blog
AIブログ
テキストマイニングとは?実例をわかりやすく解説
テキストマイニングについてご存じでしょうか?
自然言語処理を応用したものとしてテキストマイニングがあります。
ここでは、そんなテキストマイニングの活用事例についていくつか解説します。実際にどのような使われ方をされているのかについて理解していただければ幸いです。
自然言語処理について詳しく知りたい方はこちらをご参照ください。
自然言語処理とは?解説!
テキストマイニングについて詳しく知りたい方はこちらをご参照ください。
テキストマイニングとは?やり方やツールまで解説
テキストマイニングの活用事例
テキストマイニングにより、どのような事が分析可能になるのでしょうか?
イメージしやすいようにわかりやすい事例を紹介していきます。
◆顧客データ分析
テキストマイニングによる自然言語解析の恩恵を特に受けたのが顧客データ分析です。
顧客のリアルな意見や要望が記載されているアンケート調査や問い合わせのテキストデータから、有益な情報を抽出していきます。
また、テキストマイニングは顧客の性別・年代別の振り分けや傾向なども一度に分析できる機能を持つツールのため、問題の改善や次回のサービス・製品の品質向上に活用することができます。

◆情報抽出や情報予測
近年はSNSの普及により、誰でも情報の閲覧や発信が可能になりました。
そういった大量のテキストデータの中から頻出する言葉や傾向を分析することで最近の流行がわかります。自社のキーワードを設定することで、不満や要望・ブランドの浸透具合などを抽出し、今後のマーケティングに活用することができます。
以下では、弊社でのテキストマイニングの研究事例を紹介します!
◆チャットボット
AIの発展に伴い、新たな顧客対応の手段として注目されているのがチャットボットです。
人件費削減や24時間対応できるなど、メリットの多いチャットボットですが、複雑な会話や文章が理解できないことが課題でした。

しかし、技術の向上により柔軟に対応が可能になったほか、対話記録からテキストマイニングを行うことで、重要な言葉が含まれる会話のみを抽出したり、対応できなかった問題は次回のアップデートの課題としてデータを蓄積し、訓練することができます。
◆アンケート結果の調査報告書作成の効率化

株式会社MS&Consultingでは、飲食店や小売店といったサービス業の企業に対し、コンサルティングサービスを提供しています。
こちらの企業では、顧客満足度や従業員満足度を可視化するためにアンケート調査を行っています。1人の回答者から約2000文字程度の回答が得られますが、それが年間に20万件以上も蓄積されるため、これまで各コンサルタントが読み解くのに膨大な時間がかかっていました。
そこで、専用のツールを導入してテキストマイニングを行ったところ、短時間でアンケート結果の分析が可能となりました。そして、分析結果からこれまで可視化されなかった課題を発見することができました。
例えば、元気の良い挨拶を売りにしていたお店で、「挨拶」でフィルタリングして解析をおこなったところ、「店員の挨拶の声が大きくて邪魔になる」という回答が見つかりました。このように、店頭での元気の良い挨拶は大切ですが、利用客によってはそれをネガティブに感じる方もいます。
アンケート結果の分析にかかる時間が大幅に短縮された結果、レポーティングなどの建設的な作業に時間を割くことができるようになりました。その結果、提供するソリューションやレポートの価値が格段に向上し、利用する企業からの満足度向上につながっています。また、各コンサルタントの恣意的な分析が排除され、客観的なデータが得られるようになり、より説得力のあるレポートを作成できるようになりました。
詳しくは以下のURLをご参照ください。
テキストマイニングユーザー事例|Text Mining Studio
◆コールセンターにおけるオペレーターの品質評価精度の向上

ビーウィズ株式会社では、コールセンターやバックオフィス業務の外部委託を引き受けています。これまで、人を活用したオペレーションをメインにやってきましたが、近年では一部オペレーションをAIによって自動化しています。AIによってコールセンターのオペレーターとお客様の通話記録がリアルタイムにテキスト化され、データとして蓄積されています。
コールセンターは、その応対の良し悪しがお客様企業の印象に直結するため、応対品質の維持・向上が欠かせません。こちらの企業では、これまで全国約4800ブースの電話応対の内容をスタッフが実際に聞いて評価を行っていましたが、1件の評価に30分から1時間程度かかるため、何万件もの膨大な音声データのほんの一部しかチェックできない状況でした。
しかし、テキストマイニングによりオペレーターの全ての会話を評価できるようになり、評価精度が格段に向上しました。具体的には、お客様に対してきちんと敬語を使っているか、あるいは使いすぎていないか、同じ言葉を何回言っているかといったことまでチェックできるようになりました。
詳しくは以下のURLをご参照ください。
テキストマイニングユーザー事例|Text Mining Studio
◆投資家支援プラットフォーム
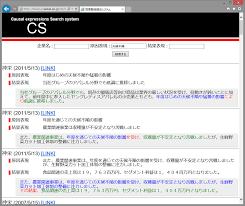
画像引用及び、内容はこちらの論文を参照しています。
>>金融テキストマイニングに基づいた投資家支援プラットフォームの開発
近年急速に発達テクノロジー、人工知能の発達は素晴らしいものです。この人工知能の発達を用いて、膨大な金融情報を解析することで、投資家の投資判断を助けようとする技術に注目が集まっています。テキストマイニングの技術を用いて、多くの人が、新聞記事や決済短信などの金融テキストを分析できるテキスト解析プラットフォームを利用できることを目指しています。
特許分野において、株式会社NTTデータ数理システムは、Text Mining Studio3を特許文書などを解析するテキストマイニングプラットフォームを開発しています。
金融分野、特許分野などの様々な分野で文書を解析するシステムが開発されています。
いずれのプラットフォームも、単語の表現の頻度、もしくは、係り関係を基準に分析をしています。
論文によりますと、新たに、原因・結果表現検索システム5を作成しており、それでは、論理関係の一つである因果関係に基づき,原因と結果を表す表現を決算短信 PDF から抽出し、それを検索できるシステムであるとされています。従来の単語や表現の頻度だけではなく、因果関係を利用することで、単語頻度だけでは得られない情報を得ることができるようになってきています。
投資家にとって必要な情報が簡単に検索できるようになることは、投資をしようとしている人にとってプラスとなるのは間違いありません。
現在は、決済短信と日経新聞記事を用いた因果チェイン検索システムの開発を試みられています。
さらに、過去の研究で用いられて手法をpythonのパッケージにして公開する計画を立てらていて、これにより、お手軽に金融テキストマイニングを試すことができるようになり、実務に応用しやすくなると期待されています。
より具体的なテキストマイニング事例
ここでは、より具体的で専門的なテキストマイニングの事例についてわかりやすく解説します。
適時開示情報の業績に対するリスク有無の自動判定
こちらは弊社で取り組んでいるテキストマイニングの活用事例になります。以下より論文を入手できます。
>>適時開示情報の業績に対するリスク有無の自動判定
弊社の代表が共同著者となっています。
コロナ鍋や、日本の少子高齢化のため、年金を受け取ることが出来ないのではないかといった将来に向けた心配から、近年個人投資家の数が増加してきています。投資をする上で、投資を検討しようとしている企業及び、既に投資をしている企業についての情報を知ることはとても重要になってきます。
重要な会社情報を上場企業が開示しないといけないということを、適時開示情報と呼びます。
適時開示情報の中には、上場企業の株価に影響を与える可能性の情報もあります。業績に関連する情報は、株価への影響を大きく与えます。
適時開示情報は、常に更新し続けるため、すべてを閲覧することはとても難しく、業績に関連する情報のみを選ぶのも難しくなっています。
テキストマイニングの手法を用いて、投資家に、リスクの有無を判定をすることで、投資において有利になることを目標とします。
◆提案手法

実際にどのように、リスクの有無を判定するのかを段階に分けて紹介していきます。
手法概要
① 適時開示情報の中から業績にリスクがあると考えられる情報を人手で抽出して、学習データを作成します。
その学習データを後述のワードリスト(表1)に示す語により分類します。
②学習データ・テストデータを適時開示情報の文書ごとに Doc2Vecと呼ばれるものによりベクトル化します。
③深層学習におけるモデルの最適な中間層や batch を決定します。
④Chainer を用いて学習データを用いて学習を行い,Chainer のモデルを作成します。
⑤作成されたモデルに基づき,リスクがある文書をリスクあり,リスクなしに分類し,さらに,リスクありと判定された文書を,その内容に基づいて分類します。
使用するデータ
学習データには 2017 年の適時開示情報を使用し,テストデータには 2016 年の適時開示情報を使用します。
①学習データの作成方法として、下記に含まれる単語を含む文章を「リスク有り」とし、含まれない単語を「リスク無し」とします。
表1 災害, 紛争, テロ, 地震, 風水害, 疫病, パンデミック, 国際紛争, 訴訟, 法改正, 知的財産侵害, 事件, 事故, 不正, 金融犯罪, コンダクトリスク,(以下略 全99個)
②「リスク有り」と分類したものを、「特別損失」、「違反」、「その他」の3種類に分類する。「その他」には「火災」、「訴訟」、「損害」といった情報を含みます。
分類は下記に示されている語とラベル名に基づいて分類をします。
| ラベル名 | 含まれている語(一部) |
| 特別損失 | 特別損失,減損損失 |
| 違反 | 違反,不正 |
| その他 | 災害,紛争,訴訟 |
| リスクなし | / |
深層学習に使用するモデル
深層学習について詳しく知りたい方はこちらをご覧ください。
深層学習について説明します!
①epoch を 30 として中間層 X のユニット数を変化させて,テストデータにおける精度を比較します。
②最適な中間層 X におけるユニット数を中間層に使用します。
③batch の値を変化させて,テストデータにおける精度を比較します。
④最適な batch の値を使用します。
◆評価
| ラベル | 精度 |
| 特別損失 | 95.2% |
| 違反 | 88.2% |
| その他 | 74.7% |
| リスクなし | 89.4% |
| 全体 | 87.4% |
最も低い精度であったラベルは「その他」で 74.7%,最も高い精度であったラベルは「特別損失」で 95.2%でありました。これは,「特別損失」の文書の特徴は掴めているが,「その他」は特徴が掴みづらかったと言えます。
◆リスク有無判定-まとめ

リスクのあり、無しの判断間違えは、1番の問題です。リスクを無しを判断して、投資してしまった結果、大損をしてしまうということに繋がってしまったり、リスク有りと判断をして、投資することを見逃して、一攫千金のチャンスを逃してしまったりするかもしれません。
今回の深層学習を用いた手法では、「リスクのあり」、「リスクのなし」の判断の有無は89.4%ととても精度の高いものとなっています。
リスクありの単語が含まれていなくても、学習することで、類義語が含まれてると判断しリスクありと判断することもできています。
また、適時開示情報を「特別損失」「違反」「その他」「リスクなし」の4種類に分類をする精度は87.4%となっています。
実際には、リスク有りと判断されたものが、他の企業に及ぼすリスクについても考える必要があります。したがって、取引関係や資本関係のある会社との関連性についても考える必要があります。
業績要因・業績結果文の抽出
財務諸表(決算短信、有価証券報告書)から業績要因の抽出は行われてきましたが、企業ごとにフォーマットが異なるということが問題となってきました。特に、事業セグメントごとの業績情報は、表や文面のフォーマットが異なるため、業績情報の抽出は困難でした。
業績回復の要因が、企業の主力事業が好調であれば、株価への影響は大きいですが、株式売却の計上などの特別利益の計上が要因であるならば、株価への影響は小さいため、業務情報の中でも特に業績要因が投資判断において重要であるとされています。
したがって業績要因と業績結果の抽出を行うことは重要となります。
有価証券報告書から企業ごとの事業セグメント名とその事業セグメントに関する業績要因文・業績結果文を抽出する手法について例を取り扱います。
◆提案手法

①有価証券報告書の 1.5.節「従業員の状況」から、事業セグメント名の候補を抽出します。
②有価証券報告書の 2.章「事業の状況」から、文をすべて抽出し、業績要因文、業績結果文、それ以外の文に分類します。
③②で抽出した業績要因文に対して、事業セグメントを付与し、その業績要因文に対応する業績結果文があれば、その業績結果文にも事業セグメントを付与します。
④③で事業セグメントが付与できなかった業績要因文に対して、別のアプローチを用いて、事業セグメントを付与します。
業績要因文であるかどうかの分類
①決算短信から業績要因文、手がかり表現、後述の企業キーワードを抽出します。
企業キーワードとはその企業にとって重要なキーワードのことです。
②①で抽出された手がかり表現の“拡張手がかり表現”を獲得します。
③①で抽出された業績要因文に対して、企業キーワードを用いてスコアを付与します。
④拡張手がかり表現を含み、かつ,スコアが高い業績要因文を正例とし、手がかり表現,企業人工知能学会研究会資料にキーワードをともに含まない文を負例として学
習データを自動生成します。
⑤自動生成された学習データを使用し、深層学習にて有価証券報告書から抽出した事業セグメントに対応する文集合に対して、1文ごとに業績要因文を判定します。
業績結果文であるかどうかの分類
業績要因文との関係に基づき業績結果文を確定させます。
◆事業セグメントの付与
① 文の位置による付与
「。」を含まない文であれば,事業セグメント名の候補を含んでいるかどうか確認します。含んでいた場合そこから5行以内を事業セグメントの内容と判断します。
② ルールベースによる付与
brl ファイルからテキストを抽出する際に、事業セグメント名と事業セグメントに対応する文が一つになってしまい、事業セグメントの付与ができない原因に対して、行の先頭、1文字削除した箇所、2 文字削除した箇所、3 文字削除した箇所に対して、事業セグメント名の候補があるかどうかでセグメントの付与を行います。
③ 最近傍法による分類
ここまでに事業セグメントが付与できた業績要因文を用いて、まだ事業セグメントが付与できていない業績要因文とのコサイン類似度を計算し,コサイン類似度が一番高い業績要因文と同様の事業セグメントを付与します。
◆実装
本手法を実装し,キーワードによって業績要因文を検索できる有価証券報告書検索システムを作成されています。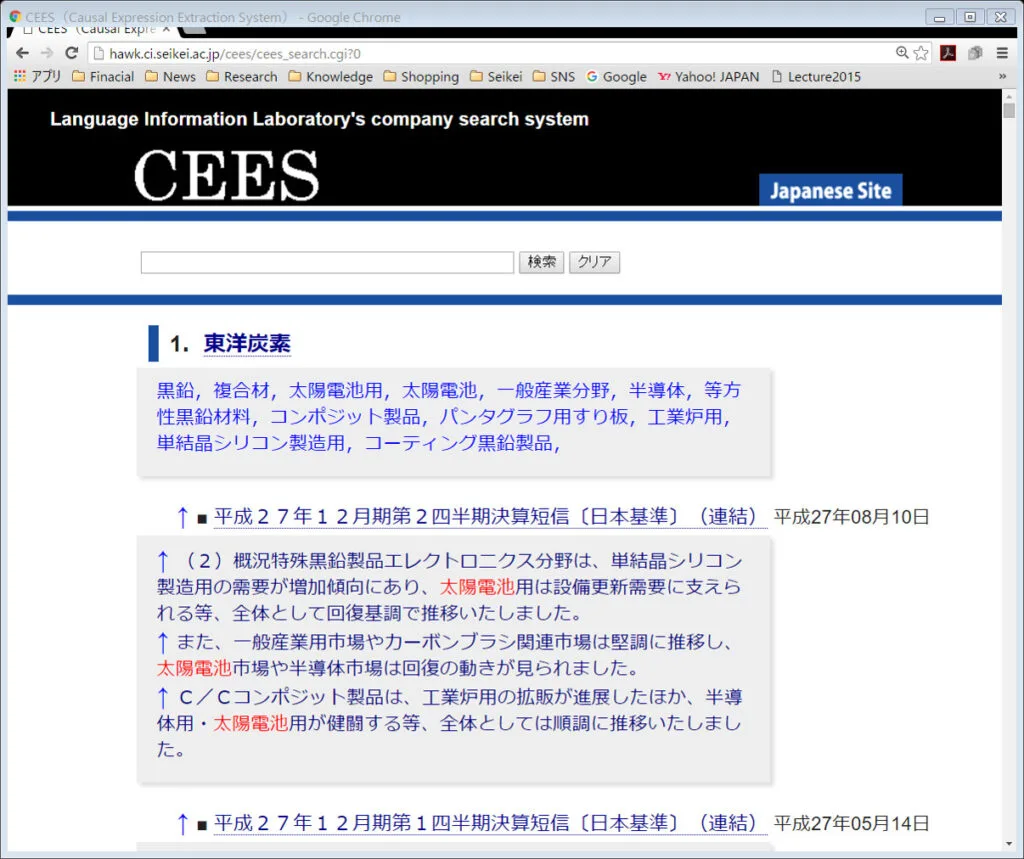
◆業績要因・業績結果文の抽出-まとめ
業績要因文の分類精度は0.91と高い数値出しました。フォーマットが異なる場合に対しても対応できるようになるのと、業績以外に含まれる情報についての「事業の内容」、
「企業の対処すべき課題」、「事業等のリスク」、「研究開発活動」と言ったものに対しても、分類ができるようになることが課題と考えられています。
分類が正確になれば、投資でたくさん儲けることが出来るようになるのは間違いないでしょう。
まとめ
いかがだったでしょうか。今回はテキストマイニングの活用事例をいくつか紹介いたしました。今後、様々な分野にテキストマイニングの技術が活かされていくことは間違いありません。
テキストマイニング技術が我々の生活を豊かにしていくことが楽しみですね!
またよろしければ弊社SNSもご覧ください!
Twitter https://twitter.com/crystal_hal3
Facebook https://www.facebook.com/クリスタルメソッド株式会社-100971778872865/
Study about AI
AIについて学ぶ
-

営業ロープレをAI化するメリットとは?課題をまとめて解決します
「営業ロープレをもっと効率的にできないか」という声は、営業責任者や研修担当者から絶えず聞かれます。ロープレは営業スキル向上に効果的な手法である一方、「相手の確保...
-

AIロープレとは?営業・接客・面接練習での活用法を解説します!
人手不足が深刻化し、新人教育の「早期戦力化(イネーブルメント)」が企業の最重要課題となる中、教育現場に破壊的なイノベーションが起きています。 従来のコミュニケー...
-

AIロープレツールの選び方|比較ポイントと主要ツール比較を解説
「AIロープレを導入したいが、どのツールを選べばいいかわからない」という声をよく聞きます。AIロープレツールは種類が増えており、対応している業種・機能・価格もさ...