blog
AIブログ
クラスタリングとは | 分析の手法などをわかりやすく解説!
クラスタリングとは、教師なし学習と呼ばれる機械学習の一手法で、正解ラベルを与えずにデータの類似性・距離に基づいてグループ(クラスタ)に自動分類する技術です。クラスタ分析とも呼ばれ、マーケティングのセグメンテーションから異常検知・画像認識まで、幅広いビジネス課題に活用されています。本記事では、AIの研究開発に携わる専門家の視点から、クラスタリングの概要・特徴・代表的な手法・メリット・デメリットをわかりやすく解説します。
クラスタリングとは
機械学習は大きく「教師あり学習」と「教師なし学習」の二つに分類されます。クラスタリングは教師なし学習に属します。
教師なし学習とは、正解データ(ラベル)を与えずにデータそのものに潜む構造やパターンを発見する学習方法です。正解と不正解が明確に定義された問題に有効な教師あり学習とは異なり、教師なし学習は「まだ答えが存在しない」状況、たとえば新市場の開拓や未知の顧客層の発見といった探索的な問題に適しています。
その教師なし学習の代表的手法がクラスタリングです。与えられたデータの特徴量を解析し、互いに似ているデータ点を同じクラスタ(グループ)にまとめます。対象となるデータは顧客属性・購買履歴・テキスト・画像・センサーデータなど多岐にわたり、顧客セグメンテーション・市場分析・異常検知・文書分類など幅広い場面で活用されます。
分類との違い
データをグループ分けするという点で「分類(Classification)」と混同されがちですが、両者は本質的に異なります。
| 比較項目 | クラスタリング | 分類(Classification) |
|---|---|---|
| 学習の種類 | 教師なし学習 | 教師あり学習 |
| 正解ラベル | 不要 | 必要 |
| グループの定義 | データから自動発見 | 事前に人間が定義 |
| 主な目的 | 未知の構造・パターンの発見 | 既知のカテゴリへの振り分け |
| 活用例 | 顧客セグメント発見・市場開拓 | スパム判定・画像認識 |
分類は「すでにあるデータを参考に、新しいデータが既知のカテゴリのどれに当てはまるかを予測する」手法です。一方、クラスタリングは明確な正解を持たず、データを分けること自体が目的ではなく、グループ分けを通じて新たな知見・市場を発見することに本質的な目的があります。
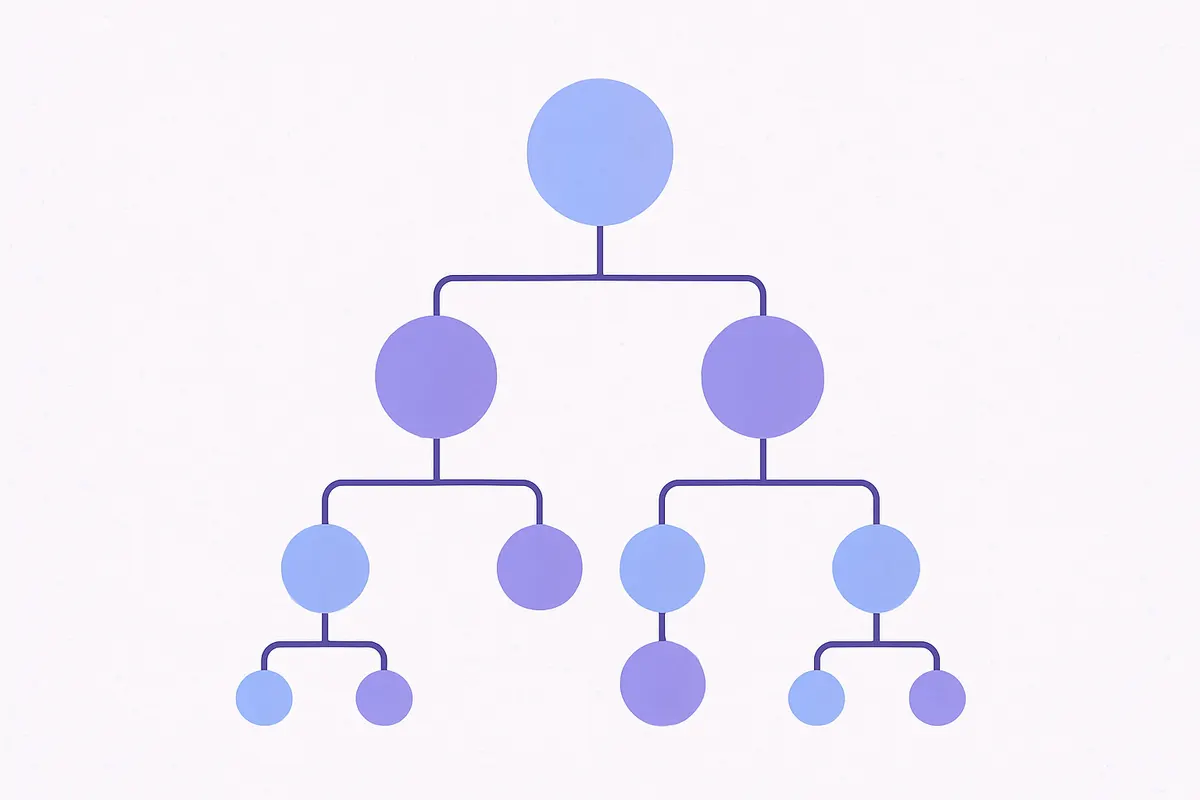
階層クラスタリングと非階層クラスタリング
クラスタリングは大きく「階層クラスタリング」と「非階層クラスタリング」の2種類に分けられます。それぞれ特性が異なり、データの性質や分析目的に応じて使い分けることが重要です。
階層クラスタリングとは、データを段階的に統合(または分割)しながら、樹形図(デンドログラム)状のグルーピング構造を構築する手法です。たとえば寿司ネタを例にすると、まず「赤身・白身」と大きく二分し、赤身の中をさらに「マグロ・サーモン・カツオ」に分け、マグロをさらに「大トロ・中トロ・赤身」と細分化するイメージです。グルーピングの過程が樹形図として可視化されるため結果が直感的に把握しやすく、サンプル数が少ない場合に特に有効です。
非階層クラスタリングとは、あらかじめクラスタ数を決定し、その数のグループにデータを割り振る手法です。階層構造を作らないため計算コストを抑えやすく、大量データにも適用しやすいのが特徴です。ただし、最適なクラスタ数を自動で決定する汎用的な方法が確立されていないため、分析者がエルボー法やシルエット係数などを参考にしながら適切なクラスタ数を検討する必要があります。
- 樹形図(デンドログラム)で可視化
- サンプル数が少ない場合に有効
- グループ数を事前に決めなくてよい
- 大規模データでは計算コストが高い
- あらかじめクラスタ数kを指定
- 大量データに対応しやすい
- 計算が比較的高速
- クラスタ数の決定が課題
クラスタリングの手法を導入するメリットとデメリット
クラスタリングはビジネス上の多くの問題に応用できる一方、固有の限界も存在します。導入前にメリットとデメリットの両面を正確に理解しておくことが重要です。
メリット
- 効果的なセグメンテーションが行える
- 差別化戦略や市場の空白を発見できる
- アンケート・テキストデータのパターンを抽出できる
- ラベルなしデータからも知見を得られる
セグメンテーションとは、市場に存在する顧客を年齢・購買行動・地域・嗜好などの多様な観点からグループ分けすることです。顧客をグループ化することで、自社製品を最も必要としているターゲットに的確にアプローチできるほか、グループごとの特性を新製品開発や広告戦略に活用できます。クラスタリングはこのセグメンテーションを人手ではなくデータドリブンで実現するため、主観バイアスを排除した精度の高い市場分析が可能になります。
差別化戦略・市場の空白発見においても、クラスタリングは力を発揮します。競合他社の製品をクラスタリングの対象にすることで、市場に存在する製品群の特徴や偏りが可視化され、どのポジションがまだ埋まっていないか(空白地帯)を把握しやすくなります。その空白地帯への参入は、新たな市場開拓と競合優位の確保に直結します。
アンケート・テキストデータの分析でも効果的です。市場調査や製品テストで収集した自由記述回答は一見バラバラに見えますが、クラスタリングを適用することで類似した意見・要望をグループ化でき、隠れたニーズやクレームのパターンを系統的に把握することができます。
さらに、クラスタリングは正解ラベルが存在しないデータにも適用できるという根本的な強みがあります。ラベル付けのコスト・時間が省けるため、新しいドメインへの素早い探索的分析に向いています。
デメリット
- データ量の増加に伴い計算コストが急増する(特に階層クラスタリング)
- 非階層クラスタリングはクラスタ数の設定に依存し、再現性が下がる場合がある
- 結果の解釈・評価基準が主観的になりやすい
- 外れ値・ノイズの影響を受けやすい手法がある
階層クラスタリングはデータ数が増えると計算量が爆発的に増加し、数万件以上のデータでは処理時間が現実的でなくなる場合があります。また、デンドログラムが複雑になり過ぎて結果の解釈が困難になることもあります。
非階層クラスタリング(k平均法など)では、最初にクラスタ数kを自分で決める必要があります。これを初期値依存といい、kの設定や初期値の乱数によって結果が変わるため、安定した再現性のある結果を得るには複数回の試行と検証が必要です。エルボー法(クラスタ数を変えながら誤差平方和の推移を確認する方法)やシルエット係数(クラスタ内の凝集度とクラスタ間の分離度を数値化した指標)などを活用してkを選ぶことが推奨されます。
また、クラスタリングには「正解」が存在しないため、得られたクラスタが本当に意味のある区分けかどうかは分析者の解釈に委ねられる面があります。ビジネス上の知識と組み合わせた解釈の質が最終的な分析価値を左右します。
クラスタリングの手法・アルゴリズム
クラスタリングの多くの手法では、データ点間の「距離」を類似度の指標として使用します。最も基本的な指標がユークリッド距離で、二点間の直線距離に相当します。距離が近いデータ点ほど「似ている」と判断して同じクラスタに分類します。以下に代表的なアルゴリズムを紹介します。
群平均法(平均連結法)
階層クラスタリングの代表的手法の一つです。二つのクラスタ間に含まれるすべての点の組み合わせにおける距離の平均値をクラスタ間距離として定義し、この平均距離が最も小さいクラスタ同士を順番に統合していきます。
最も近い点同士でクラスタを統合する「単連結法(最短距離法)」と、最も遠い点同士の距離でクラスタを統合する「完全連結法(最長距離法)」の中間的なアプローチに当たります。一つだけ大きく外れた外れ値が存在しても、その影響を平均化によって緩和できる点が強みです。
ウォード法(最小分散法)
階層クラスタリングの中でも実務で最も広く使われる手法の一つです。二つのクラスタを統合した場合に、クラスタ内分散(各点と重心の距離の二乗和)の増加量が最小になる組み合わせを選んで統合します。
群平均法と同様に外れ値の影響を受けにくく、形状が均等で円状のクラスタが形成されやすい特徴があります。クラスタ内がコンパクト(密集)になるように統合を繰り返すため、視覚的にも解釈しやすいデンドログラムが得られることが多いです。
k平均法(k-means法)
非階層クラスタリングの中で最も広く知られたアルゴリズムです。kはクラスタ数を意味し、以下の手順で繰り返しグループを更新します。
処理が高速で大規模データにも対応しやすいため実務で広く採用されています。ただし、初期重心をランダムに配置する性質上、初期値によってはクラスタ重心が近接してしまい、最適な分類に収束しない場合があります。
この弱点を補う手法としてk-means++があります。k-means++では、最初の重心は通常通りランダムに選びますが、2つ目以降の重心は既存の重心からの距離が大きい点ほど高い確率で選ばれるよう設計されています。これにより初期重心が偏らずに分散して配置され、最終的なクラスタリングの品質と安定性が向上します。現在、多くの機械学習ライブラリ(scikit-learnなど)ではk-means++がデフォルト設定となっています。
その他の主要手法
上記の三手法以外にも、目的やデータ特性に応じて選択される主要なアルゴリズムがあります。
| 手法名 | 種別 | 特徴・適した場面 |
|---|---|---|
| DBSCAN | 密度ベース | クラスタ数の指定不要。不規則な形状のクラスタや外れ値の検出に強い。ノイズを自動除外できる |
| 混合ガウスモデル(GMM) | 確率モデル | 各データ点がどのクラスタに属するかを確率で表現。楕円形クラスタにも対応 |
| スペクトラルクラスタリング | グラフベース | データ間の類似度グラフをもとに分割。非線形・複雑な形状のクラスタに有効 |
| 凝集型クラスタリング(Agglomerative) | 階層型 | 各データ点を個別クラスタとして開始し、逐次統合。Ward法・群平均法などの連結基準を選択可能 |
クラスタリングの実際の活用場面
クラスタリングはマーケティング分析以外にも、現代のビジネス・研究の多様な場面で活用されています。
- 顧客セグメンテーション:購買履歴・行動データをもとに顧客を自動的にグループ化し、One to Oneマーケティングや製品レコメンドに活用
- 異常検知・不正検出:通常の取引パターンとは大きく異なるデータ点(外れ値クラスタ)を検出し、金融詐欺や機器の故障予兆を特定
- 文書・テキスト分類:ニュース記事や問い合わせ内容をクラスタリングし、トピック自動分類・FAQ整理に利用
- 画像・動画解析:類似画像のグループ化、医療画像における組織の自動分類など
- バイオインフォマティクス:遺伝子発現データのクラスタリングによる病型分類・薬剤応答予測
- 地理・都市分析:GPS位置データや人口統計データをクラスタリングし、商圏分析・配送ルート最適化に活用
まとめ
クラスタリングは、正解ラベルを必要としない教師なし学習の代表的手法であり、データに潜む未知のグループ構造を自動的に発見できる点が最大の特徴です。本記事の要点を整理します。
- クラスタリングは教師なし学習に属し、分類(教師あり学習)とは学習方法・目的が異なる
- 階層クラスタリングはデンドログラムで過程を可視化でき少量データに有効、非階層クラスタリングは大量データに対応しやすいがクラスタ数の決定が課題
- 代表的手法として群平均法・ウォード法(階層型)、k平均法・k-means++(非階層型)、DBSCAN(密度ベース)などがある
- マーケティングのセグメンテーション・差別化戦略・市場空白の発見から、異常検知・テキスト分析・医療分野まで幅広く活用されている
- データ量増加による計算コスト・初期値依存・結果解釈の主観性などの限界も理解した上で活用することが重要
クラスタリングは「まだ答えが見えていない問題」に対して強力な探索ツールとなります。市場調査・顧客分析・新規事業開発など、データドリブンな意思決定を進める際は、ぜひクラスタリングをファーストステップの分析手法として検討してみてください。
監修
河合 継(クリスタルメソッド株式会社 代表取締役)
AI・ディープラーニングに関する特許16件の発明者。過去、国立がん研究センターとの共同研究や、テレビ番組でのAI解説実績を持つAI研究者として、AIの研究開発を主導している。
運営会社について | 編集方針
Study about AI
AIについて学ぶ
-

OpenAI×企業・教育機関AI連携事例:日本企業が今すぐ検討すべき戦略
OpenAI×FEU Tech提携:企業・教育機関AI連携の最新事例が示す構造変化 2026年6月、フィリピンのFar Eastern University I...
-
Anthropic AI研究者採用動向——ノーベル賞受賞者移籍が日本企業に問うもの
ノーベル賞受賞AI研究者がAnthropicへ——何が起きたのか 2026年6月19日(金)、ジョン・ジャンパー(John Jumper)がGoogle Dee...
-

AIエージェント デジタルID ガバナンス 責任追跡——エストニア構想が日本企業に突きつける問い
エストニアが示した「AIエージェント デジタルID」の核心——なぜ今、責任追跡が問われるか 2026年6月17日前後、エストニアのKristen Michal首...