blog
AIブログ
「Diffusion Transformers (DiTs)」とは?わかりやすく解説します!
Diffusion Transformer(DiT)は、拡散モデルにトランスフォーマーアーキテクチャを組み込んだ画像生成手法であり、従来のU-Netベース設計を刷新した重要な技術的ブレークスルーです。2022年にWilliam PeeblesとSaining Xieが発表した論文「Scalable Diffusion Models with Transformers」で提案され、高解像度画像生成においてスケーラビリティと生成品質の両面で優れた特性を示しています。本記事では、DiTの背景・アーキテクチャ・各設計要素・モデルサイズ・実際の性能まで、体系的に解説します。
Diffusion Transformer(DiT)とは何か:背景と開発の動機
拡散モデル(Diffusion Models)は近年の画像生成において中心的な技術となっており、特にU-Netアーキテクチャを活用したモデルはGANs(敵対的生成ネットワーク)を超える生成品質を実現してきました。U-Netは画像の空間的な特徴を階層的に捉えるために設計されており、長らく拡散モデルのバックボーンとして採用されてきました。
一方、トランスフォーマー(Transformer)は自然言語処理のみならず、視覚タスク(Vision Transformer = ViT)においても優れたスケーラビリティを示しています。トランスフォーマーの重要な特性として、「モデルのパラメータ数や計算量を増加させると性能が体系的に向上する」というスケーリング則が挙げられます。このスケーリング特性は、U-Netベースの拡散モデルでは十分に活かされていませんでした。
この課題を解決するために開発されたのがDiTです。拡散モデルのノイズ除去バックボーンをU-NetからTransformerに置き換えることで、「画像生成においてもトランスフォーマーのスケーリング則を活用できるか」という問いに対して肯定的な答えをもたらしました。実験では、モデルのGflops(計算量)を増やすほど生成品質が向上するという明確なスケーリング則が確認されており、これがDiTの最大の貢献のひとつです。
拡散モデルとDiTsの関係
Diffusion Transformers(DiTs)の位置づけ
「Diffusion Transformers(DiTs)」は、画像生成に特化した新しいアーキテクチャです。DiTsは、既存のトランスフォーマー技術をベースに、画像生成タスクに最適化されています。トランスフォーマーはもともとテキストや画像処理に非常に効果的な技術ですが、その特性を活かして、DiTsは画像生成における性能をさらに向上させています。
従来の拡散モデルがピクセル空間で直接ノイズ除去を行っていたのに対し、DiTsは潜在空間(Latent Space)での拡散処理と組み合わせることで、計算効率と生成品質を同時に実現します。これにより、高解像度(256×256、512×512など)の画像生成においても実用的な計算コストで動作します。
Vision Transformer(ViT)との関係
DiTsは「Vision Transformer(ViT)」という画像処理に特化したトランスフォーマー技術に基づいています。ViTでは、画像を小さなパッチ(部分)に分割し、それぞれをトークンとして順番に処理します。DiTsもこの手法を採用し、画像を細かく分割して効率的に学習を行う仕組みを取り入れています。
ViTとの違いは、DiTsが「ノイズ除去」という拡散モデル固有のタスクに対応している点です。具体的には、ノイズが付加された潜在表現を入力とし、タイムステップやクラスラベルなどの条件情報を加えながら、ノイズを予測・除去するように学習します。このプロセスにより、DiTsは画像分類ではなく画像生成に特化した動作をします。
(出典:【論文】Scalable Diffusion Models with Transformers)
潜在拡散モデル(LDMs)について
潜在拡散モデルとは?
LDMs(潜在拡散モデル、Latent Diffusion Models)は、画像生成の計算効率を大幅に向上させるためのアプローチです。高解像度の画像をピクセル空間で直接処理すると計算負荷が非常に高くなるため、LDMsでは以下の2段階のステップを採用しています。
画像の圧縮:エンコード処理
最初に、オートエンコーダー(主にVAE:Variational Autoencoder)のエンコーダを使って画像を圧縮し、低次元の潜在表現に変換します。これにより、元の大きな画像を直接扱わずに、コンパクトなデータとして効率的に処理できます。例えば、256×256×3のRGB画像は、32×32×4の潜在表現に圧縮されます(圧縮率は空間的に8倍)。DiTsはこの潜在表現に対してノイズ付加と除去を行います。
圧縮された情報の利用:デコード処理
拡散モデルが学習・推論したあと、生成された潜在表現をVAEのデコーダで元の画像空間に復元します。この手法により、計算負荷が大幅に減少しつつも、高品質な画像生成が可能になります。DiTsはまさにこのLDMsのフレームワーク上でTransformerバックボーンを動作させており、「潜在空間上のDiffusion Transformer」として機能します。
DiTの入力仕様とパッチ化処理
入力データの構造
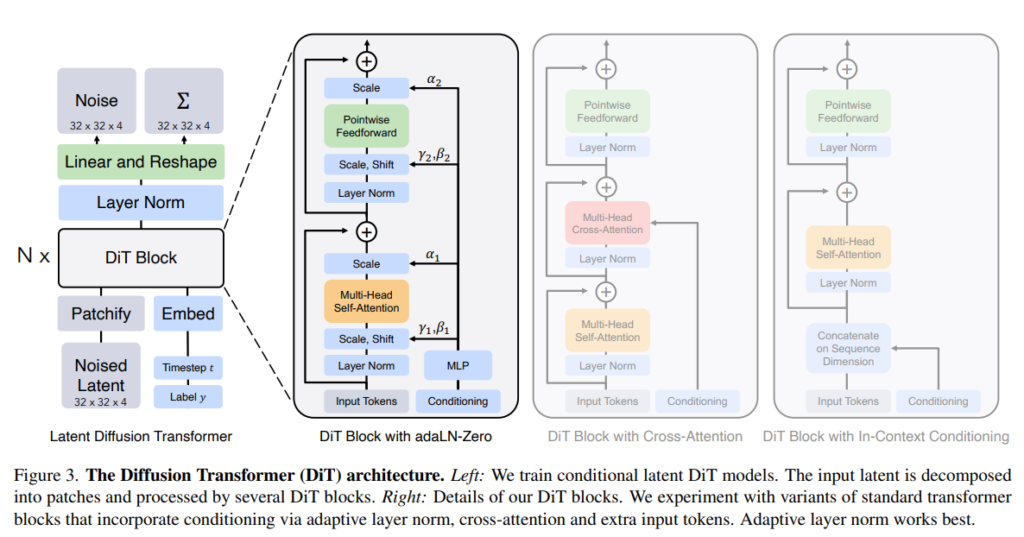
DiT(Diffusion Transformers)は、拡散モデルとトランスフォーマーを組み合わせた画期的な画像生成モデルです。入力は、VAEによってエンコードされた潜在表現であり、形状は I×I×C(Iは空間サイズ、Cはチャンネル数)となっています。ここにノイズが付加された状態が拡散過程の各タイムステップでの入力となります。
トランスフォーマーブロックでは、この画像潜在表現に加えて、タイムステップtやクラスラベルcといった追加情報も処理できます。これにより条件付き生成が可能となり、生成品質が向上します。
(出典:【論文】Scalable Diffusion Models with Transformers)
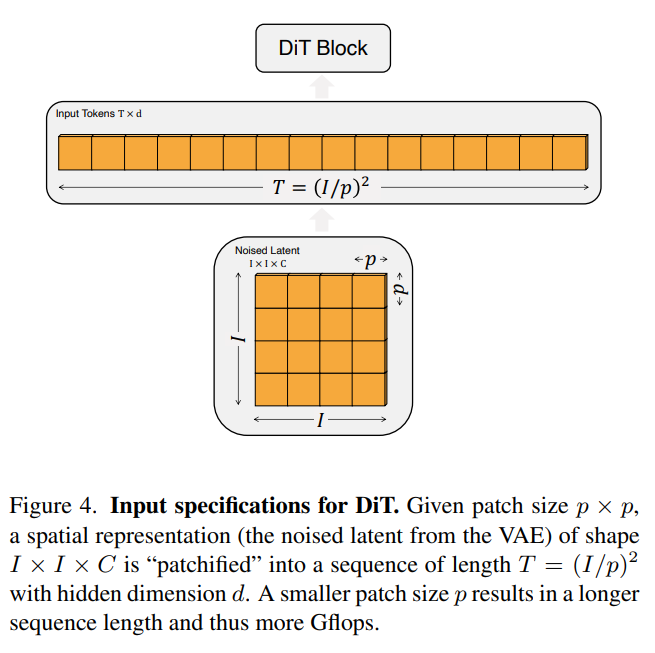
上図では、DiTs(Diffusion Transformers)がどのようにデータを処理するかを説明しています。
- パッチサイズとは?
- 画像を小さなブロック(パッチ)に分割する際のサイズです。パッチサイズが p×p であれば、入力潜在表現を p×p の小さなブロックに分割します。
- 空間表現の意味
- 「空間表現」とは、元の画像がVAEで変換されたデータのことです。具体的には、VAEによってノイズが加えられたデータであり、形状は I×I×C(画像の幅と高さがI、チャンネル数がC)となっています。
- パッチ化とは?
- 画像をパッチに分割することです。分割後、各パッチを順番に処理するために、長さTのシーケンス(トークン列)に変換します。この長さTは、画像サイズIとパッチサイズpによって決まり、T = (I/p)² という式で計算されます。
- パッチサイズと計算量の関係
- パッチサイズpが小さいほど、画像をより細かく分割することになります。その結果、処理しなければならないデータ量(シーケンスの長さ)が増え、計算量(Gflops)が増加します。例えばパッチサイズを半分にすると、トークン数は4倍になります。
Patchify(パッチ化)について詳しく解説
1. Patchifyとは?
Patchifyは、画像を小さな部分(パッチ)に分割して、それぞれの部分をトークンとして処理する方法です。DiTs(Diffusion Transformers)では、最初にこの「パッチ化」というステップを適用します。これはViTと同じアプローチであり、連続した画像データを離散的なトークン列に変換することでトランスフォーマーが処理できる形式にします。
2. 具体的な例
例えば、潜在空間での32×32×4の入力データがある場合、これをパッチサイズp=2で分割すると、16×16=256個のパッチが生成されます。各パッチは2×2×4=16次元のベクトルとなり、線形投影によってトランスフォーマーの隠れ次元dに変換されます。このプロセスにより、モデルは画像の局所的な特徴を効率的に学習できます。
3. パッチ化のプロセス
各パッチを「トークン」と呼ばれるデータの単位に変換します。具体的には、各パッチをフラット化し、線形射影(Linear Embedding)によって隠れ次元dの特徴ベクトルに変換します。これらのトークンにはViTと同様に位置エンコーディング(sinusoidal embedding)が加えられ、空間的な位置情報を保持します。トークン列はDiTsで順番に処理され、全体として画像を再構築します。
4. パッチサイズが変わるとどうなる?
パッチサイズpを小さくすると、画像がより細かく分割されます。その結果、トークンの数Tが増え、DiTsが処理しなければならない計算量(Gflops)も増えます。例えば、パッチサイズを半分にすると、トークンの数は4倍になりますが、Self-Attentionの計算はシーケンス長の2乗に比例するため、計算量は理論上16倍に増加します。
5. パラメータ数への影響
パッチサイズを変えても、DiTsが学習するパラメータの数にはそれほど大きな影響はありません。Self-Attentionのパラメータはシーケンス長に依存しないためです。計算量(Gflops)は大きく増えますが、パラメータ数には大きな変化がないため、同一のモデル複雑度を維持しながら細粒度の処理が可能です。
6. DiTの設計空間におけるパッチサイズ
DiTsの設計では、パッチサイズを2、4、8などに設定してさまざまなバリエーションを試すことができます。例えば、DiT-XL/2はXLargeモデルにパッチサイズ2を組み合わせたもので、論文中で最高の生成品質を達成しています。これにより、モデルの柔軟な設計が可能になり、さまざまな解像度・精度要件のタスクに適応できます。
DiTブロック設計:トランスフォーマーブロックのバリエーション
1. パッチ化後の処理フロー
まず、画像が小さなパッチに分けられます(「パッチ化」)。その後、これらのパッチは「トークン」というデータに変換されます。各トークンは位置エンコーディングと合わせてトランスフォーマーブロックに入力されます。
2. トークンの処理
変換されたトークンは、次に「トランスフォーマーブロック」と呼ばれる処理ユニットを通過します。これは、Self-AttentionとFeed-Forward Networkで構成されており、トークン間の関係性を学習し、次のステップに必要な情報を抽出します。
3. 追加の条件情報
画像に加えて、DiTは他の情報も処理することができます。例えば、ノイズが加えられた画像のタイミング情報(タイムステップt)、画像が属するクラス(クラスラベルc)、さらに自然言語のテキスト埋め込みなどの追加情報が含まれます。これらをどのように組み込むかが、4つのバリエーションの違いとなります。
4. 4つのトランスフォーマーブロックのバリエーション
これらの追加情報をうまく処理するために、論文では4つの異なるトランスフォーマーブロック設計を提案・比較しています。それぞれの設計は、標準的なViTブロックに条件付け情報を組み込む方法が異なります。後述するインコンテキストコンディショニング、クロスアテンション、adaLN、adaLN-Zeroの4方式がこれに相当します。
DiTブロックの4つのコンディショニング方式(概要)
条件トークンを画像トークン列に追加して一緒に処理
画像と条件情報を別々に処理し、交差注意で結合
条件情報からγ・βを生成し適応的に正規化
adaLNにゼロ初期化を加え学習を安定化
インコンテキスト・コンディショニング
1. 何をする手法?
インコンテキスト・コンディショニングは、DiTs(Diffusion Transformers)において、画像に加えて「タイムステップt」や「クラスラベルc」といった追加情報も一緒に処理する手法です。追加情報をトークンとして画像トークン列に結合することで、モデルが文脈情報を自然に学習できます。
2. 具体的な方法
まずDiTsは、タイムステップtとクラスラベルcを、それぞれ「トークン」というデータの単位に変換します(通常は埋め込みベクトルとして表現)。次に、これらのトークンを、画像トークンの列の一部として先頭に追加します。
3. 特別な処理はしない
DiTsでは、追加されたトークンは特別扱いせず、他の画像トークンと同じように処理します。つまり、条件情報トークンも画像の一部として扱われ、Self-Attentionで全トークンと相互作用します。特別な設定や変更は不要です。
4. ViTの仕組みを活用
この手法は、ViT(Vision Transformer)で使われる「clsトークン」と似ています。clsトークンはViTで画像全体の特徴をまとめるために使われるトークンです。インコンテキスト・コンディショニングでは、特別な修正を加えずに標準的なViTの仕組みをそのまま使うことができます。
5. 効率性
この方法は、追加の計算負荷(Gflops)をほとんど増やさないので効率的です。ただし、条件情報トークンが画像トークンの列に追加されることでシーケンス長が若干増加するため、完全にオーバーヘッドゼロというわけではありません。後の比較実験では、adaLN-Zeroより劣る性能であることが示されています。
異なるコンディショニング戦略の比較(図5)
(出典:【論文】Scalable Diffusion Models with Transformers)
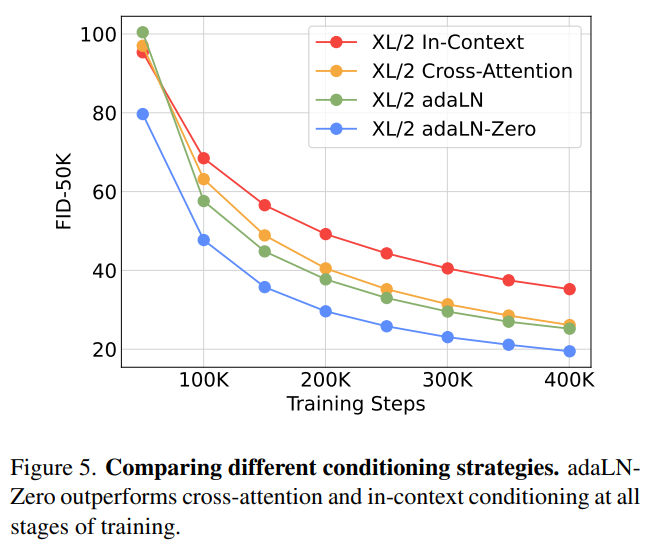
1. 何を比較しているのか?
論文の図5では、DiTs(Diffusion Transformers)における異なるコンディショニング戦略の学習性能を比較しています。評価指標にはFID(Fréchet Inception Distance)が用いられており、値が低いほど生成品質が高いことを示します。
2. コンディショニング戦略とは?
これは、DiTsがタイムステップやクラスラベルなどの追加情報をどのように取り込むかを示す方法です。各戦略によって、学習の安定性・収束速度・最終的な生成品質が異なります。
3. 3つの主要戦略
| 戦略名 | 概要 | 計算コスト | 性能 |
|---|---|---|---|
| adaLN-Zero | ゼロ初期化付き適応型レイヤーノルム | 低(adaLNと同等) | 最高(一貫して優位) |
| クロスアテンション | 画像と条件情報を交差注意で結合 | 約15%増加 | 中程度 |
| インコンテキスト | 条件トークンを画像列に追加 | わずかに増加 | 中程度 |
4. 結果と考察
訓練の全段階を通じて、DiTsのadaLN-Zeroが他の2つの方法(クロスアテンションやインコンテキストコンディショニング)よりも一貫して良い結果を出しています。これは、モデルが安定して効果的に学習できることを示しています。特に学習初期段階での収束の速さが際立っており、ゼロ初期化による恒等関数スタートが学習の安定性に大きく寄与していると考えられます。
クロスアテンションブロック
1. クロスアテンションブロックの目的
クロスアテンションブロックは、DiTs(Diffusion Transformers)内で、画像生成の際に追加の情報(タイムステップtやクラスラベルcなど)を効率よく組み込むための重要なメカニズムです。画像トークンを「クエリ(Q)」、条件情報トークンを「キー(K)・バリュー(V)」として扱い、画像が条件情報を参照しながら処理されます。
2. 具体的な方法
DiTs内部では、タイムステップとクラスラベルを画像のデータとは別に扱い、それらを長さ2のシーケンスとして統合します。このプロセスが「クロスアテンション」の「クロス(交差)」部分にあたります。その後、Self-Attentionブロックの後にクロスアテンション層を追加して、条件情報を画像トークンに組み込みます。
3. クロスアテンションの役割
クロスアテンション層の役割は、画像トークンとタイムステップやクラスラベルの情報をうまく組み合わせ、画像生成の条件をより正確にモデルに理解させることです。このメカニズムにより、画像生成プロセスが柔軟かつ精密になります。特にテキストから画像を生成するモデル(テキスト条件付き生成)では、クロスアテンションがテキスト埋め込みを組み込む標準的な手法として広く使われています。
4. オリジナルデザインとの関連性
この方法は、Vaswaniらが提案した元々のトランスフォーマーモデルのデザイン(encoder-decoder構造)や、LDM(Latent Diffusion Model)でクラスラベルやテキストを処理するために使われる方法に似ています。テキスト条件付きの拡散モデルの多くはこのクロスアテンション方式を採用しています。
5. 計算コスト
クロスアテンションを使うことで、DiTsの計算量(Gflops)が増加します。具体的には、約15%の追加の計算コストがかかります。adaLN系と比較すると計算コストの面で不利ですが、複雑な条件情報(長いテキストシーケンスなど)を扱う場面では有効です。
適応型レイヤーノルム(adaLN)ブロック
1. 何をする仕組み?
adaLNブロックは、DiTs(Diffusion Transformers)において、データをうまく処理できるように調整するための仕組みです。この調整は「正規化」と呼ばれる方法を使って行われます。通常のLayer Normalizationに「適応型」の要素を加えることで、条件情報に応じた動的な正規化が実現します。
2. 従来の方法との違い
通常の正規化(レイヤーノルム)では、データを一律に処理しますが、適応型レイヤーノルム(adaLN)は、状況(条件情報)に応じてデータの処理方法を変えることができます。これは画像生成において特に有効で、同じアーキテクチャでも異なる時刻・クラスに対して異なる処理が可能です。
3. 具体的な処理
adaLNでは、データの調整に使うパラメータ(スケールパラメータγとシフトパラメータβ)を、直接学習するのではなく、追加の情報(タイムステップtやクラスラベルc)から小さなMLPネットワークを通じて計算します。これにより、データの処理がタイムステップやクラスに応じて柔軟に変化します。具体的な処理式は次の通りです:正規化後のテンソルに対して、γ(スケール)を掛け、β(シフト)を加えることで出力が調整されます。
4. 計算効率の良さ
adaLNは、他の方法(クロスアテンションなど)と比べて、計算にかかる負荷(Gflops)が少ないため非常に効率的です。条件情報の処理がMLPによる軽量な変換に留まるため、全体的な計算コストへの影響が最小限です。
5. 同じ関数をすべてのトークンに適用
adaLNは、すべてのデータ(トークン)に対して同じγとβを適用します(トークン位置に依存しない)。これは、クロスアテンションがトークンごとに異なる情報を組み込む方法とは異なります。この一様な処理により計算効率が高まりますが、位置依存の細かな条件付けには向きません。
adaLN-Zeroブロック
1. adaLN-Zeroブロックの背景
モデルの学習を始める際に、モデルの一部を特定の方法で初期化(設定)すると、学習がスムーズに進むことがわかっています。これは、モデルが安定して動作するための工夫です。深いネットワークの学習では、初期の勾配が爆発・消失しやすく、適切な初期化が学習の安定性に直結します。
2. 初期化の重要性
例えば、ResNetというモデルでは、各ブロックを最初から「恒等関数」という特別な形に初期化するのが有益であることが研究で示されています。これにより、モデルの学習が早く、安定して進みます。ゼロ初期化の残差ブロック(ZeroInit)は、学習初期において各ブロックが入力をそのまま通過させるため、勾配が安定して伝播します。同様の方法がDiTsでも活用されています。
3. adaLN-Zeroの仕組み
- adaLN-Zeroブロックでは、モデルの中で使われるパラメータ(γやβ)をゼロで初期化することで、最初から安定した学習ができるようにします。
- さらに、もう一つのパラメータαを導入して、モデルが残差接続を行う前にこれを適用します。αもゼロ初期化することで、各DiTブロックが学習開始時に恒等変換として機能します。
4. 具体的な変更点
adaLN-Zeroは、元々のadaLNブロックに対して、初期化の方法に工夫を加えています。具体的には、γとβだけでなく、新たにαというスケーリングパラメータも追加し、それらをMLPがゼロから出力するように初期化します。これにより、学習開始時は全DiTブロックが恒等関数として機能し、徐々に各ブロックが有用な変換を学習していきます。この「ゼロ初期化」の恩恵として、比較実験においてadaLN-ZeroはadaLN単体よりも明確に優れた生成品質を示しています。
DiTモデルの詳細(表1)
(出典:【論文】Scalable Diffusion Models with Transformers)
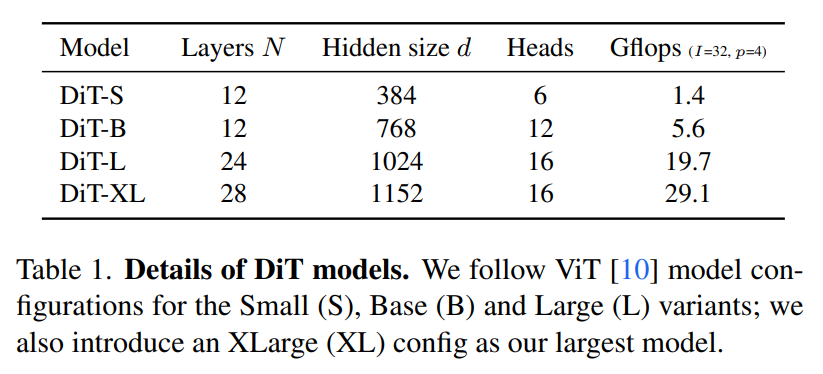
1. DiTモデルのバリエーション
| モデル | ブロック数 N | 隠れ次元 d | アテンションヘッド数 | Gflops(p=4) |
|---|---|---|---|---|
| DiT-S(Small) | 12 | 384 | 6 | 0.3 |
| DiT-B(Base) | 12 | 768 | 12 | 0.7 相当 |
| DiT-L(Large) | 24 | 1024 | 16 | 几十 Gflops |
| DiT-XL(XLarge) | 28 | 1152 | 16 | 118.6 |
これらはViT(Vision Transformer)の構成に基づいており、ブロック数N・隠れ次元d・アテンションヘッド数を同時にスケーリングします。
2. 初期化方法
DiTモデルでは、MLPという部分の初期化が重要です。特定のパラメータ(α)をゼロに設定し、全体が「恒等関数」の状態で開始されるようにすることで、学習が安定します。この初期化により、モデルが正確に学習を進める基盤が整います。
3. 計算量の効率性
adaLN-Zeroの初期化手法は、モデルの計算負荷をほとんど増やさずに効率的な処理を実現します。Gflopsに与える影響が小さいため、DiTは計算効率を維持しつつ学習が可能です。
4. DiTの設計空間のまとめ
DiTの設計空間には次の4つの主要な軸が含まれています。
- インコンテキスト:追加情報をトークンとして画像列に混ぜて処理する方法。
- クロスアテンション:画像と追加情報を別々に処理してから交差注意で結びつける方法。
- 適応型レイヤーノルム(adaLN):条件情報から生成したγ・βで正規化を状況に応じて調整する方法。
- adaLN-Zero:ゼロ初期化付きのadaLNで、安定した学習スタートを実現する方法。
モデルサイズとスケーリング性能
1. DiTモデルの構造
DiTモデルは、「ブロック」と呼ばれる小さな処理ユニットをたくさん積み重ねて動作します。具体的には、隠れ次元サイズdで動作するN個のブロックを順番に適用していきます。各ブロックはSelf-Attention層とFeed-Forward層、そしてadaLN-Zeroによる正規化で構成されています。
2. トランスフォーマー構成のスケーリング
モデルのサイズや性能を調整するために、ブロックの数N、隠れ次元サイズd、そして「アテンションヘッド」という処理単位を一緒にスケーリング(大きくしたり小さくしたりすること)します。この手法はViT(Vision Transformer)の命名・構成規則に基づいており、「DiT-XL/2」のように「モデルサイズ/パッチサイズ」という表記方法が用いられます。
3. 4つのモデルサイズ
DiTには4つの異なるサイズがあり、それぞれ異なる計算量(Gflops)を持っています。小さいモデル(DiT-S/4)は0.3 Gflops程度、最大モデル(DiT-XL/2)は118.6 Gflopsに達します。この広い範囲の計算量により、リソースに応じたモデル選択が可能です。
4. スケーリングパフォーマンスの評価
論文では、モデルサイズが大きくなるほど・計算量が増えるほど、FIDスコア(生成品質の指標)が体系的に改善されることが示されています。これは「拡散モデルにもトランスフォーマーのスケーリング則が適用できる」という重要な知見です。DiT-XL/2はImageNet 256×256においてFID=2.27を達成し、当時の拡散モデルの中でSOTAを記録しました。
5. 設計空間のすべてのモデルサイズを活用
DiTの設計には、これらの4つのモデルサイズ(S、B、L、XL)がすべて含まれており、それぞれ異なる用途やパフォーマンス要求に応じて使い分けることができます。研究目的での素早い実験にはDiT-S、高品質生成にはDiT-XLというように使い分けが可能です。
トランスフォーマーデコーダー:出力の復元
1. 何をする部分か?
トランスフォーマーデコーダーは、DiTs(Diffusion Transformers)の最後のステップで、トランスフォーマーブロックが処理したトークン列を最終的な出力に変換する部分です。拡散モデルの文脈では、この出力は「予測ノイズ(ε)」または「予測信号のスコア」に相当します。
2. 具体的な処理
DiTが処理した後、トークンのシーケンスを予測されたノイズや対角共分散(diagonal covariance)と呼ばれる出力に変換する必要があります。これらの出力は、元の入力潜在表現と同じ形状(I/p × I/p × 2C)にする必要があります。ファクター2は、ノイズ予測と共分散予測の両方を出力するためです。
3. 線形デコーダーの役割
この変換を行うために、「線形デコーダー(Linear Decoder)」という仕組みを使います。具体的には、最終層正規化(Layer Norm)の後に線形変換を適用し、各トークンを p×p×2C 次元のベクトルに変換します。これにより、トークンを元の潜在空間の形に戻す役割を果たします。
4. 最後の処理:再配置(unpatchify)
デコードされたトークンを元の潜在表現のようなレイアウト(空間配置)に再配置します(パッチ化の逆操作)。これにより、モデルが予測したノイズや共分散の情報を、入力と同じ形状の空間的テンソルとして整理することができます。この出力がVAEデコーダーに渡されることで、最終的なピクセル空間の画像が生成されます。
5. 設計空間の要素としてのデコーダー
DiTの設計には、パッチサイズ、トランスフォーマーブロックの構造、モデルサイズ、そしてこの線形デコーダーといった要素が含まれており、これらを適切に組み合わせることでモデルの性能を最適化します。デコーダー部分は比較的シンプルな線形変換で済む点が、U-Netの複雑なアップサンプリングブロックに比べてシンプルかつ効率的な点として挙げられます。
DiTの性能と実用的な応用
DiTsは、ImageNetの高解像度画像生成タスクで、従来のU-Netベースの拡散モデル(ADMやLDMなど)を上回る性能を発揮しています。特にDiT-XL/2は、クラス条件付き256×256画像生成においてFID=2.27を達成し、同等の計算量での比較で最高水準の生成品質を示しました。また、512×512の高解像度生成においてもFID=3.04という優れた性能を記録しています。
DiTsの影響は学術的な研究にとどまらず、実用的な画像生成システムにも広がっています。代表的な例として、Stability AIのStable Diffusion 3やBlack Forest LabsのFLUXシリーズがDiT系アーキテクチャを採用しており、テキストから画像を生成するシステムのバックボーンとして実用化されています。また、動画生成モデル(OpenAIのSoraなど)においてもDiT系アーキテクチャが活用されているとされており、静止画像を超えた時空間的な生成タスクへの拡張が進んでいます。
2026年現在、DiTの後継・発展として「Multi-Modal Diffusion Transformer(MM-DiT)」や「DiT with flow matching」などの改良版が登場しており、テキスト・画像・動画を統合的に扱う基盤モデルのアーキテクチャとしてDiTの設計思想が広く継承されています。
よくある質問
Q. Diffusion Transformer(DiT)とは何ですか?
A. 本文「Diffusion Transformer(DiT)とは何か:背景と開発の動機」で解説しています。
Q. 拡散モデルとDiTはどういう関係ですか?
A. 本文「拡散モデルとDiTsの関係」で整理しています。
Q. DiTはどんな構造になっていますか?
A. 本文「DiTブロック設計:トランスフォーマーブロックのバリエーション」で解説しています。
Q. DiTはどんな性能・用途がありますか?
A. 本文「DiTの性能と実用的な応用」で紹介しています。
まとめ:Diffusion Transformerが切り開く画像生成の新展開
Diffusion Transformers(DiTs)は、トランスフォーマーを基盤とした拡散モデルであり、従来のU-Netベースのモデルに代わる強力なアーキテクチャとして設計されています。高いスケーラビリティ・潜在空間での計算効率・adaLN-Zeroによる安定した学習を特徴とし、画像生成タスクにおいて優れた性能を発揮しています。
本記事で解説したポイントを整理すると、以下の通りです。
- DiTsは拡散モデルのバックボーンをU-NetからTransformerに置き換え、スケーリング則を活用する
- 潜在拡散モデル(LDM)のフレームワーク上で動作し、VAEによる圧縮で計算効率を実現
- Patchifyにより画像を分割してトークン列に変換し、ViTと同様の処理を行う
- コンディショニング方式はadaLN-Zeroが最も優れており、ゼロ初期化が学習安定性の鍵
- S/B/L/XLの4サイズで計算量とモデル性能をトレードオフ選択できる
- Stable Diffusion 3やFLUXなど実用的な生成AIへの応用が広がっている
DiTsは、画像生成だけでなく動画・マルチモーダル生成にも応用が進んでおり、生成AIのアーキテクチャ標準として今後もさらなる発展が期待されます。
監修
河合 継(クリスタルメソッド株式会社 代表取締役)
AI・ディープラーニングに関する特許16件の発明者。過去、国立がん研究センターとの共同研究や、テレビ番組でのAI解説実績を持つAI研究者として、AIの研究開発を主導している。
運営会社について | 編集方針
AIの業務活用をご検討の方へ
クリスタルメソッドは、バーチャルヒューマンをはじめAIの開発・業務導入を支援しています。生成AI・AIエージェントの活用や、自社業務へのAI導入をご検討の際は、お気軽にご相談ください。
- 無料相談・お問い合わせ:ご相談はこちら
Study about AI
AIについて学ぶ
-

OpenAI IPO 日本企業への影響——Bank of America融資が示す資本構造の転換点
Bank of AmericaがOpenAIに融資枠を設定——何が起きたか 2026年7月初旬、Bloombergの報道(Investing.com経由)により...
-

メッセージアプリ ChatGPT連携のビジネス活用:楽天Viber事例が示す次の戦略
楽天Viberの事例が示す「メッセージ×AI」連携の本質 2026年7月7日、楽天傘下のViberはOpenAIとのグローバルパートナーシップ締結を発表し、メッ...
-

OpenAI 新モデル2025-2026、日本企業が今押さえるべき活用ポイント
GPT-5.6シリーズ公開予告——何が起きているか 2026年7月8日付の複数の国際メディア(Asharq Al-Awsat English、The Guard...