blog
AIブログ
BERTって何?応用方法を徹底的に解説
BERTとは、Transformer双方向エンコーダ表現(Bidirectional Encoder Representations from Transformers)の略で、深層学習と呼ばれる学習方法のモデルの一種です。BERTは、過去のNLP(自然言語処理)モデルとは異なり、文章を文頭と末尾の双方向から事前学習するように設計されています。また、学習に使用することができるデータが大量に存在し、与える様々なタスクに対して柔軟な対応が可能という特徴があります。
BERTは2018年にGoogleにより論文で発表されたNLP(自然言語処理)モデルです。NLP(自然言語処理)モデルの性能を評価する指標としてGLUEというものがありますが、そこで当時の最高スコアを獲得しています。
本記事では、AIを専門に研究開発し、NLPを実際に行う会社の視点から
- NLP(自然言語処理)モデルのBERT
- ファインチューニング
- BERTでできること
等、BERTについてわかりやすく解説します。
深層学習の詳細な説明は下記リンクよりご確認ください。
>> ディープラーニング(深層学習)とは?機械学習の違い等を簡単に解説!
NLP(自然言語処理)モデルのBERT
BERTとはNLP(自然言語処理)モデルの一つであり、翻訳や文書分類、質問応答といったNLP(自然言語処理)における仕事の分野のことを自然言語処理タスクと言います。
NLP(自然言語処理)とは?
そもそも自然言語処理とは何か。
NLP(自然言語処理)とは、人間の話し言葉や書き言葉をコンピューターで分析、処理する技術です。わかりやすく言えば、コンピュータに人間が話すことばを理解してもらうことです。
人間のコミュニケーションは複雑ですが、NLP(自然言語処理)により、例えばSNSでの口コミなど不規則な情報も分析することができます。
自然言語処理(NLP)の詳細な説明は下記リンクよりご確認ください。
>> 自然言語処理(NLP)とは?詳しく解説!
NLP(自然言語処理)モデルとは?
NLP(自然言語処理)モデルとは、日常で使用する文章や話し言葉における、各単語の出現確率だけでなく、ある単語の後に別の単語が出現する確率を示したものです。
わかりやすく言うと、文章の自然さを確率によって表現しているモデルということです。
この観点のもとで、近年において、言語モデルは音声認識や機械翻訳、文章の誤り訂正などの自然な文章を扱いたい領域で広く応用されています。
NLP(自然言語処理)モデルには、様々な種類があり、BERTの他に
- GPT-3
- T5
- ELMo
といったモデルがあります。
Transformerとは?
BERTについて理解するためには、Transformerに関する基礎知識が必要です。
Transformerとは、2017年に発表された”Attention Is All You Need”という自然言語処理に関する論文の中で初めて登場した深層学習モデルです。それまで主流だったCNN、RNNを用いたエンコーダーデコーダーモデルとは違い、エンコーダーとデコーダーをAttentionというモデルのみで結んだネットワークアーキテクチャです。それによって、機械翻訳タスクにおいて速いのに精度が高いという特徴を持ち、非常に使い勝手のよいものとなっています。
BERTなどの強力なNLP(自然言語処理モデルの研究の多くは、このTransformerの上に構築されています。
Transformerの詳細な説明は下記リンクよりご確認ください。
>> Transformerとは?AI自然言語学習の技術を解説
BERT導入の背景
BERTが検索エンジンに採用された背景にはモバイル端末の普及による検索クエリの多様化が影響しています。
また、「iPhone」の「Siri」などのAIアシスタントや、スマートスピーカーなどが普及したことによる音声検索の増加が原因だと考えられます。音声検索では、「電気を付けて」「明日の天気は」など、検索ワードが自然言語になりました。
これらの理由により、複雑化した検索ワードに対応することがコンピュータに求められ、BERTが導入されました。
BERTの仕組み
BERTはどのような仕組みで機能しているのでしょうか。
ここからは、BERTの仕組みについて詳しく確認していきましょう。
BERTに入力するためにトークン化する
トークン
トークンとは、あるルールに則り分割された文の構成要素のことです。BERTへの入力を可能にするためには文章を単語レベルに細かく分ける必要があります。ただし、文章を細かく分けたとしてもBERTのようなニューラルネットワークに受け入れることのできる単語の総数は限られており、このときに受け入れられない単語である未知語をできる限り少なくするように工夫する必要があります。単語レベルのトークンを作るときは、MeCabやSudachi、Jumanなどの形態素解析ツールを使用します。
分散表現
分散表現とは、トークンをBERTなどのニューラル言語モデルに入力するために数値化することです。トークンのままだと文字のため、モデル内での数値計算ができません。そのため、分散表現による数値変換が必要となります。
行列表現によって表すことができ、語彙の大きさNとベクトルの次元数Dの積によって表現されます。
Word2VecというPythonのライブラリは、分散表現をするツールの代表例です。
SentencePiece
文章の分割手法の一つであり、サブワードという単位によってトークンを生成します。サブワードとは、単語をさらに分解した部分文字列であり、特に未知語に値する可能性の高い低頻度で出現する単語に対して行われます。SentencePieceによって分けられた文章はBERTへの入力の効率を大幅に高める重要な機能となっています。
Byte Pair Encoding
SentencePieceを行う際に用いられているアルゴリズムがByte Pair Encodingです。日本語ではバイト対符号化と呼ばれ、データ圧縮のやり方の一つになります。このアルゴリズムの特性は、2つのワードを1つのワードに連結するところでありこの性質によってサブワードを統合することが可能になります。
AttentionとTransFormer Encoderについて
Multi-head Attention
まずAttentionとは、複数個ある入力の中から、どこを注目すべきか学習する仕組みである。
そしてMulti-head Attentionは、Attentionを複数回並行して実行するモジュールである。独立したAttentionの出力は次に連結され、期待される次元に線形変換される。直感的には、複数のAttentionヘッドにより、シーケンスの一部に異なるAttentionを払うことができます(例えば、長期の依存性と短時間の依存性など)。
このモジュールではscaled dot-product attentionが最もよく使われるが、原理的には他のタイプのアテンション機構に置き換えることができることに注意してください。
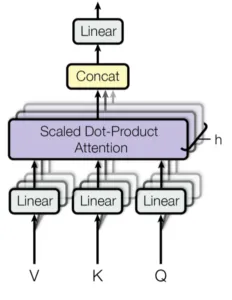
(出典:【論文】Attention Is All You Need)
scaled dot-product attention
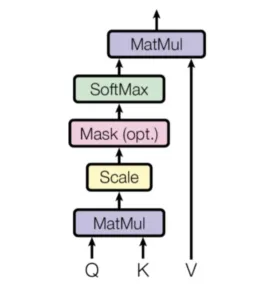
(出典:【論文】Attention Is All You Need)
スケールドドットプロダクトアテンションは、ドットプロダクトがスケールダウンされたアテンション機構です。
形式的には、クエリーQ、キーK、値Vがあり、アテンションは次のように計算される。
Q,Kの内積を求め、標準化して、データフレーム中、条件に一致する場合にだけ値を変更、その後ソフトマックス関数の出力結果と、Vとの内積を求めます。
Residual Connection
Residual Connectionとは、日本語に訳すと「残差接続」といい、学習時に逆伝播しやすくするのと、前の情報を忘れないようにする目的のものです。
Residual Connectionは主に消失勾配の問題を軽減するのに役立つ。バックプロパゲーションの間、信号は活性化関数の微分によって乗算される。ReLUの場合、約半分のケースで勾配がゼロになることを意味する。Residual Connectionがなければ、バックプロパゲーション中に学習信号の大部分が失われてしまう。
Residual Connectionのもう一つの効果は、情報がTransformer層のスタックにローカルに留まることである。自己注意のメカニズムは、ネットワーク内の任意の情報の流れを可能にし、その結果、入力トークンを任意に並べ替えることができる。しかし、Residual Connectionは、元の状態が何であったかを復元させる。
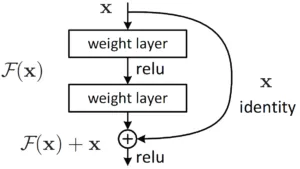
(出典:Residual Connection/Papers With Code)
層正規化(Layer Nomalization)
層正規化は代表的な正規化層の1つであるバッチ正規化を改良したもので、Transformerモデルの注目により広く活用されるようになりました。
バッチ正規化とは異なり、層正規化は、隠れ層内のニューロンへの合計入力から正規化統計量を直接推定するため、正規化によって学習ケース間に新たな依存関係が生じることはない。これはRNNに有効で、いくつかの既存のRNNモデルの学習時間と汎化性能の両方を向上させることができます。
層正規化では、ある層のすべての隠れユニットが同じ正規化項と、異なる学習ケースで異なる正規化項を共有する。バッチ正規化とは異なり、層正規化はミニバッチのサイズに制約を課さないので、バッチサイズ1の純粋なオンライン領域で使用することができる。
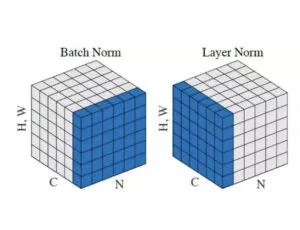
(出典:Layer Nomalization/Papers With Code)
FFN(Feedforward Network)
FFNは日本語では「順伝播型ニューラルネットワーク」といいます。GELU関数の後に、Residual Connectionと層正規化を適用して、Encoder出力が生成されます。
(出典:Feedforward Network/Neural Networks)
フィードフォワードネットワークには次のような特徴があります。
1. パーセプトロンは層状に配置され、最初の層が入力を受け、最後の層が出力を出す。中間の層は外界との接続がないため、隠れ層と呼ばれる。
2. ある層の各パーセプトロンは、次の層のすべてのパーセプトロンとつながっている。このため、フィード・フォワード・ネットワークと呼ばれる。
3. 同じ層のパーセプトロン同士は接続されていない。
BERTの学習
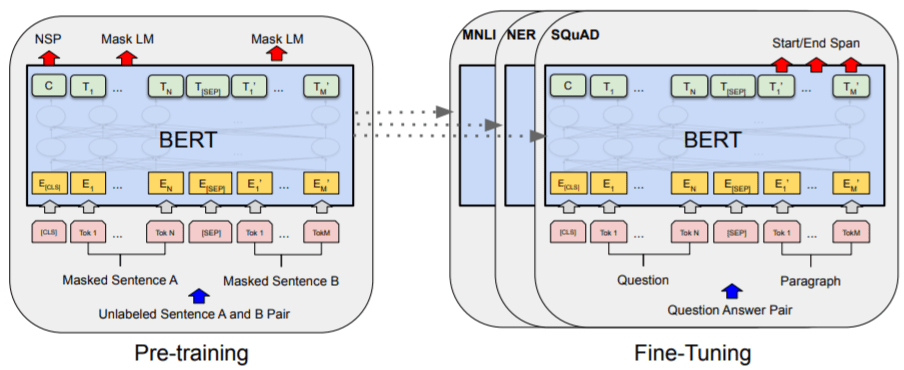
【論文】BERT:Pre-training of Deep Bidirectional Transformers for Language Understandingより引用
BERTの学習には事前学習とファインチューニングと呼ばれる2つの過程があります。
この事前学習とファインチューニングについて詳しく見ていきましょう。
事前学習とは?
事前学習とは、深層学習の精度を改善する手法です。
これは、大規模な文章を用いて汎用的な言語パターンを学習するために行われます。
学習というと一般的にモデルに対して入力データとそれに対する出力の関係を人間が付与したラベル付きデータを用いて学習させるというイメージを持つ人が多いかもしれません。
しかし、BERTの事前学習で用いるデータは生の文章データのみです。
このようなラベル付けされていないデータのことをラベルなしデータといいます。
ラベルなしデータを用いるメリットは、比較的容易に大量のデータを収集できることです。
しかし、ラベルなしデータを用いる場合に、モデルに何を学習させれば良いのかということがラベル付きデータを用いた学習と比べて自明ではなく、何らかの対策が必要となります。
そこでBERTではMasked Language ModelとNext Sentence Predictionという2つの方法を組み合わせて大量の文章データから学習を行っています。
では、このMasked Language ModelとNext Sentence Predictionとはどういった方法なのか詳しく見ていきましょう。
Masked Language Model
Masked Language Modelでは、BERTでテキストの一部を[MASK]という別の単語で置き換えたテキストを入力します。
BERTは、ある単語を周りの単語から予測するというタスクを用いて、単語の入出力関係を学習を行っています。
例えば、「私が習っているスポーツは野球で、いつかメジャーリーグでプレイしたい。」の「野球」という単語が[MASK]で置き換えられた場合、文章中の「スポーツ」、「メジャーリーグ」、「プレイ」などの単語から[MASK]によって置き換えらえた単語が元々の「野球」でありことを予想します。」
具体的には、まずランダムに選ばれた15%のトークンを[MASK]という特殊トークンに置き換えます。そして、置き換えられた文章をBERTに入力し、[MASK]の位置に元々あったトークンを予測するというタスクを用いて学習を行います。
つまり、[MASK]に置き換えられたトークンを、[MASK]を含む文章に対するラベルとして扱うことで、その入出力関係を学習します。
Next Sentence Prediction
Next Sentence Predictionでは、単語単位での学習はできますが、文単位での学習はできません。
そこで、Next Sentence Predictionという手法を用います。
Next Sentence Predictionは、2つの文章の関係性について予測するタスクです。
そのため、事前学習時にはBERTには常に2つの文のペアが入力されます。
この時、2つの文のうち、後の文が50%の確率で前の文と無関係な文に置き換えられます。
ここで、入力された2つの文が連続したものであるか、そうでないかを判定するタスクを繰り返し、学習を行います。
例えば、
「男は[MASK]店に行った。彼は500mLの[MASK]を購入した。 → IsNext(連続)
「女は店に[MASK]。猿が[MASK]から落ちた。 → NotNext(不連続)
具体的には、2つの文を[SEP]というトークンで分けます。
また、特殊トークン[CLS]に対応するBERTの出力を分類機に入力し、2つの文章が連続しているときは、IsNext、そうでなければNotNextの判定をします。
これらにより、2つの文の関係性を学習することができます。
ファインチューニングとは?
BERTの学習済みモデルは、そのまま使うことは珍しく、一般に、解きたいタスクに応じて特化するようにします。
ファインチューニングでは、比較的少数のラベル付きデータを用いて、BERTを特定のタスクに特化するように学習します。
BERTで個別のタスクを解くためには、タスクの内容に応じてBERTに新しい分類機などを接続するなどして、タスクに特化したモデルを作ります。つまり、言語タスクにおいて、BERTは特徴抽出機のような働きをします。
ファインチューニングを行うときにはモデルの初期値として、事前学習で得られたパラメータを用い、新たに加えられた分類器のパラメータにはランダムな値を与えます。そして、ラベル付きデータを用いてBERTと分類器の両方のパラメータを学習します。
このように、ファインチューニングの際事前学習で得られたパラメータを初期値として用いることで比較的少数の学習データでも高い性能のモデルを得ることができます。
BERTで何ができる?
BERTでは何ができるのでしょうか。ここでは、BERTでできることを紹介します。
文書分類

株式会社日立ソリューションズが独自技術の文書分類アプリ「活文 知的情報マイニング」にBERTを導入した事例です。
2019年11月25日に株式会社日立ソリューションズは独自技術の文書分類アプリ「活文 知的情報マイニング」にBERTを導入したと発表しました。
こちらは、大量の自然文テキストを分析し、分類する業務を自動化するものになります。
現在では世界的に導入が進んでいます。
検索エンジン

Googleが検索エンジンにBERTを導入した事例です。
Googleは2019年10月25日に検索エンジンにBERTを導入したと発表しました。
発表時はアメリカGoogleの英語検索のみに導入されていましたが、同年12月10日に日本語を含む70以上の言語に展開されました。
チャットボット

株式会社ユーザーローカルが提供している「サポートチャットボット」の事例です。
チャットボットとは、人工知能を活用した自動応答システムのことです。
「サポートチャットボット」では、BERTの導入によって、チャットボットの構築を自動化することが実現可能になりました。
一般的に、チャットボットが回答を自動化するためには、質問に対する回答のロジックの設定などを行います。そのため、システムを稼働させるまでに多くの時間が必要でした。
しかし、BERTの活用によって、問い合わせ履歴をもとに構築していくことで、構築期間の圧縮や工数の削減が可能になります。なお、この「サポートチャットボット」を利用する場合には、導入先企業はプログラムの記述などの必要なく、システムを利用することができます。
BERTの特徴
では、BERTの発表によって、どのようなことが実現されたのか、BERTの特徴について解説していきます。
文脈理解
BERTが発表されるまでは、GPTやELMoといった言語処理モデルが活用されていました。
GPTは未来の単語のみを予測する単一方向モデル、ELMoは双方向モデルであり、文脈を読むことは不可能でした。
しかし、BERTが導入されてからは、単語動詞のつながり、つまりは文脈を読み取ることができるようになりました。
汎用性
BERTには、汎用性が高いという特徴があります。
既存のタスク処理モデルの場合、特定のタスクに特化していました。
一方、BERTであれば、既存のタスク処理モデルの前にファインチューニングすることにより、簡単に自然言語処理の精度を高められるようになりました。
そのため、BERTは汎用性が高いという点で評価されています。
学習データ不足の克服
事前学習の章で述べましたが、BERTの学習にはラベルなしデータを用います。
現時点では、自然言語処理タスクを目的としたラベル付きデータの絶対数は少なく、入手が困難な状態です。
また、生の文章にラベルを付与し、ラベル付きデータを生成するためには、莫大な時間と労力がかかります。
その点、ラベルなしデータは大量に存在しているため、入手することは容易です。
そのため、BERTは学習データが不足しないという点で評価されています。
後継モデル
このように強力なBERTですが、2018年に登場してから、改良版のRoBERTaや、さらに軽量化したALBERTなど様々な後継モデルが考案されています。
The General Language Understanding Evaluation (GLUE) benchmark について
GLUEベンチマークは、自然言語理解システムの学習・評価・解析のためのリソースを集めたものであり、以下のもので構成されています。
・既存のデータセットを基に、データセットのサイズ、テキストのジャンル、難易度など様々な観点から選択した9文または文対の言語理解タスクからなるベンチマーク。
・自然言語で見られる様々な言語現象に関するモデル性能を評価・分析するために設計された診断用データセット。
・ベンチマークでのパフォーマンスを追跡するための公開リーダーボードと、診断セットでのモデルのパフォーマンスを可視化するためのダッシュボード。
GLUEベンチマークの形式はモデルに依存しないため、文と文のペアを処理し、対応する予測を生成できるシステムであれば、誰でも参加することができます。ベンチマークタスクは、パラメータ共有や他の転移学習技術を使ってタスク間で情報を共有するモデルを優先して選択されています。GLUEの最終的な目標は、一般的で堅牢な自然言語理解システムの開発研究を推進することです。
GLUE datasetについて
GLUE datasetは、GLUE Benchmarkよりリリースされている、深層学習の自然言語処理各タスクを利用するためのデータセットです。
タスクには”CoLA”, “SST”, “MRPC”, “QQP”, “STS”, “MNLI”, “QNLI”, “RTE”, “WNLI”, “diagnostic”などがあります。
単文タスクCoLAとSST-2、類似・言い換えタスクMRPC、STS-B、QQP、自然言語推論タスクMNLI、QNLI、RTE、WNLIの9つの自然言語理解タスクの集合体です。
SQuADとは
SQuADは、The Stanford Question Answering Datasetの略称で、クラウドソーシングによる質問と回答のペアのコレクションです。
Wikipediaの記事に対してクラウドワーカーが出した質問からなる読解力データセットで、すべての質問に対する答えは、対応する読解箇所であるか、または質問が回答不能である場合があります。
SWAGとは
彼女は車のボンネットを開けたというような部分的な記述があれば、人間はその状況を推論し、次にその後、彼女はエンジンを調べたなど、何が起こるかを予測することができる.
SWAG (Situations With Adversarial Generations) は、この常識推論のための大規模データセットです。
このデータセットは、多肢選択問題から構成されている。各問題はLSMDCまたはActivityNet Captionsのビデオキャプションであり、そのシーンで次に何が起こりうるかについての4つの回答選択肢を持っています。正解はビデオの次のイベントに対する(実際の)ビデオキャプションであり、3つの不正解は機械は騙せるが人間は騙せないように、敵対的に生成され人間が検証したものである。
【まとめ】BERTとは?

本記事では、BERTとは何か、その仕組みから活用事例までご紹介しました。
AIは様々なシーンで活用されはじめています。
その中でも特に自然言語処理技術の発展に注目が集まっています。
現時点で課題はあるものの、今後の技術の発展により、人間並みの自然言語理解に近づき、より多くの分野での応用が期待されます。
これからのBERTを用いた技術動向には目が離せませんね!!
この記事を呼んでいただき弊社での取り組みに興味を持っていただけた方は是非SNSも確認してください!
クリスタルメソッド公式note:https://note.com/crystalmethod/
X:https://x.com/YCrystalmethod
YouTube:https://www.youtube.com/@haltalktube
TikTok:https://www.tiktok.com/@crystalmethod.jp
Study about AI
AIについて学ぶ
-

営業ロープレをAI化するメリットとは?課題をまとめて解決します
「営業ロープレをもっと効率的にできないか」という声は、営業責任者や研修担当者から絶えず聞かれます。ロープレは営業スキル向上に効果的な手法である一方、「相手の確保...
-

AIロープレとは?営業・接客・面接練習での活用法を解説します!
人手不足が深刻化し、新人教育の「早期戦力化(イネーブルメント)」が企業の最重要課題となる中、教育現場に破壊的なイノベーションが起きています。 従来のコミュニケー...
-

AIロープレツールの選び方|比較ポイントと主要ツール比較を解説
「AIロープレを導入したいが、どのツールを選べばいいかわからない」という声をよく聞きます。AIロープレツールは種類が増えており、対応している業種・機能・価格もさ...