf/1512.02325.pdf
◆DETR
DETR(DEtection with TRansformers)とは、これまで、同じような物体候補領域を予測してしまう・候補領域をある程度設定しておく必要があるなど、問題点のあった物体検出タスクにおいて、Attentionを導入することでそのような事前・事後処理の必要ない学習を可能にしたモデルです。
事前のAnnotation方法によって、学習の精度が大きく変わってしまうといった物体検出の学習モデルにある問題を解消できる可能性を秘めています。
以下、2つの図がDETRの一連の流れです。上図は全体の流れ、下図はDETRで用いられているTransformerの流れです。

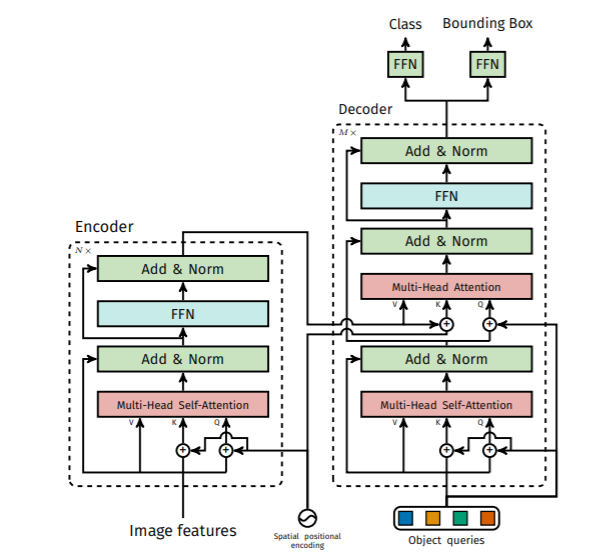
End-to-End Object Detection with Transformersより引用
Backbone : 入力画像をCNNによって低次元にエンコード
Encoder : 入力された特徴量をTransformer Encoderによって処理し、Decoderへと受け渡す。並列処理可能
Decoder : Encoderからの情報とobject queryを入力として、FFNへ処理を渡す。並列処理可能
FFN : Decoderの出力から、検出した物体の位置とラベルを識別
CNN出力のマップを、1×1 convolutionでdチャネルに圧縮する
Transformer encoderに、サイズH∗Wの特徴マップd個を、H∗W個のd次元特徴として入力する
Transformer encoderは、H∗W個の中間オブジェクト特徴(各d次元)を出力する
Transformer decoderへ、H∗W個の中間オブジェクト特徴とN個のobject queryを入力する
Transformer decoderは、N個のオブジェクト特徴(各d次元)を出力する
N個のオブジェクト特徴それぞれをFFN (Feed Forward Network) へ通して、N個のオブジェクト推論結果(クラス、矩形)が出てくる
encoderへの入力は、d個の特徴マップの各画素をチャネル方向に結合したもの(H∗W個のd次元特徴)が入ります。出力も同じ形(H∗W個のd次元特徴)です。
decoderへの入力は、encoderの出力に加え、N個のd次元のobject query(=learnt positional encoding)が入ります。このobject queryはネットワーク重みと同様の学習パラメータであり、学習して決まるパラメータです。このように機械翻訳タスクと違って、decoder入力(=N個のobject query)を事前に用意できるため、N個の推論すべてを同時に走らせることが可能です。(parallel decoding)
またpositional encoding(=object queryとspatial positional encoding)を1層目だけでなく各層で使用するようにしており、さらに上図のようにobject query(学習値)とspatial positional encoding(固定値)の両方を場所毎に使い分けることで精度を上げています。
学習済みのモデルを使用して、日常の風景画像から、人や車、鞄などの物体検出を気軽に試すことができます。

ラベル名とラベルがどの程度正しいかを示す確信度(1に近いほど確信が高い)が表示されています。
参考サイト:AI(DETR:Detection Transformerモデル)による物体検知
論文:https://arxiv.org/pdf/2005.12872.pdf
他にもPeleeやM2Detといった物体検出モデルもあります。興味を持たれた方はぜひ調べてみてください。
Pelee論文:https://arxiv.org/pdf/1804.06882.pdf
M2Det 論文:https://arxiv.org/pdf/1811.04533.pdf
弊社での物体検出の利用例
弊社ではこの物体検出技術を応用して下記のような用途で用いています。
・部品の誤欠品の検査
・異常の検知
従来、人が目視で行ってきた部品の取付間違いや取付忘れ,異常品の検出を物体検出AIによって、自動かつ高速・高精度で行うことができます。
この記事を読んで興味を持っていただいて、弊社での開発取り組みを気になった方は是非以下のSNSもご覧頂けると幸いです。
[関連記事]
量子コンピュータはシンギュラリティの実現に近づけるか。量子理論によってコンピュータの計算能力は大きく進歩しました。それによってシンギュラリティ―技術的特異点―は確実に実現に近づきました。ではいつ実現するのか?2045年問題とは?以下の記事でイチから解説します!是非ご覧ください!
>> シンギュラリティとは?意味やいつ起こるのか解説
Twitter https://twitter.com/crystal_hal3
Facebook https://www.facebook.com/クリスタルメソッド株式会社-100971778872865/
Study about AI
AIについて学ぶ
-

営業ロープレをAI化するメリットとは?課題をまとめて解決します
「営業ロープレをもっと効率的にできないか」という声は、営業責任者や研修担当者から絶えず聞かれます。ロープレは営業スキル向上に効果的な手法である一方、「相手の確保...
-

AIロープレとは?営業・接客・面接練習での活用法
人手不足が深刻化し、新人教育の「早期戦力化(イネーブルメント)」が企業の最重要課題となる中、教育現場に破壊的なイノベーションが起きています。 従来のコミュニケー...
-

AIロープレツールの選び方|比較ポイントと主要ツール比較を解説
「AIロープレを導入したいが、どのツールを選べばいいかわからない」という声をよく聞きます。AIロープレツールは種類が増えており、対応している業種・機能・価格もさ...