blog
AIブログ
音声読み上げの完全ガイド|仕組み・選び方・活用法【2026】
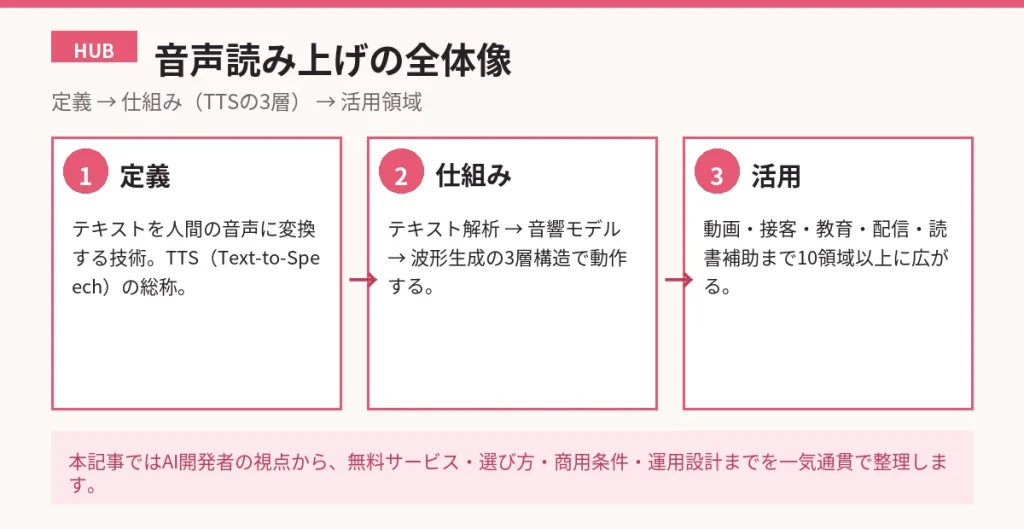
音声読み上げとは、テキストデータを人間の音声に変換して再生する技術の総称で、現在の主流は深層学習を用いたAI音声合成(Neural TTS)です。テキスト解析・音響モデル・波形生成の3層を通して合成された音声は、2026年時点でアナウンサーと聞き分けが難しいレベルにまで到達し、動画制作・社内ナレッジ・接客アバター・学習支援まで幅広い領域で実用化が進んでいます。
本記事では、AI音声合成エンジンSakuraSpeechを開発・提供する立場から、音声読み上げの仕組み・主要技術・選び方・活用シーン・商用利用の注意点・導入手順・KPI設計までを一気通貫で整理します。「無料でとりあえず試したい」「業務に組み込みたい」「AI型と従来型の違いを理解したい」のいずれの目的にも応えられるよう、技術解説と実務観点を両立させて構成しました。
音声読み上げは、字面だけ追えば「テキストを音にするだけ」の単純な技術に見えます。しかし実際には、アクセント推定・ポーズ生成・感情パラメータ・話者ID・ボイスクローンといった要素技術の組み合わせで品質が決まります。読了後には、目的に応じた最短ルートでサービスを選べる状態を目指します。
音声合成・読み上げの選び方と業務での活用シーンの全体像は、音声合成とは(活用ガイド)にまとめています。
音声読み上げとは|定義と歴史的背景
音声読み上げとは、テキストデータを音声信号に変換し、スピーカーやイヤホンから音として出力する技術の総称で、英語ではTTS(Text-to-Speech)と呼ばれます。1960年代の規則合成から始まり、波形接続型、HMM型を経て、2016年以降は深層学習ベースのNeural TTSが主流となりました。
音声読み上げ技術の発展は、おおまかに4世代に整理できます。第1世代はフォルマント合成と呼ばれる規則ベースの方式で、機械的な音色が特徴でした。第2世代は録音した音素を切り貼りする波形接続型で、自然さは向上したものの、データベース容量が肥大化しやすい問題を抱えていました。
第3世代の隠れマルコフモデル(HMM)方式で統計的合成が可能になり、第4世代の深層学習方式(Tacotron系・FastSpeech系・VITS系など)で人間に近い自然さが実現しました。2026年現在は、この第4世代の中でも拡散モデル系・大規模言語モデル系の新しい潮流が登場し、ボイスクローンや感情表現の精度が急速に高まっています。
歴史的経緯を押さえると、現代のサービス比較も理解しやすくなります。たとえば「機械的に聞こえる」のは旧世代の方式、「自然だが読み間違いが多い」のは深層学習の確率的振る舞い、といった具合に、現象の背後にある技術原理が見えるからです。
音声読み上げの仕組み|TTSの3層構造
音声読み上げの仕組みは「テキスト解析 → 音響モデル → 音声波形生成」という3層構造で動いており、各層が独立した課題を持っています。テキストを直接音声に変換するのではなく、3段階のパイプラインで段階的に変換することで、自然な発話と高い柔軟性を両立しています。
第1層はテキスト解析(フロントエンド)です。入力されたテキストを形態素解析し、漢字の読みを決定し、アクセント・ポーズ・イントネーションのラベルを付与します。日本語の場合は同形異音語(「行った」が「いった」か「おこなった」か)や数字・記号の読み分けが課題となり、辞書とルールの組み合わせで処理されます。
第2層は音響モデルです。テキスト解析結果(音素列とラベル)を入力として、メルスペクトログラムと呼ばれる音響特徴量を生成します。Tacotron系・FastSpeech系・VITS系などのモデルがここに該当し、話者性・感情・話速・ピッチをコントロールする役割を担います。
第3層は音声波形生成(ボコーダ)です。メルスペクトログラムを実際の音声波形に変換する処理で、WaveNet・HiFi-GAN・BigVGANといったニューラルボコーダが標準的に使われます。第2層と第3層を統合したエンドツーエンドモデル(VITSなど)も増えており、近年は2層構造に簡略化される傾向もあります。
業務利用の観点では、各層の責務を理解しておくことで「読み間違いが多いならフロントエンド設定」「音質がこもるならボコーダ選択」と切り分けて改善できるようになります。
主要技術の変遷|波形接続から生成AIまで
音声読み上げ技術は、波形接続型 → 統計パラメトリック型(HMM)→ 深層学習型 → 生成AI型へと進化してきました。2026年時点の主流は深層学習型と生成AI型で、ボイスクローンや感情合成といった付加機能はこの世代でのみ実現できます。
波形接続型(コンカテネーティブ合成)は、収録音声を音素・音節単位で分割し、入力テキストに合わせてつなぎ合わせる方式です。音声そのものは収録音源ベースなので自然ですが、つなぎ目の不自然さや、収録外の表現が苦手という制約がありました。
統計パラメトリック型(HMM-TTS)は、音響特徴量の統計モデルから音声を生成する方式で、データ量が小さく柔軟性が高い反面、ボコーダ起因のこもった音色が課題でした。深層学習型(Neural TTS)は、Tacotron 2の登場以降、人間の発話と区別が困難なレベルまで自然さが向上した世代です。
生成AI型と呼ばれる最新世代は、大規模音声データで事前学習されたモデルをベースに、数秒〜数十秒の参照音声から話者性を再現するゼロショットボイスクローンや、感情・スタイルを言語で指示できる制御性を持ちます。SakuraSpeechもこの世代の流れを汲み、日本語特化の音響モデル設計で実装されています。spoke記事「AI読み上げ無料ツール7選|自然な声の選び方と活用術」も合わせて確認してください。
音声読み上げサービスの4タイプ
音声読み上げサービスは「OS標準型」「ブラウザ型」「専用ソフト型」「クラウドAPI型」の4タイプに大別できます。用途・予算・自然さの要求水準によって最適解が変わるため、まず自分のニーズがどのタイプに該当するかを把握することが選定の第一歩です。
| タイプ | 代表例 | 強み | 弱み |
|---|---|---|---|
| OS標準型 | Windowsナレーター/macOS VoiceOver/iOS スピーチ/Android TalkBack | 追加導入不要・無料 | 声の選択肢が少ない・機械的 |
| ブラウザ型 | 音読さん・ondoku.com系・Read Aloud拡張 | インストール不要・即利用 | 長文制限・商用利用に制約 |
| 専用ソフト型 | VOICEVOX・CeVIO AI・AITalk | 高品質・キャラ豊富 | 端末リソース消費・操作習熟必要 |
| クラウドAPI型 | SakuraSpeech・Amazon Polly・Google Cloud TTS | 商用前提・スケーラブル・最新モデル | 従量課金・ネット接続必須 |
個人で短文を試したいだけならOS標準型やブラウザ型で十分ですが、業務システムに組み込みたい・大量のナレーション制作を継続的に回したい・自社プロダクトに組み込みたいといった用途では、クラウドAPI型が現実的な選択肢となります。詳細は spoke記事「音声読み上げ無料サービス8選|選び方と注意点」で比較しています。
選び方|失敗しない8つの評価軸
音声読み上げサービスを選ぶときは、自然さ・対応言語・話者数・速度/ピッチ/感情制御・商用利用可否・API有無・料金体系・サポートの8軸で評価するのが定石です。1つの軸で突出していても、別の軸が弱ければ業務で使い物にならないケースが多いため、複数軸で重み付けして比較するのが安全です。
1つ目は自然さ。デモ音声を実際の業務で読ませたい文章で試聴することが最優先です。短いキャッチコピーは自然でも、長文ナレーションになると破綻するサービスも珍しくありません。
2つ目は対応言語。日本語特化型・多言語対応型でアクセント精度が大きく異なります。日本語メインなら国産サービス、グローバル配信なら多言語型を選ぶのが原則です。
3つ目は話者数とキャラの選択肢。動画用途では声のバリエーションが視聴維持率に直結し、業務用途ではブランドに合う声質を選べるかが鍵になります。
4つ目はパラメータ制御。速度・ピッチ・感情・話法(読み上げ/会話/ナレーション)の制御性は、コンテンツ品質を大きく左右します。
5つ目は商用利用可否。無料サービスの多くは商用利用に制約があり、見落とすと炎上リスクが発生します。詳細は本記事「商用利用と著作権」のセクションで掘り下げます。
6つ目はAPI有無。業務システムやアプリへの組み込みを想定するなら、安定したAPIが提供されていることが必須要件になります。
7つ目は料金体系。文字単価・月額・買い切り・無料枠の有無を、自社の月間文字数と照らして比較します。
8つ目はサポート体制。法人利用ではSLA・問い合わせ対応・利用規約の透明性が重要です。トラブル時にメールも返信されないサービスは、業務利用では選んではいけません。
商用利用と著作権|避けて通れない確認事項
音声読み上げの商用利用では「サービス利用規約」と「合成音声の二次利用」の両方を確認する必要があります。無料で使える=商用で使える、ではありません。読み上げ結果をYouTube・広告・ゲーム・配信などに使う場合は、サービスごとに条件が大きく異なります。
具体的に確認するべき項目は5つあります。第1に、サービス自体の商用利用可否。第2に、生成された音声ファイルの再配布・販売の可否。第3に、クレジット表記の要否。第4に、特定用途(広告・公序良俗に反するもの・他者の名誉を毀損する内容)への禁止事項。第5に、AI学習データへの使用に関する条項です。
特にキャラクターボイスを提供するサービスでは、声優の権利関係が利用規約に細かく定められています。「個人利用は無料/商用利用は別ライセンス/法人利用はさらに別契約」と階層化されているケースが一般的です。読み始める前に必ず規約全文に目を通してください。
SakuraSpeechのように日本語特化で開発される国産サービスは、商用利用条件が日本語の法務文書として明示されており、企業導入時の社内稟議が通りやすい設計です。グローバルサービスの英語規約を翻訳して読み解くより、明確な日本語規約のサービスを選んだほうが運用負荷は下がります。
活用シーン10領域|現場で広がる使い方
音声読み上げは、動画制作・社内研修・接客・学習支援・読書補助・配信・ゲーム・電話自動応答・防災・福祉の10領域で実用化が進んでいます。2020年代前半の「コスト削減ツール」という位置づけから、「ユーザー体験を高めるUI要素」へと役割が広がっているのが2026年の特徴です。
1つ目は動画ナレーション。YouTube・解説動画・社内研修動画で、人がナレーションを録音する工程をAIに置き換えるユースケースです。撮り直しゼロ・スクリプト修正のたびに即時更新できる効率性が支持されています。
2つ目は社内ナレッジ/マニュアル。ドキュメントを音声化して通勤中や作業中に聞ける形にする活用です。読む時間が取れない管理職層に特に刺さるユースケースです。
3つ目は接客アバター。デジタルサイネージや受付システムにAIアバターと音声合成を組み合わせて、定型応対を自動化する事例が増えています。
4つ目は読み上げ補助/アクセシビリティ。視覚障害・ディスレクシア・高齢者など、視覚的にテキストを読むことが難しいユーザーへの情報保障です。
5つ目は語学学習。発音モデルとして英語・日本語の読み上げを利用するユースケースで、ネイティブ音声に近い品質が学習効果を高めます。
6つ目はライブ配信/VTuber。リアルタイムにコメントを読み上げたり、AI VTuberの声として活用する用途です。
7つ目はゲーム。NPCのセリフを大量に用意する必要があるゲーム制作では、声優収録の代替・補完として導入が進んでいます。
8つ目は電話自動応答(IVR)。コールセンターでの自動音声応答に、より自然な音声を導入するケースです。
9つ目は防災・公共放送。災害時の自動音声案内や、駅・公共施設のアナウンスでの活用です。
10個目は福祉・医療。発話が困難な患者の代替音声、診療現場での自動音声記録など、新しい用途が広がっています。
業務組み込み手順|5ステップ導入モデル
音声読み上げを業務に組み込むときは、要件定義 → 候補選定 → PoC → 本番設計 → 運用整備の5ステップで進めるのが標準です。「とりあえず無料サービスを試して」で始めると、商用利用や品質要件でつまずくケースが多いため、最初に要件を整理する手間を惜しまないことが成功の鍵になります。
第1ステップは要件定義。読み上げ対象(文章ジャンル・長さ)、出力先(動画・電話・アプリ)、品質要求(許容できる読み間違い率)、商用利用範囲、月間文字数、予算上限を明確にします。
第2ステップは候補選定。要件に合うサービスを3〜5社ピックアップし、利用規約・料金体系・APIドキュメントを精査します。この段階で半分以上は要件で落ちるのが普通です。
第3ステップはPoC(概念実証)。実際の業務テキストを各候補で読ませ、読み間違い率・自然さ・処理速度を実測します。短文ではなく、本番想定の長さ・難度で評価することが重要です。
第4ステップは本番設計。選定したサービスを業務システムに組み込む設計です。APIの呼び出し方、辞書登録運用、エラー時のフォールバック、音声ファイルの保存・配信方法を決めます。
第5ステップは運用整備。読み間違いの修正サイクル、新製品名・固有名詞の追加運用、月次の品質レビュー、コストモニタリングを定常化します。
無料と有料の違い|境界を見極める
無料サービスと有料サービスの違いは「商用利用」「文字数制限」「品質」「API安定性」「サポート」の5領域に集約されます。「無料で十分」というケースと「絶対に有料が必要」というケースを正しく見極めることで、無駄な出費と無駄な障害を両方避けられます。
無料サービスで十分なケースは、個人利用、社内資料の読み上げ確認、短い検証用音声の生成、学習用途、非商用のクリエイティブ活動などです。OS標準・ブラウザ型・無料枠付きクラウドAPIで網羅できる範囲です。
有料が必須になるケースは、商用販売、広告音声、長時間ナレーションの量産、高品質な感情表現、APIによる業務システム組み込み、SLAが必要な法人利用、ブランドボイスのカスタム制作などです。
境界をまたぐ典型例は、「YouTubeで広告収益化したい動画にナレーションをつける」というケースです。商用利用扱いになることが多いため、無料サービスをそのまま使うと規約違反のリスクが残ります。詳細は spoke記事「音声読み上げ無料サービス8選|選び方と注意点」で各サービスの商用条件を比較していますので、選定前に必ず確認してください。
AI音声合成の進化|ボイスクローンと感情表現
2024年以降のAI音声合成は、ボイスクローンと感情表現の2分野で大きな進化を遂げています。数秒の参照音声から話者性を再現するゼロショットボイスクローン、テキストで感情やスタイルを指示できる制御性は、業務利用の幅を一気に広げました。
ボイスクローンは、本人の声を数十秒〜数分の音声サンプルから学習・再現する技術です。ナレーターや声優の負荷を下げる用途、亡くなった方の声を残す用途、教育コンテンツでの講師音声複製など、応用範囲が広がっています。一方で、なりすまし・詐欺・無断使用のリスクも高まっており、提供側は本人同意・利用範囲制限・透かしなどの安全策を講じる責任があります。
感情表現の制御は、「明るく」「悲しく」「興奮して」といった指示を、テキストプロンプトで与えるだけで反映できる段階まで来ています。ナレーション分野では特定の感情を一貫して出すコントロールが、ゲームやエンタメ分野では場面ごとに細かく揺らすコントロールが求められ、用途によって必要な制御粒度が異なります。
SakuraSpeechは、こうした最新の音響モデル設計を日本語に最適化して実装しています。ピッチ・速度・感情パラメータの調整・ボイスクローン機能を備え、リアルタイムに近い速度で自然な日本語音声を生成できることが特徴です。詳しい技術解説は spoke記事「AI読み上げ無料ツール7選|自然な声の選び方と活用術」と合わせて確認してください。
音声合成の業務導入や自社サービスへの組み込みをご検討の方は、日本語特化AI音声合成「SakuraSpeech」を開発するクリスタルメソッドの無料相談をご利用ください。
日本語音声読み上げの特殊性
日本語の音声読み上げは、アクセント・促音・長音・同形異音語という4つの特殊性に対応する必要があり、英語向けに設計されたモデルではうまく合成できないことがよくあります。このため、日本語業務での実用化には日本語特化型のモデル設計が有利です。
第1の特殊性はアクセントです。日本語は高低アクセントを持ち、同じ音節列でも単語によってアクセント位置が異なります。たとえば「橋(はし/低高)」と「箸(はし/高低)」のように、アクセント1つで意味が変わるため、辞書とアクセントモデルの精度が品質を決めます。
第2の特殊性は促音「っ」・長音「ー」・撥音「ん」の扱いです。これらは音素ではなくモーラ(拍)として日本語のリズムを支える要素で、英語ベースのモデルでは適切な長さで表現することが難しいケースがあります。
第3の特殊性は同形異音語です。「行った(いった/おこなった)」「日本(にほん/にっぽん)」「角(かど/つの)」など、文脈で読み分ける必要があり、形態素解析と文脈推定の精度が読み間違い率を左右します。
第4の特殊性は数字・記号・英単語の混在です。「2026年」を「にせんにじゅうろくねん」と読むのか「にーまるにーろくねん」と読むのか、文脈と用途で判断が分かれます。専門用語の英単語をカタカナ読みするか英語発音するかも、サービスによって挙動が異なります。
これら4つの特殊性に対応する設計が、日本語音声読み上げの品質を決定づけます。日本語業務をメインに据えるなら、日本語特化型として開発されたサービスを優先するのが定石です。
よくある失敗パターンと回避策
音声読み上げ導入で失敗するパターンは「商用条件の見落とし」「品質要件の曖昧さ」「辞書運用の不在」「コスト試算の甘さ」「人の置き換え発想」の5つに集約されます。事前に知っておけば回避できるものばかりなので、要件定義段階でチェックリスト化することをおすすめします。
1つ目の「商用条件の見落とし」は、YouTube収益化・広告・営利配信などを商用利用と気づかずに無料サービスを使い、後から規約違反を指摘されるパターンです。回避策は、最初の30分で利用規約全文を読むことです。
2つ目の「品質要件の曖昧さ」は、PoCでデモ音声だけ確認し、本番想定の長文・難語混在テキストでテストしないまま導入してしまうパターンです。回避策は、PoCで本番に近いテキストを300〜500文字単位で実測することです。
3つ目の「辞書運用の不在」は、自社の固有名詞や業界用語の読みを登録しないまま運用を始め、聞き手が違和感を覚えるパターンです。回避策は、辞書登録の責任者と更新頻度を最初に決めておくことです。
4つ目の「コスト試算の甘さ」は、無料枠で試算し、本番運用で予想を超える費用が発生するパターンです。回避策は、月間文字数の根拠を業務側に確認し、上振れ想定で見積もることです。
5つ目の「人の置き換え発想」は、ナレーター・声優をすべて代替しようとして、ブランドや表現の機微が失われるパターンです。回避策は、量産工程はAIに任せ、ブランド表現の核となる部分は人が担うという役割分担の設計です。
導入後のKPIと品質改善サイクル
音声読み上げを業務利用するなら、読み間違い率・処理時間・コスト・聞き手満足度の4指標をKPIとして月次でモニタリングするのが推奨です。導入して終わりではなく、辞書整備とパラメータ調整を継続することで、サービスの真価が発揮されます。
第1指標は読み間違い率です。サンプル100文を月次でチェックし、誤読箇所を辞書登録する運用を回します。読み間違い率を1%以下に抑えるのが業務利用の現実的なラインです。
第2指標は処理時間です。リアルタイム性が求められる用途では、テキスト入力から音声出力までのレイテンシを測定します。バッチ用途では大量処理のスループットを測ります。
第3指標はコストです。月間文字数・APIコール数・生成ファイル容量を集計し、想定予算に対する乖離を見ます。文字単価が変動する従量課金型では、月初に予算アラートを仕込むのが鉄則です。
第4指標は聞き手満足度です。社内利用なら従業員アンケート、顧客向けなら顧客満足度調査やNPSで定性評価を集めます。数字に出にくい「違和感」を拾うために、開かれた質問項目を1つ入れておくのがコツです。
2026年以降の展望と最前線
2026年以降の音声読み上げは、リアルタイムボイスクローン・多話者制御・対話エンジン統合・モバイル端末オンデバイス推論の4方向で進化が予測されます。クラウドAPIだけでなく、エッジデバイス上で動作する軽量モデルが普及することで、活用の地平がさらに広がります。
1つ目のリアルタイムボイスクローンは、配信や通訳で実用化が始まっています。話者本人の声で多言語をリアルタイム配信する用途は、グローバル展開する企業の標準装備になりつつあります。
2つ目の多話者制御は、対話シーンを1つのAPIで複数キャラクター切り替えながら生成する技術です。オーディオブック・ポッドキャスト・ゲームでの応用が広がっています。
3つ目の対話エンジン統合は、LLM・感情認識・音声合成を1つのパイプラインに統合する流れです。AIアバター・AI受付・AIインタビューといった対話AI製品の品質を底上げします。クリスタルメソッドのAI社員・AI上司のような事例もこの流れの一部です。
4つ目のオンデバイス推論は、スマートフォンや組込み機器上で動作する軽量モデルの普及です。プライバシー保護・オフライン動作・低遅延が必要な医療・防災・自動車分野で需要が高まっています。
まとめ|目的別の選び方ロードマップ
音声読み上げの選び方は、目的を「個人試用」「クリエイター利用」「業務組み込み」「商用プロダクト」の4類型に分け、それぞれに合うタイプを選ぶのが最短ルートです。本記事を1枚にまとめた選定ロードマップを提示します。
| 目的 | 推奨タイプ | 選定ポイント | 参考spoke記事 |
|---|---|---|---|
| 個人試用 | OS標準型 / ブラウザ型 | すぐ試せること | 音声読み上げ無料サービス8選 |
| スマホでさっと使う | 読み上げアプリ | iOS/Androidの違い | 読み上げアプリ無料7選 |
| 動画制作・配信 | 専用ソフト型 / クラウドAPI型 | 声質バリエーション・キャラ | かわいい声の読み上げサイト6選 |
| 学習・発音モデル | 多言語対応のクラウドAPI | ネイティブ発音・速度調整 | 英語読み上げ無料サイト6選 |
| 業務組み込み・商用 | クラウドAPI型(AI型) | 商用条件・SLA・日本語特化 | AI読み上げ無料ツール7選 |
業務組み込みや商用利用を視野に入れるなら、日本語特化で商用条件が明確な国産AI音声合成エンジン SakuraSpeech を一度試してみてください。16種類以上のキャラクターボイス、ピッチ・速度・感情の調整、ユーザー辞書、ボイスクローン、API連携まで、業務利用に必要な要素が揃っています。
よくある質問(FAQ)
Q1. 音声読み上げと音声合成、AI音声、TTSは何が違いますか?
呼び方の違いで、技術的には同じ領域を指します。TTS(Text-to-Speech)が学術・技術側の正式名称、音声合成は日本語の総称、音声読み上げは利用者視点の表現、AI音声は深層学習を使った世代を指すマーケティング用語、と整理できます。
Q2. 完全に無料で商用利用できるサービスはありますか?
あります。代表的なのはVOICEVOX(条件付き無償)など、配布者の利用規約に従えば商用利用可能なものです。ただしクレジット表記が必要だったり、特定用途が禁止されていたりするケースが多いため、必ず最新の利用規約を確認してください。
Q3. 自分の声をAIに学習させて使うことはできますか?
はい、ボイスクローン機能を備えたサービスなら可能です。SakuraSpeechもボイスクローンを提供しています。ただし他人の声を無断で学習させることは肖像権・パブリシティ権の侵害になるため、本人同意の取得が必須です。
Q4. 読み間違いが多くて困っています。改善方法は?
ほぼ全てのサービスがユーザー辞書を備えています。固有名詞・専門用語・社内用語を辞書登録することで、読み間違いを大幅に削減できます。辞書整備を運用フローに組み込むことを強く推奨します。
Q5. 業務に組み込むときの注意点は?
API安定性・SLA・障害時のフォールバック・コスト上限の4つを最初に確認してください。特に従量課金制では、想定外の利用増でコストが跳ね上がるリスクがあるため、アラート設定を必ず仕込んでください。
Q6. ナレーター・声優の仕事はAIに置き換わりますか?
定型ナレーションや量産工程は置き換えが進む一方で、ブランドの核となる表現・感情の機微・本人性を必要とする領域では、人の役割は残ります。AIは「人の代替」ではなく「人の補完」として設計するのが現実的です。
Q7. 日本語の品質が高いサービスを選ぶには?
日本語特化で開発された国産サービス、または日本語学習データを十分に確保しているグローバルサービスから選ぶのが安全です。デモ音声を「アクセントが特殊な単語」「同形異音語」「数字・英単語混在の文」で必ず試してください。
Q8. SakuraSpeechの強みは何ですか?
日本語特化のAI音声合成として、自然な日本語発話・16種類以上のキャラクターボイス・ピッチ/速度/感情パラメータ・ユーザー辞書・ボイスクローン・API連携を備えています。商用利用条件が日本語で明示されているため、企業導入時の社内稟議も通りやすい設計です。詳しくは SakuraSpeech公式サイト をご覧ください。
関連記事
- 音声読み上げ無料サービス8選|選び方と注意点【2026】
- 読み上げアプリ無料7選|iPhone・Android別比較【2026】
- かわいい声の読み上げサイト6選|キャラ別比較ガイド【2026】
- 英語読み上げ無料サイト6選|発音学習に使える厳選ツール【2026】
- AI読み上げ無料ツール7選|自然な声の選び方と活用術【2026】
- 無料で使える音声読み上げサービス比較|API対応まで【2026】
日本語特化のAI音声合成「SakuraSpeech」を試す →
執筆:SEO担当者(クリスタルメソッド株式会社)
AIアバター「瀧本クリスタル」開発者。対話AI・カスタムLLMの企業導入でフロントランナーとして活動。X / LinkedIn
編集責任者:SEO担当者(クリスタルメソッド株式会社) / 編集ポリシー
公開日:2026-05-22 / 最終更新:2026-05-22
監修
河合 継(クリスタルメソッド株式会社 代表取締役)
AI・ディープラーニングに関する特許16件の発明者。過去、国立がん研究センターとの共同研究や、テレビ番組でのAI解説実績を持つAI研究者として、AIの研究開発を主導している。
運営会社について | 編集方針
音声合成・音声AIの業務活用をご検討の方へ
クリスタルメソッドは、日本語特化のAI音声合成「SakuraSpeech」をはじめ、音声・音響AIの開発と業務導入を支援しています。ナレーションの自動化、自社サービスへの音声合成の組み込み、用途に合ったツール選定などのご相談を承っています。
- 無料相談・お問い合わせ:ご相談はこちら
Study about AI
AIについて学ぶ
-

教育 AI 活用 事例から学ぶ企業研修のDXとAnthropic無償提供が示すプロンプトの重要性
## 1. Anthropicによる教育者向けClaude無償提供ニュースの要点 2026年1月、AIスタートアップのAnthropicは、国際NGO「Teac...
-

AI人事評価のリスクと違法性の境界線とは?Meta社リストラ訴訟から学ぶ防衛策
近年、企業の意思決定プロセスにおいてAI(人工知能)の活用が急速に進んでいます。特に人事評価や採用、人員整理といった領域でのAI導入は、業務効率化や客観性の担保...
-

AIエージェントの相互運用性と規制がもたらす経営インパクト—米上院法案から紐解く日本企業の針路
自律的にタスクを遂行するAIエージェントの台頭に伴い、異なるシステムやプラットフォーム間でこれらを安全に連携させる「相互運用性」と、それを支える「規制」のあり方...