blog
AIブログ
「Diffusion Transformers (DiTs)」とは?わかりやすく解説します!
「Diffusion Transformers (DiTs)」とは
Diffusion Transformers (DiTs) は、画像生成における新しいアプローチです。DiTsは、拡散モデルとトランスフォーマー技術を組み合わせたもので、従来のU-Netアーキテクチャに代わる設計です。
トランスフォーマー(Transformer)の詳細な説明は下記リンクよりご確認ください。
>> Transformerとは?AI自然言語学習の技術を解説
1. 背景と開発の動機
拡散モデル(Diffusion Models)は、近年の画像生成で注目されています。特にU-Netアーキテクチャを使用した拡散モデルは、GANsに代わって高い生成能力を示しています。
一方、トランスフォーマーは、自然言語処理や視覚タスクでの優れたスケーラビリティが特徴です。これを拡散モデルに応用することで、より高いパフォーマンスが期待できます。これが、DiTsの開発に至った背景です。
2. Diffusion Transformer (DiT)のアーキテクチャについて
トランスフォーマーブロック
DiTは、トランスフォーマーのSelf-Attentionメカニズムを用いて、画像の潜在表現を操作します。これにより、ViT(Vision Transformer)に近い形で画像パッチを処理します。
パッチ化
画像を小さなパッチに分割し、それをトークンとしてトランスフォーマーに入力します。これによりDiTは、画像全体を一度に処理するのではなく、局所的な情報を効率的に学習します。
拡散過程の条件付け
トランスフォーマーブロックにおいて、タイムステップやクラスラベルなどの追加情報を条件付けとして組み込むことができます。これによりDiTは、単なる画像生成だけでなく、条件付き生成も可能になります。
3. 主な特徴
スケーラビリティ
トランスフォーマーは、モデルのサイズやデータ量に応じて性能が向上するという特徴があります。これがDiTsでも活用され、モデルのパラメータ数や計算量が増えることで、生成品質が向上します。
計算効率
DiTsは従来の拡散モデルに比べ、計算効率が優れています。特に、潜在空間での拡散を行うため、Gflopsを抑えつつ高品質な生成が可能です。
4. 性能
DiTsは、ImageNetのような高解像度の画像生成タスクで、従来のU-Netベースの拡散モデル(例えばADMやLDM)を上回る性能を発揮しています。また、計算効率の面でも優れた結果を示しています。
5. 今後の展望
DiTsは、現行の拡散モデル研究において重要なブレークスルーです。さらに、スケーリングや改善が期待されます。また、DALL·E 2やStable Diffusionのようなテキストから画像を生成するモデルにおけるバックボーンとしての適用も考えられます。
Diffusion Transformers (DiTs) は、トランスフォーマーを基盤とした拡散モデルで、従来のU-Netベースのモデルに代わるものとして設計されています。高いスケーラビリティと計算効率を特徴とし、画像生成タスクにおいて優れた性能を発揮しています。
拡散モデルについて
Diffusion Transformers(DiTs)とは?
「Diffusion Transformers(DiTs)」は、画像生成に特化した新しいアーキテクチャです。DiTsは、既存のトランスフォーマー技術をベースに、画像生成タスクに最適化されています。トランスフォーマーは、もともとテキストや画像処理に非常に効果的な技術ですが、その特性を活かして、DiTsは画像生成における性能をさらに向上させています。
Vision Transformer(ViT)との関係
DiTsは「Vision Transformer(ViT)」という、画像処理に特化したトランスフォーマー技術に基づいています。ViTでは、画像を小さなパッチ(部分)に分割し、順番に処理します。DiTsもこの手法を採用し、画像を細かく分割して効率的に学習を行う仕組みです。このプロセス全体が、図3で示されています。図3では、DiTアーキテクチャ全体の仕組みが視覚的に解説されており、DiTsがどのように画像を処理するかを示しています。
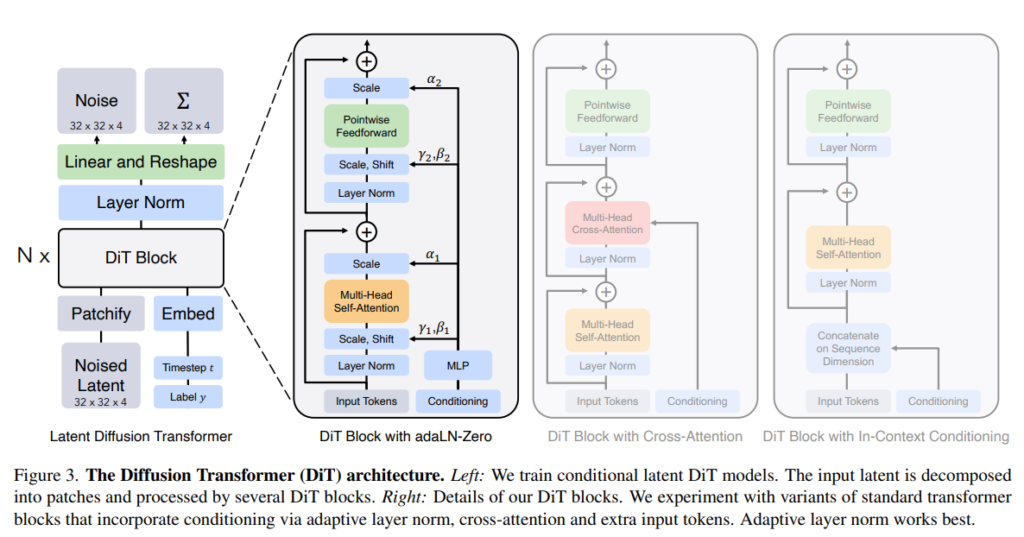
(出典:【論文】Scalable Diffusion Models with Transformers)
潜在拡散モデル(LDMs)について
潜在拡散モデルとは?
LDMs(潜在拡散モデル)は、画像生成の効率を向上させるためのアプローチです。高解像度の画像は通常、計算負荷が非常に高いため、LDMsでは以下の2つのステップを採用しています。
画像の圧縮
最初に、エンコーダを使って画像を圧縮し、潜在表現に変換します。これにより、元の大きな画像を扱わずに、効率的にデータを処理できます。
圧縮された情報の利用
圧縮された情報(潜在表現)を使い、画像生成のモデルを学習します。学習されたモデルは、潜在表現を元にデコーダを使って元の画像に戻します。この手法により、計算負荷が減りつつも、高品質な画像生成が可能になります。
DiTの入力仕様
図4. DiTの入力仕様について説明
DiT(Diffusion Transformers)は、拡散モデルとトランスフォーマーを組み合わせた画期的な画像生成モデルです。まず、画像は「パッチ化」され、小さなブロックに分割されます。このプロセスにより、DiTは画像データを効率よく処理します。例えば、パッチサイズを変更すると、計算量や生成される画像の詳細さが変わります。
トランスフォーマーブロックでは、画像に加えてタイムステップやクラスラベルといった追加情報を処理できます。これにより、条件付き生成が可能となり、生成品質が向上します。図4では、DiTsがどのようにデータを処理しているかを示しており、このパッチ化プロセスの重要性が視覚的に説明されています。
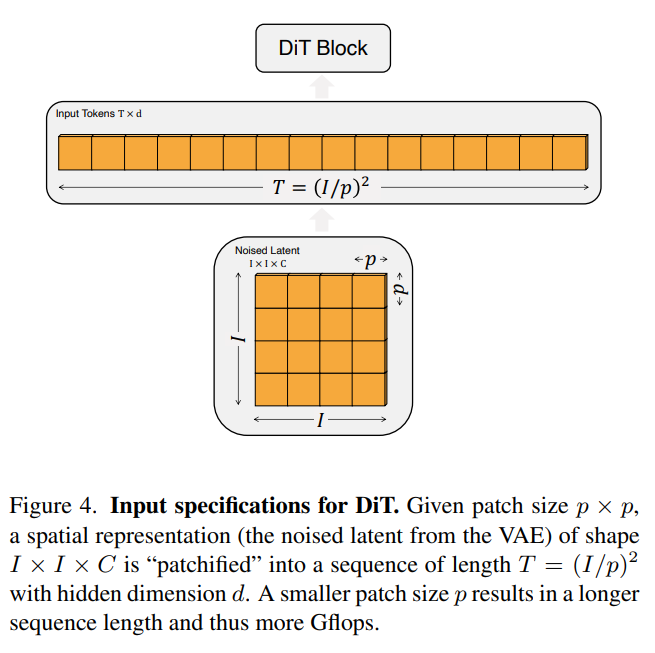
(出典:【論文】Scalable Diffusion Models with Transformers)
この図では、DiTs (Diffusion Transformers)がどのようにデータを処理するかを説明しています。
- パッチサイズとは?
- 画像を小さなブロック(パッチ)に分割する際のサイズです。例えば、パッチサイズが p×pp \times pp×p なら、画像を p×pp \times pp×p の小さなブロックに分割します。
- 空間表現の意味
- ここで「空間表現」とは、元の画像が変換されたデータのことです。具体的には、VAEという仕組みでノイズを加えられたデータです。このデータは、形が I×I×CI \times I \times CI×I×C となっており、これは画像の幅と高さが III、色チャンネルが CCC であることを意味します。
- パッチ化とは?
- 画像をパッチに分割することです。分割後、各パッチを順番に処理するために、長さ TTT のシーケンス(順番に並べたデータ)に変換します。この長さ TTT は、画像のサイズ III とパッチサイズ ppp によって決まります。具体的には、T=(I/p)2T = (I / p)^2T=(I/p)2 という式で計算されます。
- パッチサイズと計算量の関係
- パッチサイズ ppp が小さいほど、画像をより細かく分割することになります。その結果、処理しなければならないデータの量(シーケンスの長さ)が増えます。これは計算量(Gflops)が増加することを意味します。
簡単に言うと、画像を小さなブロックに分けて処理しますが、そのブロックが小さいほど処理する量が増えて、計算が複雑になります、ということです。
Patchifyについて、わかりやすく説明します。
1. Patchifyとは?
- Patchifyは、画像を小さな部分(パッチ)に分割して、それぞれの部分を処理する方法です。DiTs (Diffusion Transformers)では、最初にこの「パッチ化」というステップを使います。
2. 具体的な例
- 例えば、256 × 256ピクセルの画像がある場合、これを32 × 32の小さなブロック(パッチ)に分割します。分割後、このパッチをシーケンスとして処理します。このプロセスにより、モデルは画像の局所的な特徴を学習できます。
3. パッチ化のプロセス
- 各パッチを「トークン」と呼ばれるデータの単位に変換します。これらのトークンはDiTsで順番に処理され、全体として画像を再構築します。
4. パッチサイズが変わるとどうなる?
- パッチサイズ ppp を小さくすると、画像がより細かく分割されます。その結果、トークンの数 TTT が増え、DiTsが処理しなければならない計算量(Gflops)も増えます。例えば、パッチサイズを半分にすると、トークンの数は4倍になりますが、これにより計算量も大幅に増加します。
5. パラメータ数への影響
- パッチサイズを変えても、DiTsが学習するパラメータの数にはそれほど大きな影響はありません。計算量は増えますが、パラメータ数には大きな変化がないため、効率的な学習が可能です。
6. DiTの設計空間
- DiTsの設計では、パッチサイズを2、4、8などに設定してさまざまなバリエーションを試すことができます。これにより、モデルの柔軟な設計が可能になり、さまざまなタスクに適応できます。
簡単に言うと、Patchifyは画像を小さく分けて順番に処理する方法で、パッチサイズを小さくすると処理が増えるけど、学習する内容にはそれほど影響しないということです。
DiTブロック設計について、わかりやすく説明します。
1. パッチ化後の処理
- まず、画像が小さなパッチに分けられます(これを「パッチ化」と呼びます)。その後、これらのパッチは「トークン」というデータに変換されます。
2. トークンの処理
- 変換されたトークンは、次に「トランスフォーマーブロック」と呼ばれる処理ユニットを通過します。これは、トークンの内容を分析して、次のステップに必要な情報を取り出すためのものです。
3. 追加の条件情報
- 画像に加えて、DiTは他の情報も処理することができます。例えば、ノイズが加えられた画像のタイミング情報(タイムステップ ttt)、画像が属するクラス(クラスラベル ccc)、さらに自然言語などの追加の情報が含まれます。
4. 4つのトランスフォーマーブロックのバリエーション
- これらの追加情報をうまく処理するために、4つの異なるトランスフォーマーブロックの設計を試しています。それぞれの設計は、標準的なトランスフォーマーブロック(ViT)に少しだけ、でも重要な変更を加えたものです。
5. 図3に示される設計
- 図3では、これらのブロックの設計が具体的にどのように行われているかが示されています。
簡単に言うと、DiTブロック設計では、画像を処理するためのブロックに、追加の情報をうまく処理できるようにした4つのバリエーションがあり、それぞれが画像生成において重要な役割を果たしているということです。
インコンテキスト・コンディショニングについて、わかりやすく説明します。
1. 何をする手法?
- インコンテキスト・コンディショニングは、DiTs(Diffusion Transformers)において、画像に加えて「タイムステップ ttt」や「クラスラベル ccc」といった追加情報も一緒に処理します。
2. 具体的な方法
- まずDiTsは、タイムステップ ttt とクラスラベル ccc を、それぞれ「トークン」というデータの単位に変換します。次に、これらのトークンを、画像トークンの列の一部として追加します。
3. 特別な処理はしない
- DiTsでは、追加されたトークンは、特別扱いせず、他の画像トークンと同じように処理します。つまり、これらのトークンも画像の一部として扱われ、特別な設定や変更は不要です。
4. ViTの仕組みを活用
- この手法は、ViT(Vision Transformer)で使われる「clsトークン」と似ています。clsトークンは、ViTで画像全体の特徴をまとめるために使われるトークンです。インコンテキスト・コンディショニングでは、特別な修正を加えずに、標準的なViTの仕組みをそのまま使うことができます。
5. 効率性
- この方法は、追加の計算負荷(Gflops)をほとんど増やさないので、効率的です。
簡単に言うと、インコンテキスト・コンディショニングは、タイムステップやクラスラベルといった追加情報を画像データに混ぜて処理する方法です。この方法は簡単で、特別な修正を加えずに既存の仕組みをそのまま使えるという利点があります。
図5. 異なるコンディショニング戦略の比較について、わかりやすく説明します。
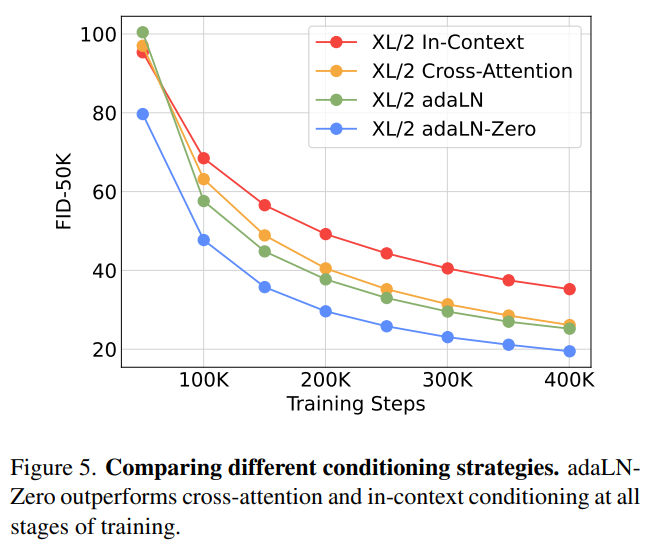
(出典:【論文】Scalable Diffusion Models with Transformers)
1. 何を比較しているのか?
- 図5では、DiTs(Diffusion Transformers)における異なるコンディショニング戦略の性能を比較しています。
2. コンディショニング戦略とは?
- これは、DiTsがタイムステップやクラスラベルなどの追加情報をどのように取り込むかを示す方法です。
3. 3つの戦略
- adaLNZero(適応型レイヤーノルムゼロ): DiTsが最初から安定して働くように、特別な方法で初期化する戦略です。
- クロスアテンション: 画像と追加情報を別々に処理し、後でそれらを結びつける方法です。
- インコンテキストコンディショニング: 追加情報を画像データに混ぜて一緒に処理する方法です。
4. 結果
- 図5によると、訓練の全段階を通じて、DiTsのadaLNZeroが他の2つの方法(クロスアテンションやインコンテキストコンディショニング)よりも一貫して良い結果を出しています。これは、モデルが安定して効果的に学習できることを示しています。
簡単に言うと、DiTsのadaLNZeroという方法が、他の方法よりも優れた性能を発揮して、画像生成において最も良い結果を出した、ということです。
クロスアテンションブロックについて、わかりやすく説明します。
1. クロスアテンションブロックの目的
- クロスアテンションブロックは、DiTs(Diffusion Transformers)内で、画像生成の際に追加の情報、例えばタイムステップ(ttt)やクラスラベル(ccc)などを効率よく組み込むための重要なメカニズムです。これにより、生成される画像がより条件に合ったものとなります。
2. 具体的な方法
- DiTs内部では、タイムステップとクラスラベルを画像のデータとは別に扱い、それらを長さ2のシーケンスとして統合します。このプロセスが「クロスアテンション」の「クロス(交差)」部分にあたります。その後、自己注意ブロックの後にクロスアテンション層を追加して、追加情報を画像トークンと結合します。
3. クロスアテンションの役割
- クロスアテンション層の役割は、画像トークンとタイムステップやクラスラベルの情報をうまく組み合わせ、画像生成の条件をより正確にモデルに理解させることです。このメカニズムにより、画像生成プロセスが柔軟かつ精密になります。
4. オリジナルデザインとの関連性
- この方法は、Vaswaniらが提案した元々のトランスフォーマーモデルのデザインや、LDM(Latent Diffusion Model)でクラスラベルを処理するために使われる方法に似ています。
5. 計算コスト
- クロスアテンションを使うことで、DiTsの計算量(Gflops)が増加します。具体的には、約15%の追加の計算コストがかかります。
簡単に言うと、クロスアテンションブロックは、画像に加えてタイムステップやクラスラベルといった情報をDiTsにうまく取り込むための仕組みです。ただし、この方法を使うと計算が少し重くなります。
適応型レイヤーノルム(adaLN)ブロックについて、わかりやすく説明します
1. 何をする仕組み?
- adaLNブロックは、DiTs(Diffusion Transformers)において、データをうまく処理できるように調整するための仕組みです。この調整は「正規化」と呼ばれる方法を使って行われます。
2. 従来の方法との違い
- 通常の正規化(レイヤーノルム)では、データを一律に処理しますが、**適応型レイヤーノルム(adaLN)**は、状況に応じてデータの処理方法を変えることができます。
3. 具体的な処理
- adaLNでは、データの調整に使うパラメータ(スケールのパラメータ γγγ と シフトのパラメータ βββ)を、直接学習するのではなく、追加の情報(タイムステップ ttt やクラスラベル ccc)から計算します。これにより、データの処理がより柔軟になります。
4. 計算効率の良さ
- adaLNは、他の方法と比べて、計算にかかる負荷(Gflops)が少ないため、非常に効率的です。
5. 同じ関数を適用
- adaLNは、すべてのデータ(トークン)に対して同じ処理を適用します。これは、他の方法にはない特徴です。
簡単に言うと、adaLNブロックは、データを賢く処理するための仕組みで、特に計算が少なく効率的に動くように設計されています。また、すべてのデータに同じ処理を行うことで、一貫性を保ちながらも柔軟に対応できるのが特徴です。
adaLN-Zeroブロックについて、わかりやすく説明します。
1. adaLN-Zeroブロックの背景
- モデルの学習を始める際に、モデルの一部を特定の方法で初期化(設定)すると、学習がスムーズに進むことがわかっています。これは、モデルが安定して動作するための工夫です。
2. 初期化の重要性
- 例えば、ResNetというモデルでは、各ブロックを最初から「恒等関数」という特別な形に初期化するのが有益であることが研究で示されています。これにより、モデルの学習が早く、安定して進みます。同様の方法が、他のモデルでも使われています。
3. adaLN-Zeroの仕組み
- adaLN-Zeroブロックでは、モデルの中で使われるパラメータ(γγγ や βββ)をゼロで初期化することで、最初から安定した学習ができるようにします。
- また、さらにもう一つのパラメータ ααα を導入して、モデルが残差接続(学習がしやすくなる工夫)を行う前に、これを適用します。
4. 具体的な変更点
- adaLN-Zeroは、元々のadaLNブロックに対して、初期化の方法に工夫を加えています。具体的には、γγγ と βββ だけでなく、新たに ααα というパラメータも追加し、それらをゼロから学習するようにしています。
簡単に言うと、adaLN-Zeroブロックは、モデルが安定して学習を始められるように、特別な初期設定を行う方法です。この方法を使うと、モデルが早く、確実に学習を進められるようになります。
表1. DiTモデルの詳細について、わかりやすく説明します。
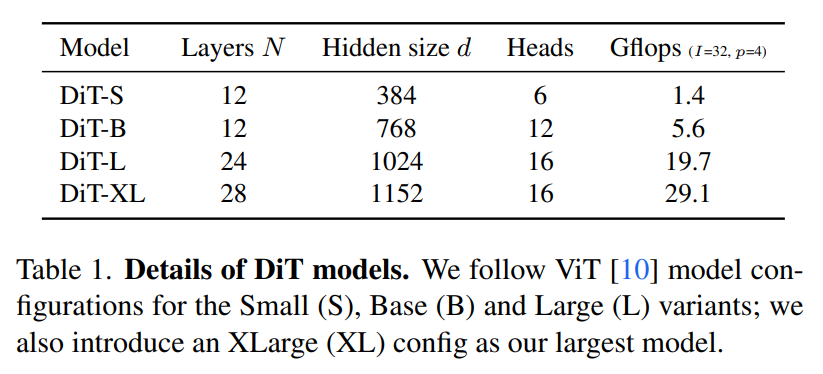
(出典:【論文】Scalable Diffusion Models with Transformers)
1. DiTモデルのバリエーション
- DiTモデルには、サイズに応じて4つのバリエーションがあります。
- Small (S): 小型モデル
- Base (B): 標準モデル
- Large (L): 大型モデル
- XLarge (XL): 最大モデル
- これらは、ViT(Vision Transformer)という元々のモデルの構成に基づいています。
2. 初期化方法
- DiTモデルでは、多層パーセプトロン(MLP)という部分の初期化が重要です。特定のパラメータ(α)をゼロに設定し、全体が「恒等関数」の状態で開始されるようにすることで、学習が安定します。この初期化により、モデルが正確に学習を進める基盤が整います。
3. 計算量の効率性
- adaLN-Zeroの初期化手法は、モデルの計算負荷をほとんど増やさずに効率的な処理を実現します。Gflopsに与える影響が小さいため、DiTは計算効率を維持しつつ学習が可能です。
4. DiTの設計空間
- DiTの設計には、次の4つの要素が含まれています。
- インコンテキスト: 追加情報をトークンとして画像に混ぜて処理する方法。
- クロスアテンション: 画像と追加情報を別々に処理してから結びつける方法。
- 適応型レイヤーノルム(adaLN): 状況に応じてデータを調整する方法。
- adaLN-Zero: 特別な初期化で安定して学習を始める方法。
簡単に言うと、DiTモデルには4つのサイズがあり、特別な初期化方法を使って効率よく学習できるように設計されています。また、モデルには異なる処理方法を取り入れて、より良い性能を引き出せるように工夫されています。
モデルサイズについて、わかりやすく説明します。
1. DiTモデルの構造
- DiTモデルは、「ブロック」と呼ばれる小さな処理ユニットをたくさん積み重ねて動作します。具体的には、隠れ次元サイズ ddd で動作する NNN 個のブロックを順番に適用していきます。
2. トランスフォーマー構成のスケーリング
- モデルのサイズや性能を調整するために、ブロックの数 NNN、隠れ次元サイズ ddd、そして「アテンションヘッド」という処理単位を一緒にスケーリング(大きくしたり小さくしたりすること)します。この手法は、ViT(Vision Transformer)という技術に基づいています。
3. 4つのモデルサイズ
- DiTには、4つの異なるサイズがあります。
- DiT-S: Small(小型)モデル
- DiT-B: Base(標準)モデル
- DiT-L: Large(大型)モデル
- DiT-XL: XLarge(最大)モデル
- これらのサイズは、それぞれ異なる計算量(Gflops)を持っていて、小さいモデルは0.3 Gflops、大きいモデルは118.6 Gflopsに及びます。
4. スケーリングパフォーマンスの評価
- モデルサイズが異なることで、どれだけパフォーマンスが変わるかを評価することができます。表1には、各モデルの具体的な構成の詳細が示されています。
5. 設計空間に追加された構成
- DiTの設計には、これらの4つのモデルサイズ(B、S、L、XL)がすべて含まれていて、それぞれ異なる用途やパフォーマンスの要求に応じて使い分けることができます。
簡単に言うと、DiTモデルには4つのサイズがあり、それぞれのサイズでどれくらいの計算が必要か、どの程度のパフォーマンスが出せるかが異なります。この仕組みを使って、さまざまな用途に応じたモデルを設計できるようになっています。
トランスフォーマーデコーダーについて、わかりやすく説明します。
1. 何をする部分か?
- トランスフォーマーデコーダーは、DiTs (Diffusion Transformers)の最後のステップで、画像のデータを最終的な出力に変換する部分です。
2. 具体的な処理
- DiTが処理した後、画像データ(トークンのシーケンス)を、予測されたノイズや共分散と呼ばれる出力に変換する必要があります。これらの出力は、元の画像と同じ形にする必要があります。
3. 線形デコーダーの役割
- この変換を行うために、「線形デコーダー」という仕組みを使います。線形デコーダーは、トークンを元の画像の形に戻す役割を果たします。
4. 最後の処理
- デコードされたトークンを、元の画像のようなレイアウト(配置)に再配置します。これにより、モデルが予測したノイズや共分散の情報を、元の画像と同じ形に整理することができます。
5. 設計空間の要素
- DiTの設計には、パッチサイズ、トランスフォーマーブロックの構造、モデルサイズといった要素が含まれており、これらを調整してモデルの性能を最適化します。
簡単に言うと、トランスフォーマーデコーダーは、モデルが処理したデータを最終的な画像の形に戻す部分です。このプロセスでは、トークンを元の画像の形にデコードして、予測結果を正しく配置します。
公式Twitter https://x.com/YCrystalmethod
公式LINE https://lin.ee/hWGEoxX

Study about AI
AIについて学ぶ
-

AI社員・AI上司とは何か?企業AIアバター活用の最前線【2026年】
2026年、「AI社員」という言葉をビジネスシーンで耳にする機会が増えています。AIが上司になる、AIが同僚として働く——そんな話題が現実のものになりつつある今...
-

Claude Codeの使い方|インストールからAI設計書生成まで完全実演【2026年最新】
この話について 第1話 / 全10話 2026年3月26日|著者: Kei Kawai|読了: 約15分 Claude Codeとは?2026年最新のAI開発ツ...
-

営業ロープレをAI化するメリットとは?課題をまとめて解決します
「営業ロープレをもっと効率的にできないか」という声は、営業責任者や研修担当者から絶えず聞かれます。ロープレは営業スキル向上に効果的な手法である一方、「相手の確保...