blog
AIブログ
【入門】機械学習とは?種類やアルゴリズムをわかりやすく解説!

機械学習という言葉をご存知でしょうか?
機械学習とは、AI(人工知能)の一種で、コンピューターが大量のデータを分析して傾向等を学習する技術のことを指します。
近年はAI(人工知能)の研究が盛んで、私たちのスマートフォンや家電にも使われているくらいなじみ深いものになっています。
人工知能(AI)についてはこちらの記事をご覧ください。
>> 人工知能(AI)とは?仕組みや技術、できることをわかりやすく解説
そのAIの進化・発展において機械学習は大きな影響を与えましたが、その仕組みやディープラーニング(深層学習)との違いについて詳しく理解していない方がたくさんいらっしゃいます。下記のページではその内容が解説されていますので、ぜひご確認ください。
>> 機械学習と深層学習の違いを解説します!
この記事では、AIを専門に研究開発している会社の視点から
・機械学習の概要
・機械学習のアルゴリズム
・機械学習の分類
・機械学習でできること
について、わかりやすく簡単に下の目次の順で解説していきます。
機械学習とは
機械学習とは、コンピューターがデータを分析する方法の1つで「ML(Machine Learning)」とも呼ばれています。
大量のデータを学習する際に、一定のルールやパターンを見つけ出し、次回同じような課題に直面した際に以前学習したルールやパターンを用いることでより良い予測や判断をすることができます。
人間も過去の経験や傾向から次を予測することができますが、コンピューターが処理する情報量は人間の比ではありません。そして一度記憶したルールやパターンは忘れることがありませんので、過去何十年分のデータ分析や予測は私たちの生活を助けてくれています。
そんな機械学習の仕組みや種類について次項で詳しく解説していきます。
機械学習の種類

いよいよ、機械学習の手法について解説していきます。
機械学習の手法を大きく分けると「教師あり学習」と「教師なし学習」、「強化学習」の3種類があります。これらは目的や扱うデータ、効率良く学習させるためにも適切に使い分ける必要があります。
以下、代表的な3つの手法について解説します。
①教師あり学習
3つある学習手法の中で最も代表的なものが「教師あり学習」になります。
教師あり学習は、人間が事前に正解のデータ(ラベル)を入力し、その正解のデータと比較して正しいかどうかを判断させます。その特性上、コンピューターにとって判断基準が明確であるため、「正しいか、間違っているか」の問題を解決するのに適しています。
教師あり学習のアルゴリズムとしては、「回帰」と「分類」が代表的なものになります。
※参照:第3章 教師あり学習
②教師なし学習
教師あり学習と対をなすのが「教師なし学習」です。
明確な答えがあった教師あり学習に対して、教師なし学習には答えがありませんので「教師なし」といわれています。そのため、AI自身で答えを見つける必要がありますが、AIが答えを見つけるという高度な処理はできません。そこでAIは与えられたデータに対して規則性や法則性を見つけようとします。
明確な答えがないデータ群に対し、規則性や法則性を探すときに教師なし学習を使います。規則や法則によってカテゴライズする際のアルゴリズムの代表的なものとして「次元削減」と「クラスタリング」があります。
※参照:第 4 章 教師なし学習
③強化学習
強化学習はコンピューター自身が試行錯誤を繰り返し、最適なシステムを見つけ実現する手法です。
教師あり学習、教師なし学習は基本的に人間がデータの入力や一定の指示を出していました。
それに対し、強化学習は人間が報酬(目標)を指定すると、コンピューター自身が最大限の報酬を得られるよう自律して判断・試行錯誤を繰り返します。
強化学習の流れ
STEP1.コンピューターが動作する環境を用意します。
STEP2.報酬(目標)を設定します。
STEP3.どのアルゴリズムで検証をおこなうかを設定します。
STEP4.コンピューターが検証を開始します。
かなり大まかな流れになりますが、教師あり学習、教師なし学習と比べると人間が介入する工程が少ないことがわかります。
この検証によって明らかになった結果や、試行錯誤した経験はコンピューターの中で蓄積されていきますので、次回似たような課題に直面した場合は前回の経験を活かした検証をおこないます。
これらを繰り返していくことで検証の速さや精度が向上していき、様々な場面で活躍することができます。
この強化学習自体は元々あった手法ですが、後述するディープラーニングと併用することで性能も精度も飛躍的に上昇したため、再度注目を集めている手法です。
※参照:What is reinforcement learning? The complete guide
強化学習についてはこちらの記事をご参照ください。
機械学習のアルゴリズム

ここでは、代表的な機械学習のアルゴリズムについて、紹介していきます。
機械学習には教師あり学習、教師なし学習、強化学習と3つの手法があり、それぞれで用いるアルゴリズムが存在します。
その中でも、現在主流になっているのは
- ニューラルネットワーク
- ディープラーニング
この2つです。
その他にも、代表的なアルゴリズムとして以下があげられ、モデルが軽量で解釈しやすいことから、ケースによって使い分けられています。
- k近傍法
- 決定木
- ランダムフォレスト
- XGBoost
- サポートベクトルマシン
ニューラルネットワーク
ニューラルネットワークとは、人間の脳神経系であるニューロンを参考にモデル化したアルゴリズムです。このモデルには、教師あり学習と教師なしの学習の2つがあります。
人間の脳はニューロンを相互接続して電気信号を交換したり、複雑な思考を可能にしています。この時、何でもかんでも情報を流すわけではなく、ある閾値以上の電気信号を次のニューロンに渡しています。
こうした情報処理の方法をコンピューターで応用できないかと考え、ニューロンの構造を手本にしたパーセプトロンという単純なモデルを重ね合わせて以下のようなニューラルネットワークとしました。
このように、入力層、隠れ層、出力層の3種類から構成されるモデルをニューラルネットワークといいます。
もちろん人間の脳のように複雑なものは作れないため、一方にしか信号を送れないなどの制限はありますが、それでもニューラルネットワークの登場により技術は各段に向上していったのです。
ディープラーニング

ディープラーニングとは、前述したニューラルネットワークの隠れ層を多層に重ねることで学習能力をさらに高めた機械学習の手法です。
中間層を数十〜数百層重ねたり、結合方法を工夫することで、より処理性能や複雑な問題に対処できるようになりました。
ディープニューラルネットワークは、ジェフリー・ヒントン教授とカナダのトロント大学が考案しました。2012年の「ILSVRC(Imagenet Large Scale Visual Recognition Challenge)」という画像認識の精度を競うコンペでは、それまで26-28%台の誤差率で競われていたのをディープラーニングを用いることで15.3%という驚異的な精度を出したことで瞬く間に世界中に広まりました。
4層以上にしても精度が上がらず煮詰まり違う方法を試す科学者が多い中、この朗報はAIの技術の革命ともいえるものでした。
ディープラーニングは、あくまで機械学習の中の1つに過ぎませんが、今やAIの技術向上のためには不可欠なものになっています。
ディープラーニングについては以下の記事もご参照下さい。
ディープラーニングと機械学習の違いについてもわかりやすく説明しています。
k近傍法
k近傍法は、ほぼあらゆる機械学習アルゴリズムの中でも最も単純と言われているシンプルなアルゴリズムです。
考え方としては、ある点をクラス分類する時にその周りの点のクラスの多数決で判断しようというものです。この時、一番近くのk個が所属するクラスで多数決を取ります。
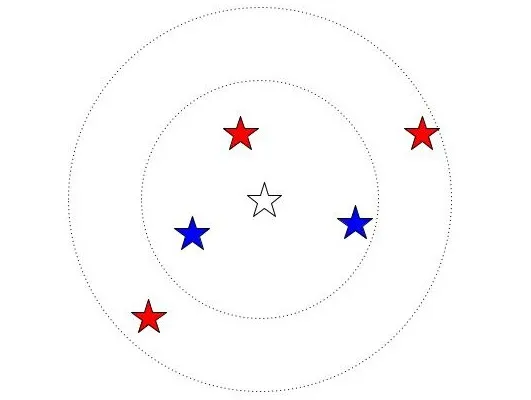
上の例の場合、真ん中の星が所属するグループは、k=3の場合は青、k=5の場合は赤といった具合です。
この動画は、k近傍法が具体的にどのように動いているのかをアニメーションにしたものです。学習を繰り返すにつれてデータが4つに分類されていく様子がわかると思います。
決定木
決定木は、木構造を用いた予測モデルです。木構造とは、木が幹から枝、葉と順々に枝分かれしていくような構造です。
木構造を使って、特徴量ごとに次の枝へ振り分けていくことで上手く分類できるモデルを作成します。フローチャートを想像していただけると分かりやすいかと思います。
例えば、動物を鷹、ペンギン、イルカ、熊に分けようと思ったら、以下のような決定木で上手く分けることができます。
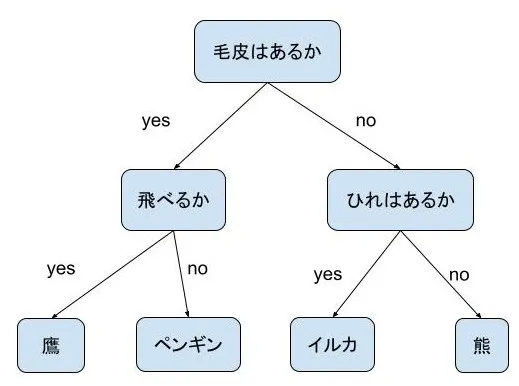
このように決定木は、解釈しやすいのが特徴ですが、過学習(訓練データに過剰適合してしまい、応用が効かない状態)に陥りやすいなどの欠点もあります。
ランダムフォレスト
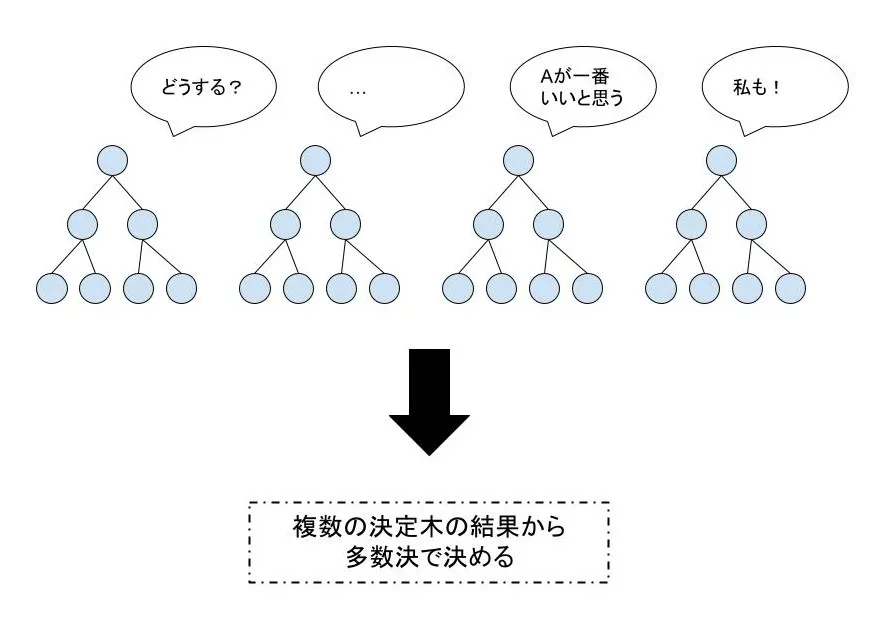
ランダムフォレストは、先程紹介した決定木をランダムに複数作成し、その多数決や平均を取ることで精度を向上させたモデルであるアルゴリズムです。
決定木を複数作成する方法としては、学習データから何度も復元抽出することで、少しずつ異なる決定木を作る方法で、バギングと呼ばれています。
昔から「三人寄れば文殊の知恵」というように、一つ一つは精度の低い決定木でも、多数決をとることで精度の高いモデルを作ろうという試みです。
ただし、多数決を取ることで、決定木の過剰適合しやすいという問題点を解決することができますが、解釈性は失われてしまいます。
XGBoost
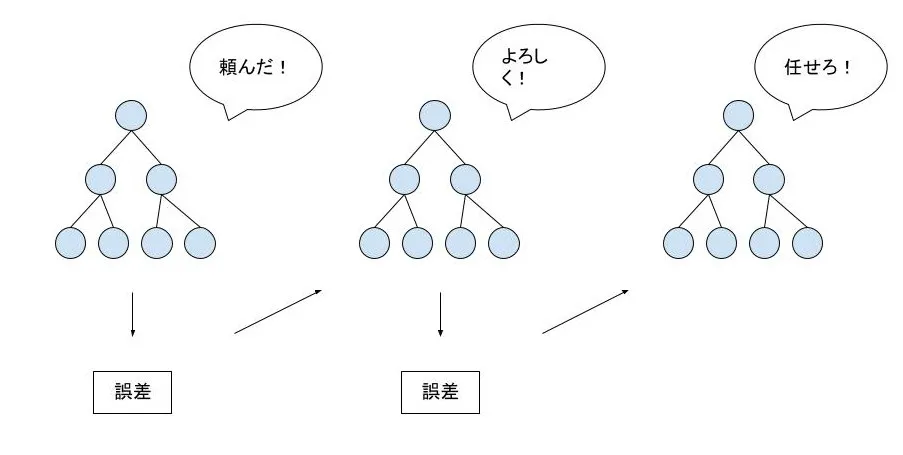
XGBoostもランダムフォレストと同様に、決定木を用いたモデルです。ただし、XGBoostでは、前の決定木の誤差を次の決定木に引き継いで新しい決定木を作ることを繰り返すことで段々と精度の高い決定木を作っていきます。
このようなサンプリング方法をブースティングといいます。このモデルは、特徴量エンジニアリングをしなくても精度の高い結果をだすことから、機械学習のコンペとして有名なKaggleで多用されています。
サポートベクトルマシン
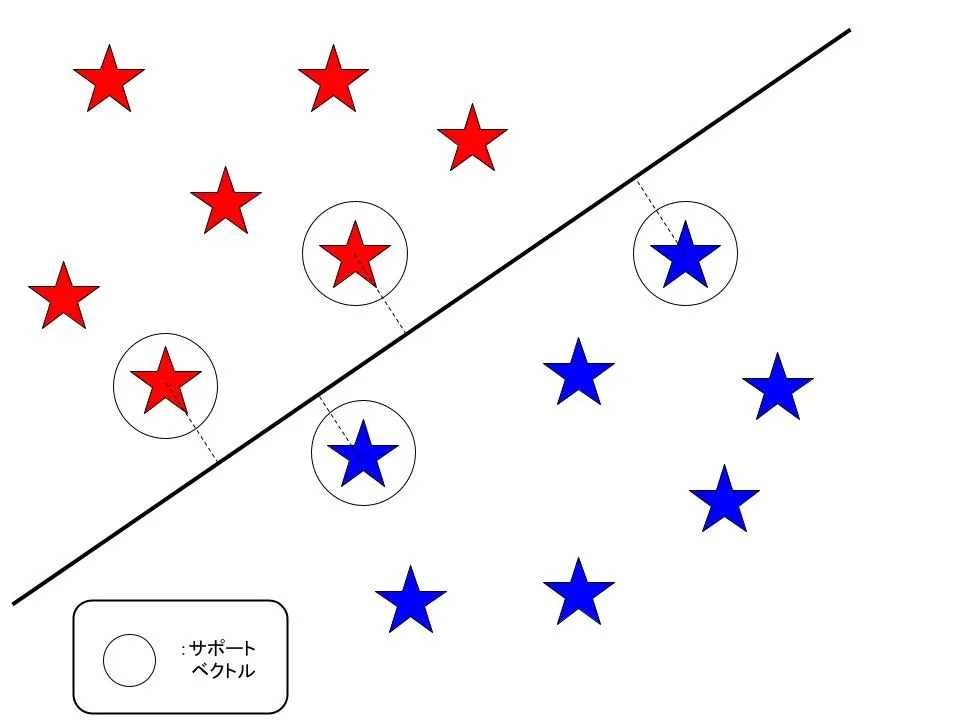
サポートベクトルマシンは、クラス分類において、クラスを最も上手く分割する超平面を引くことで識別します。
ここでいう超平面とは、高次元における平面のようなものをいいます。下の図のように、赤と青の二種類の星を上手く分けたいと考えた時に、サポートベクトルと呼ばれる点からの距離(マージン)を最も大きくできる超平面を引くことを考えます。
なお、直線で分割(線形分離)できない場合ももちろんあるため、ある程度の許容を許したり、非線形に応用できるカーネルトリックと呼ばれる手法が用いられています。
この動画は、サポートベクトルマシンの原理をアニメーションにして解説したものです。データの間に線が引かれ、データが分類されていく様子がわかると思います。
このモデルは識別精度が高く、ディープラーニング登場前までは特に多用されていました。
ここで機械学習のアルゴリズムをまとめると以下のようになります。
▼機械学習のアルゴリズム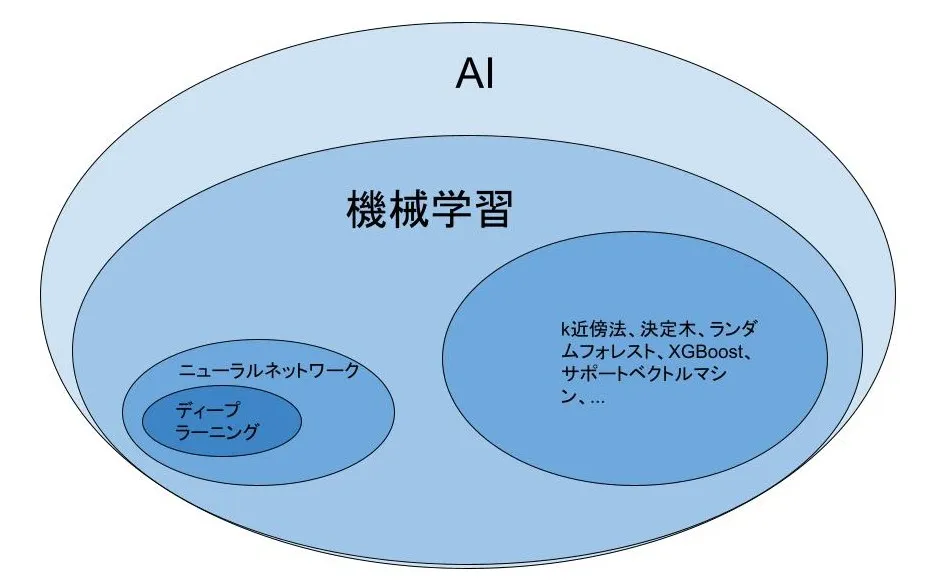
ディープラーニングは、機械学習・それもニューラルネットワークの一部に過ぎませんが、近年の台頭で「AI・機械学習=ニューラルネットワーク」というふうに扱われているのも事実です。
機械学習で一括りにされがちですが、手法や種類によって様々な専門用語が出てきますので、最初は混乱してしまうかもしれません。
しかし、このアルゴリズムの違いを知っておくことで、より機械学習についての理解が深まりますのでしっかり確認しておきましょう。
機械学習でできること
ここでは機械学習でできることを7つご紹介します。
回帰分析
回帰の主な目的は「値の予測」です。教師あり学習により正解のパターンを与え、そのパターンに基づき過去の大量のデータから予測して今後の値を算出します。回帰分析の例としては、「過去の最寄り駅の乗降者人数と駅近辺のチェーン店各店舗の売り上げを調査し、新しく駅近くに店舗を開く際の売上を予測する」などがあります。
このように現在データが得られていない場合でも予測が行えるのが回帰分析の特徴です。
分類
分類は、入力したデータをあるルールによって分類することをさします。
従来はコンピューターのスペックや技術面の問題もあり、1つのルールしか覚えさせることができませんでしたが、教師あり学習で複雑な正解を覚えさせることで多くのデータを監視することが可能になり、精度も向上していきました。
次元削減
教師なし学習のアルゴリズムで最も使われているのが次元削減です。次元削減とは、余計な要素を排除し、シンプルにすることでグループ化しやすくすることです。本来、データは多次元に展開しており複雑なため可視化できるものではないので、次元を削減することで簡略化しデータとして扱うことができます。
例えば、体重と身長から計算されるBMI(体重(m)÷身長(kg)^2)もなるべく情報量を落とさずに次元削減していると言えます。
クラスタリング

クラスタリングとは、AIが与えられたデータの特徴や類似性を探し、同じようなカテゴリーのグループに分けることを指します。
AIが傾向や規則性から判断するので、中には誤ったものが混じっている可能性もあります。AIが独自で判断してグループに分けるので、どういった基準でクラスタリングしたのかを考察する必要がありますので注意が必要です。
例えば、大量の名簿から共通項を持つグループを抜き出したり、ある程度AIの裁量に任せてカテゴライズしたい時にクラスタリングを使用することができます。
また、クラスタリングは、データをグループ分けする際に「階層的クラスタリング」と「非階層的クラスタリング」という方法に分けられます。
◆階層的クラスタリング
データを比較した際に類似度が近いものからまとめていく分け方です。
◆非階層的クラスタリング
階層を作らずにグループ化することです。
クラスタリングについてより詳しく知りたい方は、以下の記事をご覧ください。
レコメンデーション
レコメンデーションとは、そのまま「推薦」という意味です。データ中から特定の行動をとるとその顧客のニーズに合った商品や情報をおすすめすることができます。現在では様々な場面で使われていて、ECサイトがその代表的な例です。このレコメンデーションには様々な種類があり場面によって使い分けられています。
異常検知
異常検知とは、データ分析で外れた値を検知・推測することができる手法です。
予め存在するデータと一致していない予測結果や実際の観測結果を異状があるかどうか確認します。
弊社では、この異常検知について取り組んでいます。その実例について知りたい方は下記をご覧ください。
音の異常検知システム|クリスタルメソッド
2D画像での異常検知システム|クリスタルメソッド
自然言語処理
自然言語処理とは、人間の扱う自然な言語を分析し、コンピュータ上で人間と同じように言語を処理できるようにすることです。日常会話で使用される自然言語は曖昧さや感情などによる解釈の差が出るので解析するのは難しいとされています。自然言語処理は、これからより正確にできるようになるとされています。
自然言語について詳しく知りたい方は以下の記事をご覧ください。
自然言語処理とは|クリスタルメソッド
機械学習の活用事例
機械学習は様々な分野で活用されているため、私たちの身近なところに機械学習が使われていたりと新たな発見に繋がるかもしれません。
実用例①売り上げ予測
コンビニや販売店など、多くの業者は売り上げ予測をし予算や目標を掲げています。
その際に活躍するのが機械学習です。
強化あり学習で登場した回帰は値を予測するのに適しています。
過去数十年の統計を比較し計算することでおおよその売り上げを予測し、それを参考にして仕入れや販売促進活動をおこなっていきます。
これまでは店長や販売責任者の経験や勘に頼ることが多かったのですが、具体的な数字で視覚化されたことにより売り上げを伸ばすことが期待できます。
さらにAIを活用した商品の管理やマーケティング活動など、機械学習は多くの小売店や飲食店に導入されています。
実用例②点検の自動化
教師あり学習で正しい商品や成形を学習させることで、歪みやひび割れ・異物混入したものを検知するといった検品・点検に使わています。
これまでは人の目で1つ1つ確認していましたが、個人差や経験に左右され時間もかかっていました。
強化学習で一律の基準でブレがなく、一度に大量に検品できるようになったため工場や生産業界は各段に効率が良くなりました。
※弊社の取り組みは以下の記事でも解説しています。
近年はドローンを用いて、ビルの外壁や橋の裏側など人間の目視が難しいところでも点検が可能になり、活躍の幅を広げています。
実用例③おすすめ機能
インターネットで調べ物をしたり、通販サイトで買い物をしていると関連商品がおすすめとして表示された経験は誰しもあるかと思います。
これらはユーザーの検索履歴や入力された情報をもとに、AIが似たような特徴を持つデータを収集して表示させています。
これも教師あり学習・教師なし学習を応用させたものであり、これによって消費者の購買意欲を刺激して売り上げの向上に貢献しています。
特にGoogleは世界中のユーザーのデータを解析し、検索履歴から次のキーワードを予測して表示させたり、多少の誤字があってもAIが補完して検索結果を表示させたりと、ユーザーの皆様はその優秀さを身を持って体感されているかと思います。
実用例④自動運転
近年で注目を集めているのは車の自動運転でしょう。
これまではSF映画の中の夢物語でしたが、機械学習の技術を駆使し着実に実現しつつあります。
カメラで捉えた映像をディープラーニングで判断し、異物を検知した際にはブレーキをかけたり、適切な車間距離を判断して減速したりと、ドライバーをサポートする機能が続々と導入されています。
すでに1990年代にGPS機能を利用したカーナビは登場していましたが、ここに強化学習を搭載して、目的地を入力すれば自動で最短距離のルートを計算したり、混雑状況を考慮したルート案内に変更したりと、機械学習は活躍しています。
ここからさらに機械学習が進化すれば、車のAIが自律して全てを判断して走らせる夢の自動運転が実現する日も近いでしょう。
実用例⑤医療現場
日本の課題となっている少子高齢化社会や医療費の問題。
これらをAIで解決しようと日本政府も力を入れており、多額の予算をつぎ込み研究が進められています。
教師あり学習の異物検知で患者の病気を事前に発見したり、過去のカルテから患者の病気を判断する材料になったりと、機械学習は非常に役に立っています。
新薬の開発や業務の効率化など、様々な診療所や病院で採用されています。
さらに、コロナウイルスの影響もあり人との接触を控えるように言われている中で、AIは非常に有効であると考えれています。
介護ロボットなどのAIは機械学習の技術の結晶です。
カメラでの画像認識や異物検知、スピーカーからの音声認識や異音検知など、様々な技術が搭載されています。
今は、AI自身が自律し思考して会話をする技術なども開発されていますが、これもディープラーニングで何千何万通りの会話パターンを学習して得られた結果をもとにしており、ディープラーニングなくしては実現できなかったものです。
詳しくは以下の記事でも解説しています。
当面の課題である医療従事者の人手不足や負担軽減に機械学習は効果があると考えられており、今後も研究開発が進められていきます。
【入門】機械学習の例

機械学習は人間が1から組み立てるプログラミングとは違い、一度学習さえしてしまえば次回からは自動で対応してくれますので人間の手間やコスト面でも非常に優秀で重宝されています。
そんな機械学習の例について初心者でも分かるように入門編として簡単に解説していきます。
動物の画像から犬を分類する機械学習の流れの例(教師あり学習)
STEP1.画像とその正解のセットのデータを大量に用意します
STEP2.モデルを作成し、STEP1.で用意した大量のデータを使って分類精度が高くなるようなパターンを学習させます
STEP3.学習で使わなかった未知のデータに対してもうまく判別できるかどうかをテストします。
中には犬と狼など、紛らわしいものを誤って抽出することもありますが、機械に犬と狼との違いを学習させ、次回は正確に判断できるように修正していきます。
このような流れで大量に学習させ、ルールやパターンを蓄えていくことで様々な場面でも対応できたり応用することが可能になります。
応用の例:犬の画像の中からチワワだけを選ぶ。
機械学習の優秀なところは、画像だけではなく数字やデータ予測にも応用が効くということです。過去数十年の数字から特定の数字を抽出することで今後の売り上げ予測に使われたり、過去の気圧や雲の動きを抽出した天気予報にも使われています。
機械学習の今後はどうなるのか
ここまで機械学習の種類やアルゴリズム、実用例などについて解説してきました。
機械学習やディープラーニングの登場により、IT業界は一変し飛躍的な進化を遂げていきました。
スマホや電化製品、カーナビなど身近なものに当たり前のように搭載されるようになり、私たちの生活はより豊かになっていくでしょう。
一方で、ディープラーニングを繰り返していった結果、AIが人間の脳を超えるという意見も上がっています。
AIが全て計算・対応できるようになってしまえば、プログラマーやエンジニアといった職種だけでなく、事務作業や受付も全てAIで事足りてしまいます。
機械学習は便利で非常に優秀ですが、これが理由でAIに仕事を奪われてしまう未来もありうるということを忘れないように、今後のAIや機械学習の動向に注目していただけばと思います。
この記事を読んで、機械学習やAIに興味を持っていただければ幸いです。
ここまでご愛読いただきありがとうございました!
機械学習を実践したい方はぜひこちらを活用して実際に操作して機械学習に触れてみて下さい!
[関連記事]
>Pythonによる機械学習
よろしければ弊社SNSもご覧ください!
Twitter https://twitter.com/crystal_hal3
Facebook https://www.facebook.com/クリスタルメソッド株式会社-100971778872865
Study about AI
AIについて学ぶ
-

営業ロープレをAI化するメリットとは?課題をまとめて解決します
「営業ロープレをもっと効率的にできないか」という声は、営業責任者や研修担当者から絶えず聞かれます。ロープレは営業スキル向上に効果的な手法である一方、「相手の確保...
-

AIロープレとは?営業・接客・面接練習での活用法を解説します!
人手不足が深刻化し、新人教育の「早期戦力化(イネーブルメント)」が企業の最重要課題となる中、教育現場に破壊的なイノベーションが起きています。 従来のコミュニケー...
-

AIロープレツールの選び方|比較ポイントと主要ツール比較を解説
「AIロープレを導入したいが、どのツールを選べばいいかわからない」という声をよく聞きます。AIロープレツールは種類が増えており、対応している業種・機能・価格もさ...