blog
AIブログ
ディープラーニング(深層学習)とは何か?機械学習との違い等をわかりやすく解説します!
ディープラーニング(深層学習)は、画像認識・自然言語処理・自動運転など、現代のAI技術を支える中核的な仕組みです。しかし「AIとどう違うのか」「機械学習との関係は何か」といった問いに正確に答えられる人は多くありません。本記事では、AIを専門に研究開発する会社の視点から、ディープラーニングの定義・仕組み・機械学習との違い・学習方法・実用例・歴史・課題まで、体系的にわかりやすく解説します。
研究開発の現場から:ディープラーニングを「使う側」の実務視点
この記事は、ディープラーニングを研究テーマとして扱うだけでなく、それを基盤にした製品を実際に開発・運用している立場から執筆しています。私たちクリスタルメソッドは、深層学習を用いたバーチャルヒューマン「DeepAI」や、表情・感情・緊張度をタイムラインで可視化する感情解析、音声合成「SakuraSpeech」などを自社開発し、面接練習や営業ロールプレイといった業務用途で運用しています。
実務でディープラーニングを扱うと、教科書的な理解だけでは足りない判断が数多く発生します。たとえば、本文で解説するスクラッチ学習と転移学習の選択は、実際には「どれだけ自社データを集められるか」「求める精度と開発期間のどちらを優先するか」で決まります。多くの業務課題は、公開されている事前学習済みモデルを土台にした転移学習で十分な精度に到達でき、ゼロからの学習が必要になる場面はむしろ限られる、というのが現場感覚です。
また本文の「課題」で触れるプライバシーやデータ持ち出しの制約は、実運用で最初にぶつかる壁です。私たちは機密性の高いデータを扱う場面では、外部に送信せず自社環境内で完結するローカルLLMを運用し、上場企業の実データを用いたRAG(検索拡張生成)で企業特化の応答を組み立てるなど、制約の中で成果を出す構成を選んでいます。こうした「使う側」の判断軸を意識しながら読み進めると、以降の各節がより実務に結びついて理解できるはずです。
ディープラーニング(深層学習)とは?
ディープラーニング(deep learning/深層学習)とは、「ニューラルネットワーク」と呼ばれる数理モデルを用いて行う機械学習の一種であり、コンピュータが大量のデータを分析して特徴や傾向を自動的に学習する技術です。
ニューラルネットワークは人間の脳内にある神経回路(ニューロンのネットワーク)を数理的にモデル化したものです。ディープラーニングではこのモデルを多層に積み重ねることで、非常に複雑なパターンや抽象的な概念まで学習できるようになっています。「層が深い(deep)」ことがそのまま名称の由来となっており、日本語で「深層学習」と呼ばれる所以もここにあります。
ネットワーク構造は大きく以下の3つの層から成り立っています。
- 入力層:画像・テキスト・数値データなどの生データを受け取る層
- 隠れ層:入力データから特徴を抽出・変換する層。ここが複数(多層)存在することがディープラーニングの特徴
- 出力層:最終的な判断結果(分類・予測値など)を出力する層
従来のニューラルネットワークでは隠れ層が2〜3層程度でしたが、現代のディープニューラルネットワークでは150層を超えるものも存在します。層の数が増えるほど、より抽象的・高次元な特徴を学習できるようになり、精度と表現力が飛躍的に向上します。
ディープラーニングはAI(人工知能)全般の技術向上に大きく貢献しており、私たちの日常生活における顔認証・音声アシスタント・画像検索・翻訳サービスなど、あらゆる場面ですでに活用されています。
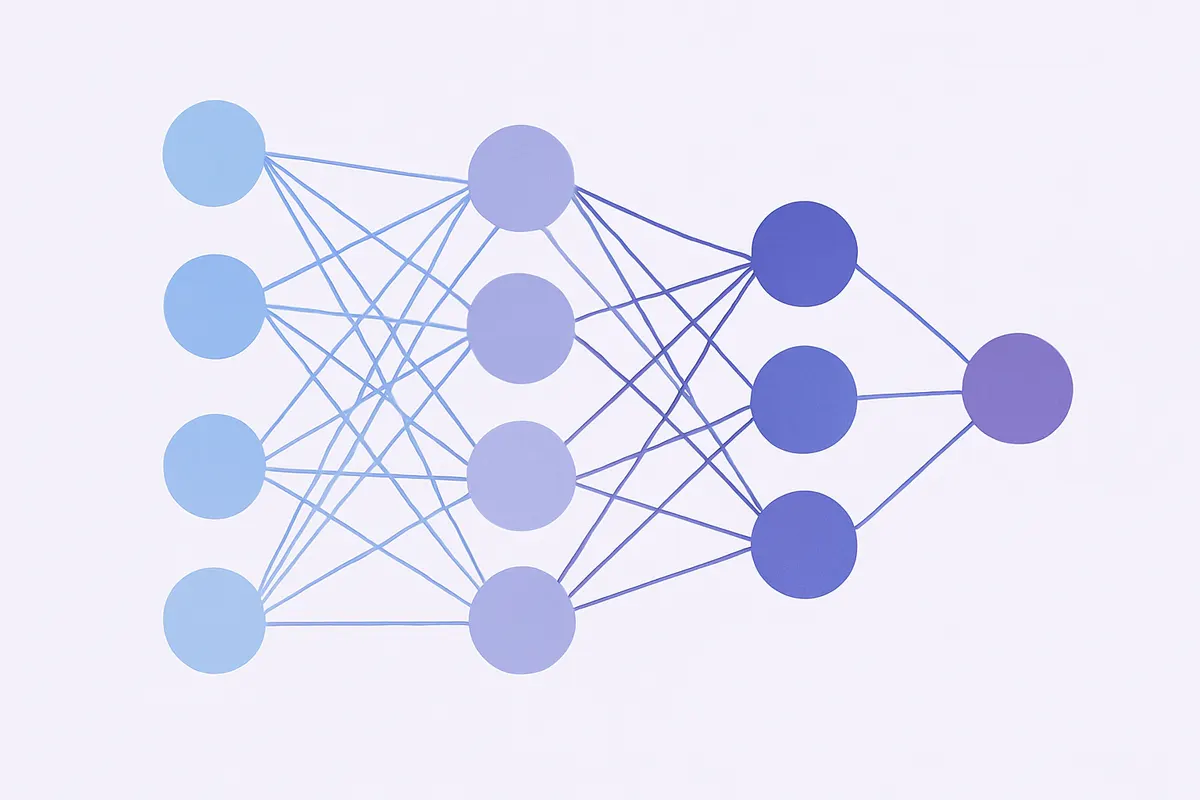
ディープラーニングと機械学習の違い
ディープラーニングと機械学習は混同されやすい概念ですが、両者の関係を正確に理解することで、それぞれの強みと適用場面が明確になります。
AI・機械学習・ディープラーニングの包含関係
まず、三者の関係を整理します。AI・機械学習・ディープラーニングは互いに独立したものではなく、入れ子(包含)の関係にあります。
AIが最も大きな概念であり、機械学習はAIを実現する手段のひとつ。ディープラーニングは機械学習の中でも「ニューラルネットワークを多層に積み重ねる」手法に特化したサブセットです。
つまり、ディープラーニングはすべて機械学習ですが、機械学習のすべてがディープラーニングではありません。機械学習にはディープラーニング以外にも、決定木・サポートベクターマシン・ランダムフォレストなど多様なアルゴリズムが存在します。ディープラーニングはその中でも「ニューラルネットワークを用いる」という制約(特化)を持つ手法です。
機械学習の詳しい仕組み
機械学習とは何かを、具体的なコード例から理解しましょう。以下は、Pythonで書かれた非常にシンプルな会話プログラムです。
kansha = ‘ありがとうございました。’
response = ‘どういたしまして’
if a == kansha:
print(response)
このプログラムは「ありがとうございました。」と入力すると「どういたしまして」と返します。しかし「サンキュー」「どうも!」「感謝します」などと入力しても応答しません。これはルールを人間が明示的に書いているだけであり、機械が「学習」しているわけではありません。
機械学習では、この問題を「トレーニング」によって解決します。大量の文章データを学習させることで、「感謝を示す言葉」が持つ共通の特徴をコンピュータ自身が発見し、法則として内部化していきます。「サンキュー」も「どうも!」も、学習済みモデルは感謝の表現として認識できるようになるのです。
学習データの量が多ければ多いほど法則は洗練され、判断精度が上がります。このように「トレーニングによって特定タスクの実行能力を自律的に獲得すること」が機械学習の本質です。
ディープラーニングの詳しい仕組み
ディープラーニングは機械学習の一形態であり、その特徴は「特徴の法則化をニューラルネットワークの重みの調整によって実現する」点にあります。
ニューラルネットワークの仕組みを図で確認しましょう。
重み
重み
重み
▲ ニューラルネットワークの基本構造。層と層をつなぐ矢印が「重み(weight)」。ディープラーニングでは隠れ層が多数積み重なる。
学習の流れは以下のとおりです。
- 入力層にデータを入力する:テキスト・画像・数値などが数値化されて入る
- 重みを介して隠れ層の値を計算する:各重みには計算式(関数)が設定されており、前の層の値に重みをかけて次の層の値を算出する
- 出力層の値を得る:最終的な判断値が算出される
- 誤差を計算し、重みを修正する:正解との差(誤差)を「誤差逆伝播法(バックプロパゲーション)」によってネットワーク全体に伝え、重みを少しずつ修正する
- これを大量のデータで繰り返す:トレーニングが完了すると、入力に対して高精度な出力ができるようになる
先ほどの感謝の例であれば、「感謝の言葉が入力されたとき出力層の z1 が0.5以上になる」ように重みが調整されます。学習後は z1 の値を確認するだけで感謝か否かを判断できるわけです。このように、ニューラルネットワークの重みの調整によって特徴の法則化を実現する機械学習こそが、ディープラーニングです。
ディープラーニングの学習方法
ディープラーニングには複数の学習手法が存在します。用途・データ量・目的に応じて使い分けることが重要です。ここでは特に代表的な2つを詳しく紹介します。
大量学習法(スクラッチ学習)
大量学習法は、ゼロからニューラルネットワークを構築・学習させる手法です。大量のデータとネットワーク設計が必須であり、学習完了までに数日から1ヶ月程度の時間を要することもあります。作業量も多く、コンピューティングリソースへの負荷も大きいため、頻繁に行われる手法ではありません。
一方で、出力する情報のカテゴリが非常に多い場合や、応用性の高い汎用モデルを構築したい場合には最も効率的な学習手法です。高い表現力を持つモデルを一から最適化できるため、特定の大規模タスクに対しては他の手法を凌駕する性能を発揮します。ImageNetなどの大規模画像認識コンテストで成果を上げた多くのモデルは、この大量学習によって構築されています。
転移学習(ファインチューニング)
転移学習とは、すでに大量データで学習済みのニューラルネットワーク(事前学習済みモデル)を流用し、新たなタスク向けに少量のデータで再調整(ファインチューニング)する手法です。
転移学習の最大のメリットは、必要なデータ量と学習時間を大幅に削減できる点です。ゼロから学習する場合は無数のカテゴリにわたるデータを揃える必要がありますが、学習済みモデルを利用すれば「りんごかみかんか」程度の二択分類もごく少量のデータで実現できます。データ量を大量学習法の1,000分の1程度に抑えられるケースもあり、中小規模の開発プロジェクトでも現実的に導入できます。
現在、画像認識分野ではVGG・ResNet・EfficientNet、自然言語処理分野ではBERT・GPT系モデルなど、多数の高精度な事前学習済みモデルが公開されており、転移学習のベースとして広く活用されています。
| 項目 | 大量学習法(スクラッチ) | 転移学習 |
|---|---|---|
| 必要データ量 | 非常に多い | 少量でも可 |
| 学習時間 | 数日〜1ヶ月以上 | 大幅に短縮可能 |
| 計算コスト | 高い | 比較的低い |
| カスタマイズ性 | 高い(完全自由設計) | ベースモデルに依存 |
| 主な用途 | 大規模・汎用モデル構築 | 特定タスクへの応用・少数データ環境 |
AIの業務導入をご検討の方は、AI開発会社クリスタルメソッドの無料相談をご利用ください。
ディープラーニングの実用例
ディープラーニングは理論にとどまらず、現実社会の多様な分野で実装・運用されています。ここでは代表的な実用例を紹介します。
自動運転
自動車の自動運転技術は、ディープラーニングの最も代表的な応用分野のひとつです。カメラ・LiDAR・レーダーなどのセンサーから得られる映像・距離データをリアルタイムで解析し、歩行者・車両・標識・白線などを認識して走行判断を下します。
ディープラーニングを活用することで、「人が運転する際に行っていた無数の状況判断」を機械が代替できるようになります。日本ではトヨタ・ホンダ・日産などの主要自動車メーカーが自動運転技術の開発を推進しており、高速道路での自動走行支援機能は市販車にも搭載されています。また、米国のWaymo・Teslaなどが先行して実証実験や商用化を進めており、2026年時点では自律走行レベル3以上の実装が各国で拡大しつつあります。
画像検査・品質管理
製造業における画像検査は、ディープラーニングの導入が急速に進んでいる分野です。特殊カメラで製品を撮影し、正常品の特徴と比較することで、傷・汚れ・形状の異常などの欠陥を自動的に発見します。
人間の目視検査では見落としが生じやすい微細な欠陥も、大量の良品・不良品データで学習したモデルは高精度に検出できます。食品製造ラインでの異物混入チェック・冷凍食品の形状検査・半導体ウエハの傷検出・自動車部品の表面検査など、あらゆる製造現場での活用が広がっています。
さらに、人物の顔特徴を学習することでセキュリティ分野への応用も進んでおり、顔認証システム・入退室管理・犯罪捜査支援などにも活用されています。
医療検査・診断支援
医療分野でのディープラーニング活用は、画像検査技術の応用として急速に普及しています。CTスキャン・MRI・内視鏡・病理スライドなどの医療画像をAIが解析し、がん・炎症・骨折などの病変を自動検出します。
熟練した医師の診断と同等以上の精度を発揮するモデルも登場しており、日本では胃がん・大腸がんの内視鏡AI診断支援システムが薬事承認を受け、実際の医療現場で運用されています。医師の作業負担を軽減しながら診断の見落としリスクを低減できる点が高く評価されており、感染症対策・病理診断・X線読影など幅広い医療応用が期待されています。
自然言語処理・生成AI
ChatGPTに代表される大規模言語モデル(LLM)も、ディープラーニングの延長線上にある技術です。Transformer(トランスフォーマー)と呼ばれるディープラーニングのアーキテクチャを基盤として、文章の要約・翻訳・対話・コード生成・質問応答などを高精度に実行します。2026年現在、GPT-4・Claude・Geminiなど多数の大規模言語モデルが実用化されており、ビジネス・教育・創作など社会のあらゆる領域に浸透しています。
その他の実用分野
上記以外にも、ディープラーニングは以下のような多様な分野で活用されています。
- レコメンデーション:NetflixやAmazonの「おすすめ」機能
- 音声認識:スマートスピーカー・音声入力システム
- 異常検知:工場設備の故障予兆検知・不正取引の検出
- IoT機器との連携:スマートホーム・スマートファクトリー
- 自動翻訳:DeepL・Google翻訳などのニューラル機械翻訳
- 画像生成:Stable Diffusion・DALL-Eなどの画像生成AI
ディープラーニングの高速化
深層学習の高速化とは、画像解析・データ出力・モデル学習などのスピードを向上させることで、作業全体の効率を高める取り組みです。学習に数日〜数週間かかることもあるディープラーニングにとって、高速化は実用化を左右する重要な課題です。
GPUの導入
GPU(グラフィックス・プロセッシング・ユニット)は、もともとゲームや映像処理のために開発された並列計算専用プロセッサですが、ディープラーニングの計算に極めて適した特性を持っています。
CPUは少数の高性能コアで複雑な逐次処理を行うのに対し、GPUは数千〜数万の小さなコアを持ち、単純な計算を大量に並列で実行することが得意です。ニューラルネットワークの学習では大規模な行列演算が繰り返し発生するため、GPUの並列処理能力が非常に有効に機能します。
NVIDIA(エヌビディア)のA100・H100などのデータセンター向けGPUは、ディープラーニングの学習時間をCPU単体と比較して数十〜数百倍短縮できるとされており、世界中のAI研究・開発の現場で標準的に使われています。皆さんがパソコンで見ている文字・画像・動画の表示もすべてGPUが担っており、まさにデジタル社会の基盤ともいえるハードウェアです。
モデルの圧縮
深層学習モデルは、層数やパラメータ数が増えるほど精度が高まりますが、同時にデータ量も膨大になります。モデル圧縮とは、このモデルを軽量化することで処理速度を向上させる技術です。
代表的な圧縮手法には、重要度の低いニューロン間の結合を削除する「プルーニング(枝刈り)」、パラメータのビット精度を下げる「量子化」、大きなモデルの知識を小さなモデルに移す「知識蒸留(ナレッジディスティレーション)」などがあります。北海道から東京へ「泳いでいくのか飛行機で行くのか」というほどの差に例えられるように、モデルの軽量化は学習・推論の速度に根本的な影響を与えます。スマートフォンや組み込み機器などリソースが限られた環境でのディープラーニング実行においても、モデル圧縮は不可欠な技術です。
クラウドの調整と分散学習
複数のサーバーやGPUを連携させて深層学習を実行する「分散学習」も、高速化の有力な手段です。一台のマシンでは数週間かかる学習も、多数のGPUをクラウド上で並列稼働させることで大幅に短縮できます。
AWS・Google Cloud・Microsoft Azureなどの主要クラウドプロバイダーは、GPU搭載インスタンスや深層学習専用の機械学習プラットフォームを提供しており、オンデマンドで大規模な計算リソースを利用することが可能です。クラウドに搭載されるGPUの世代・数・ネットワーク帯域によっても計算速度は大きく変わるため、用途に応じた最適な構成の選択が重要です。複数端末を一つのクラウドに接続して作業を分担することで、さらなる時間短縮も実現できます。
MATLAB(マットラブ)の活用
MATLABとは、米国のMathWorks社が開発した数値計算プラットフォームであり、世界で数百万人のエンジニア・研究者が利用しています。アルゴリズム開発・データの可視化・グラフィカルインターフェース構築・多言語インターフェース共有など多彩な機能を備えており、産業界・官公庁・教育機関で広く採用されています。
MATLABにはディープラーニング専用のツールボックスが用意されており、転移学習を用いたモデル構築や学習プロセスの可視化を比較的簡便に行うことができます。特に、エンジニアリングバックグラウンドを持つ開発者がプログラミング言語の詳細に立ち入らずにディープラーニングを試みる際の入門ツールとして有効です。これを活用することで、転移学習を利用したディープラーニングをさらに短時間で実装することができます。
ディープラーニングが注目されている理由
ディープラーニングの理論は1980年代にはほぼ確立されていましたが、当時は「理論だけ存在して実用化できない技術」でした。では、なぜ2010年代以降に急激に注目を集めたのでしょうか。その主な理由は2つあります。
サーバー・ハードウェアの処理能力の向上
ディープラーニングでは、人工知能が大量のデータを繰り返し比較しながら重みを調整する作業を何百万〜何億回も行います。理論が提唱された当時のコンピュータ性能では、このような大規模計算をこなすことは現実的ではありませんでした。
その後、半導体の微細化が進みCPU・GPU性能が指数関数的に向上し、大量の行列演算を現実的な時間でこなせる環境が整いました。特にGPUの計算能力向上が決定的な役割を果たし、2012年にAlexNetがImageNet画像認識コンテストで圧倒的な精度を記録したことでディープラーニングは一気に世界の注目を集めました。
学習用データの大量収集が可能になった
ディープラーニングは大量のデータで学習するほど精度が上がります。インターネットの普及・SNSの爆発的成長・IoTデバイスの普及により、現代では画像・テキスト・音声・センサーデータなど、膨大な学習用データが入手しやすい環境が整っています。
1980〜90年代にはこのようなデータを大規模に収集・活用する基盤がなく、理論と実用化の間には大きなギャップがありました。現代ではWikipedia・Common Crawl(ウェブ全体のテキスト)・ImageNetなどの大規模公開データセットが整備されており、研究・開発のベースとして広く利用されています。
これら2つの要因が揃ったことで、ディープラーニングは理論から実用技術へと劇的に変貌を遂げました。
ディープラーニングの歴史
ディープラーニングは近年突然登場した技術ではなく、数十年にわたる研究の積み重ねの上に成り立っています。その歴史をたどることで、技術の本質と今後の展望をより深く理解できます。
| 時期 | 出来事・技術 |
|---|---|
| 1957年 | 第一次AIブーム。Frank Rosenblattが人間の視覚を模した「パーセプトロン」を発表。ディープラーニングの最初の原型 |
| 1986年 | 第二次AIブーム。パーセプトロンを多層化した「マルチレイヤーパーセプトロン」と誤差逆伝播法(バックプロパゲーション)が普及 |
| 2006年 | 第三次AIブーム。Geoffrey Hintonらが深いニューラルネットワークの効果的な学習手法を発表し「ディープラーニング」という用語が定着 |
| 2012年 | AlexNetがImageNet競技でそれまでの最高精度を大幅に上回る成績を記録。ディープラーニングが世界的に注目される転換点 |
| 2017年 | Googleが「Transformer」アーキテクチャを論文で発表。自然言語処理における深層学習の性能が飛躍的に向上 |
| 2020年以降 | GPT-3・ChatGPT・Stable Diffusionなど大規模言語モデル・画像生成AIが一般公開され、社会実装が急加速 |
1957年のパーセプトロンが現在のディープラーニングの直接の祖先であり、AIブームのたびに技術的なブレークスルーが生まれてきた歴史があります。
また、ディープニューラルネットワークには畳み込みニューラルネットワーク(CNN:Convolutional Neural Network)と呼ばれる構造が画像処理に多く使われています。CNNは入力された画像データを「畳み込み層」に送り、特徴マップ(2次元データ)に変換することで、物体のエッジ・テクスチャ・形状といった特徴を段階的に抽出します。これにより、物体認識・顔認識・医療画像解析などが高精度に実現できます。CNNは入力の空間的な位置関係を保ったまま処理できるため、画像という「縦×横の2次元データ」の扱いに特に優れています。
従来のニューラルネットワークでは隠れ層が2〜3層でしたが、現代のディープニューラルネットワークには150以上の隠れ層が存在するものもあり、層数の増加とともに学習できる概念の抽象度・複雑度が飛躍的に高まっています。
さらに、ディープラーニングが用いられる分野は拡大し続けており、従来の自動運転・画像認識にとどまらず、IoT機器・異常検知・自動翻訳・レコメンデーション・音声合成・コンテンツ生成など、現代のビジネスと生活のあらゆる場面に浸透しています。
ディープラーニングの課題
高い性能と広い応用範囲を持つディープラーニングですが、解決すべき課題もいくつか存在します。
ブラックボックス問題(説明可能性の欠如)
ディープラーニングの最も根本的な課題のひとつが、「なぜその答えを出したのか」を人間が説明できないという「ブラックボックス問題」です。
従来のルールベースシステムでは、人間がコンピュータに判断ルールを明示的に与えていたため、どのロジックで判断したかが明確でした。しかしディープラーニングでは、コンピュータが膨大なパラメータ(重み)の組み合わせによって自律的にルールを発見します。この「発見されたルール」は数億〜数千億個のパラメータが複雑に絡み合ったものであり、現在の技術では人間が読み解くことはほぼ不可能です。
この問題は医療診断・金融審査・法的判断など、「なぜその結論に至ったか」の説明責任が求められる分野での導入を難しくしています。現在はXAI(説明可能AI)と呼ばれる研究分野が発展しており、ニューロンの動きをまとめる「アクティベーションマッピング」や、入力の重要度を可視化する「SHAP(SHapley Additive exPlanations)」などの手法が開発されています。
大量のデータと計算資源が必要
ディープラーニングは一般的に、高精度なモデルを構築するために大量の学習データと強力な計算環境を必要とします。医療・製造・法律など、データ収集が困難な分野やプライバシー上の制約がある分野では、十分なデータを確保することが大きな障壁となります。また、大規模モデルの学習・運用には多大な電力を消費することから、環境負荷(CO₂排出)への懸念も高まっています。
過学習(オーバーフィッティング)のリスク
学習データに過度に最適化されてしまい、未知のデータに対して精度が低下する「過学習」もディープラーニングにおける典型的な課題です。大規模なモデルほど過学習のリスクが高まるため、ドロップアウト・正則化・データ拡張など多様な対策技術が研究・実装されています。
敵対的事例への脆弱性
ディープラーニングモデルは、人間の目には違いがわからないほどの微小なノイズを画像に加えるだけで誤判断を起こしてしまう「敵対的事例(Adversarial Examples)」への脆弱性が知られています。特に自動運転・セキュリティシステムなど安全性が重要な領域では、こうした攻撃への耐性(ロバスト性)の向上が重要な研究テーマとなっています。

まとめ
ディープラーニング(深層学習)は、ニューラルネットワークを多層に積み重ねることで、大量のデータから特徴を自律的に学習する機械学習の手法です。AIという大きな概念の中に機械学習があり、その機械学習の中にディープラーニングが位置しています。
ディープラーニングが現在ほど注目される背景には、GPUをはじめとするハードウェア性能の飛躍的な向上と、インターネットの普及によって大量の学習用データが収集しやすくなったという2つの大きな要因があります。理論自体は1957年のパーセプトロンにまでさかのぼりますが、技術的土台が整った2010年代以降に実用化が一気に加速しました。
実用面では、自動運転・画像検査・医療診断支援・自然言語処理・生成AIなど、現代社会のあらゆる場面にディープラーニングは深く組み込まれています。学習の高速化手法としては、GPU導入・モデル圧縮・クラウド分散学習・MATLABの活用などが有効であり、用途に応じた使い分けが重要です。
一方で、ブラックボックス問題・大量データ・計算資源への依存・過学習リスク・敵対的事例への脆弱性といった課題も残されており、世界中の研究者・企業が解決に取り組んでいます。日産・トヨタをはじめ日本の大企業、そして世界のテクノロジー企業がディープラーニングに注目し投資を続けており、今後もその応用範囲と市場規模は拡大し続けることが予測されます。ディープラーニングの基本を理解しておくことは、AIが当たり前になった社会を生き抜くうえで、ますます重要な知識となっています。
監修
河合 継(クリスタルメソッド株式会社 代表取締役)
AI・ディープラーニングに関する特許16件の発明者。過去、国立がん研究センターとの共同研究や、テレビ番組でのAI解説実績を持つAI研究者として、AIの研究開発を主導している。
運営会社について | 編集方針
よくある質問
Q. ディープラーニングと機械学習は何が違いますか?
A. 本文「ディープラーニングと機械学習の違い」で整理しています。
Q. ディープラーニングはどうやって学習しますか?
A. 本文「ディープラーニングの学習方法」で解説しています。
Q. どんな場面で使われていますか?
A. 本文「ディープラーニングの実用例」で紹介しています。
Q. ディープラーニングの課題は何ですか?
A. 本文「ディープラーニングの課題」で整理しています。
AIの業務活用をご検討の方へ
クリスタルメソッドは、バーチャルヒューマンをはじめAIの開発・業務導入を支援しています。生成AI・AIエージェントの活用や、自社業務へのAI導入をご検討の際は、お気軽にご相談ください。
- 無料相談・お問い合わせ:ご相談はこちら
Study about AI
AIについて学ぶ
-

AI 開発コスト 削減 比較:中国Kimi K3の衝撃と日本企業が取るべきコスト最適化戦略
中国発「Kimi K3」の衝撃とグローバルAI市場の地殻変動 中国のAIスタートアップであるMoonshot AIが、2.8兆パラメータを持つオープンウェイトの...
-

【AI API 誤請求 対策】Claudeの25億円バグに学ぶ、企業が今すぐ導入すべきコスト防衛策
生成AIのビジネス活用が急速に進む中、企業の意思決定者が最も懸念すべきリスクの一つが「API利用に伴う予期せぬ高額請求」である。2026年7月、大手AIスタート...
-

OpenAIのIPO延期影響とは?日本企業が取るべき投資判断とリスク分散戦略
OpenAIのIPO延期報道の要点と背景 生成AI市場を牽引するOpenAIの動向は、世界のテック市場だけでなく、日本国内の企業のシステム投資計画にも極めて大き...