blog
AIブログ
claude 学習させない 設定|プラン別の正しい設定と見落としポイント

claude 学習させない 設定:プラン別の前提がまず逆になる
「ClaudeにコードやプロンプトをAI学習させない設定はどこにあるか」という問いに対する正確な答えは、利用プランによって前提がそもそも逆になる。競合記事の多くがこの点を曖昧にしたまま「オフにする方法」を説明しており、Team/Enterpriseプランの読者を無用に混乱させる。まずここを断言しておく。
- Free / Pro / Max(個人向け):設定をオンにした場合のみ学習対象になる。既定はオフ。ただし意図せずオンにしていないかの確認が必要。
- Team / Enterprise / API(商用):既定で学習されない。学習させないための追加設定は不要。問題は「うっかりオプトインしていないか」の確認。
以下の早見表を先に確認してほしい。
| プラン | 既定の学習利用 | 学習させない設定 | データ保持期間 |
|---|---|---|---|
| Free / Pro / Max | 設定オンで学習対象(既定はオフ) | claude.ai/settings/data-privacy-controls でトグルをオフのまま維持 | 設定オン=5年 / オフ=30日 |
| Team / Enterprise / API | 既定で学習されない | 追加設定不要。Development Partner Programに参加しないことのみ確認 | 標準30日。Enterprise ZDRは個別申請 |
| Amazon Bedrock / Google Vertex | 既定で学習されない | 追加設定不要。テレメトリ・フィードバックも既定オフ | 各クラウドプロバイダーのポリシーに依存 |
Anthropicの消費者向けプライバシーポリシー(2026年3月16日付)の原文は次の通りだ。「We will train new models using data from Free, Pro, and Max accounts when this setting is on (including when you use Claude Code from these accounts)」(出典:privacy.claude.com)。つまりClaude Codeを個人アカウントで使うケースも同じルールに従う。設定がオフであれば学習されない。
なお、個人プランにおける設定確認先は claude.ai/settings/data-privacy-controls で、「AIモデルの改善にご協力ください」と表示されているトグルがオフになっていれば、入力したコードや会話は学習に使われない。
商用プランで本当に確認すべき2点:学習のオプトイン項目
Team/Enterprise/APIで「学習させない設定」を探しても、claude.ai/consoleには学習オフのトグルが存在しない。これを見て「設定できないから学習されている」と誤解するエンジニアが多い。正しくは逆で、既定で学習対象外だからトグルを設ける必要がない。
商用プランで注意すべきは、自分から学習対象に入るオプトイン項目を誤って有効にしていないかどうかだ。具体的には以下の2点に絞られる。
確認点1:Development Partner Programに参加していないか
AnthropicのDevelopment Partner Programは、組織のClaude Codeセッションを自発的にAnthropicと共有し、モデルのトレーニングを含むサービス改善に協力するプログラムだ。参加は「参加する」ボタンを明示的に押す形式のため、誤って参加するケースは少ない。ただし一度共有したデータは退会後も削除できないため、参加の検討は慎重に行う必要がある。また、このプログラムはAnthropicの第一者APIでのみ利用可能で、BedrockやVertex経由では参加できない。
確認点2:フィードバック送信を有効にしていないか
「ユーザーフィードバックを許可」をオンにした状態でモデル応答へのフィードバックを送信すると、そのレポートにはプロンプト全文・応答・フィードバック内容が含まれ、モデル改善に使用される。この設定を見落としているケースが多い。機密コードを扱う環境では無効のまま運用する。
弊社(クリスタルメソッド)では商用アカウントでClaude Codeを運用し、実アカウントのプライバシー設定でこれら2点がオフ(学習オプトアウト済み)であることを設定画面で確認している。その実画面が次のとおりだ。
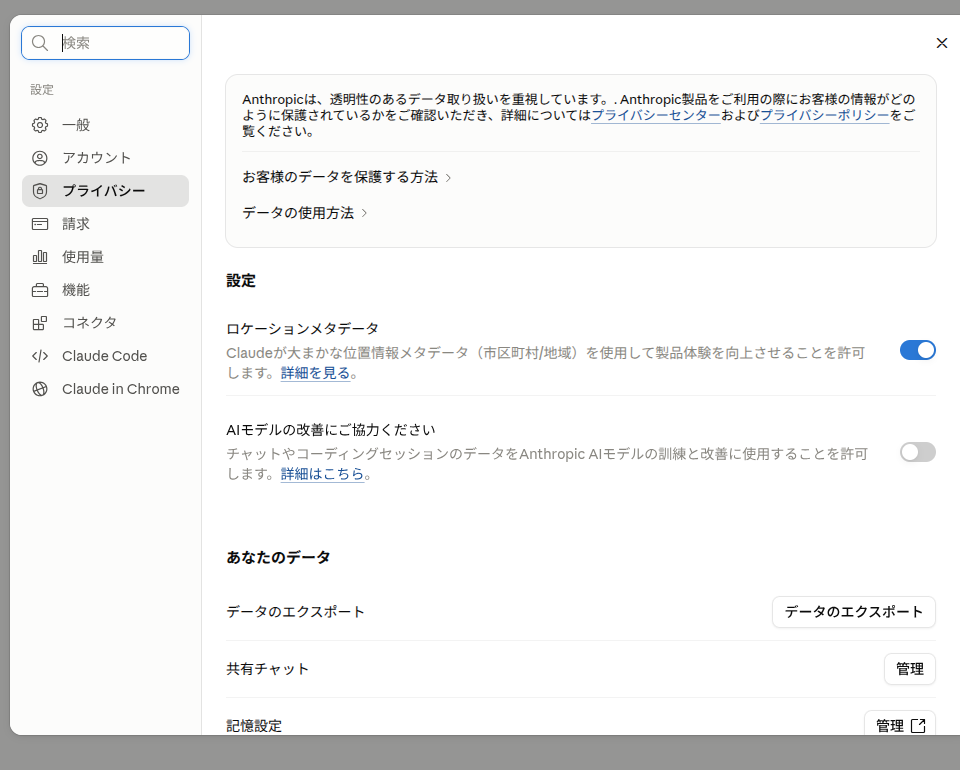
claude 学習させない 設定:個人プランの手順と設定先
Free/Pro/Maxの個人プランでClaude Codeを使う場合、設定の確認先は次の1か所だ。
- 設定URL:
claude.ai/settings/data-privacy-controls - 確認項目:「AIモデルの改善にご協力ください」というトグルがオフになっているか
このトグルをオフのまま維持していれば、入力したコードも会話も学習には使われない。設定をオンにした場合のデータ保持期間は5年、オフの場合は30日になる(出典:privacy.claude.com / code.claude.com「Data usage」、2026年3月16日付)。
なお、Claude Codeを個人アカウントで使う場合も同じポリシーが適用される。「Claude Codeはターミナルから動かすから別扱い」という認識は誤りで、個人アカウント経由で実行したClaude Codeセッションも上記トグルの対象に含まれることが公式ドキュメントに明記されている。
Claude Codeの導入方法や基本操作についてはClaude Codeのインストール手順とClaude Code入門ガイドも参照してほしい。
Claude Code・AIエージェントの業務導入をご検討の方は、自社での開発実例を公開しているクリスタルメソッドの無料相談をご利用ください。
学習以外に送信されるデータと、settings.jsonで制御できる環境変数
「学習させない設定」を完了しても、Claude Codeはいくつかの別経路でデータを送信する。これらは学習とは無関係だが、セキュリティポリシーが厳格な環境では停止を検討すべきだ。settings.jsonの環境変数として以下を設定することで、個別に制御できる。
| 送信される情報 | 停止する環境変数 | 補足 |
|---|---|---|
| テレメトリ(使用状況) | DISABLE_TELEMETRY=1 |
コードやパスは含まれない |
| エラー報告(Sentry) | DISABLE_ERROR_REPORTING=1 |
エラー発生時のスタックトレース等 |
/feedbackコマンド送信 |
DISABLE_FEEDBACK_COMMAND=1 |
会話+コードが含まれ5年保持 |
| セッション品質アンケート | CLAUDE_CODE_DISABLE_FEEDBACK_SURVEY=1 |
セッション後に表示されるアンケート |
| 非必須通信を一括停止 | CLAUDE_CODE_DISABLE_NONESSENTIAL_TRAFFIC |
上記をまとめて停止する場合に使用 |
これらは ~/.claude/settings.json(グローバル設定)または .claude/settings.json(プロジェクト単位)に記述する。設定例は以下の通りだ。
{
"env": {
"DISABLE_TELEMETRY": "1",
"DISABLE_ERROR_REPORTING": "1",
"DISABLE_FEEDBACK_COMMAND": "1",
"CLAUDE_CODE_DISABLE_FEEDBACK_SURVEY": "1"
}
}なお、Bedrock / Vertex / Foundry経由でClaude Codeを利用している場合は、テレメトリ・エラー報告・/feedbackコマンドがすべて既定でオフになる。この点でも商用クラウド経由の利用がデータ最小化の観点から有利だ。
/feedbackコマンドを含む各スラッシュコマンドの詳細についてはClaude Codeのスラッシュコマンド解説を参照してほしい。
ローカルデータの保持について
Claude Codeはセッション内容をローカルの ~/.claude/projects/ に平文で30日間保持する。この期間は cleanupPeriodDays パラメータで調整できる。ローカルストレージをより短期間にしたい場合は ~/.claude/settings.json に次のように設定する。
{
"cleanupPeriodDays": 7
}機密性の高いプロジェクトでは、ローカルの会話ログが平文で残ることへの配慮も必要だ。ディスク暗号化の有無やアクセス権限の設定も合わせて確認する。
Enterpriseプランのデータ保持制御:ZDRとDPAの位置づけ
学習に使われないことはTeam以上のプランで既定として担保される。それ以上の保護——「Anthropicのサーバーにデータが残らない」状態を求める場合はZero Data Retention(ZDR)が対応手段になる。
ただしZDRは標準のEnterpriseプランには同梱されておらず、個別申請が必要だ。申請すると、リクエスト・レスポンスのデータが処理後即座に削除され、安全性監視を目的とした標準30日保持も適用されなくなる。医療・金融・法務領域など、データがAnthropicのインフラに残ること自体がコンプライアンス上の問題になる場面での選択肢として検討する。
GDPRや個人情報保護法の文脈では、「学習されない」という事実とは別に、「第三者(Anthropic)のサーバーにデータが送信される」こと自体が規制対象になりうる。EU域内のユーザーデータを扱うプロダクトでは、AnthropicとのData Processing Agreement(DPA)の締結と適切な法的根拠の確認が別途必要になる。これはポリシーの確認・設定変更では解決できない法務課題であり、技術的な「学習させない設定」とは独立した対応として位置づける。
Claude Codeの料金プランや商用利用の詳細についてはClaude Code料金プランの解説とClaude Code APIの料金体系も参照してほしい。
よくある誤解:「設定」に関して現場で頻発する認識のズレ
「学習オフのトグルが無い=学習されている」は逆
商用アカウントのコンソールに学習オフのトグルが存在しないのは、既定で学習対象外だからだ。確認すべきは「オフのトグルの有無」ではなく、「オプトイン項目を自分から有効にしていないか」という点だ。
「ローカル実行だからデータが外に出ない」は誤り
Claude Codeはターミナルで動作するが、推論処理はAnthropicのAPI(api.anthropic.com)を経由する。コードやプロンプトはAPIリクエストとして送信されている。「ローカルで動いているからクラウドに出ていない」という認識はセキュリティ設計上の誤りにつながる。
「会話履歴を削除すれば学習データから消える」は誤り
claude.aiでの会話履歴削除はUIから見えなくなるだけで、サーバー側の保持期間とは別だ。学習利用を避けたい場合は削除ではなく、設定の確認とプランの選択が正規の手段になる。
「CLAUDE.mdに学習拒否の指示を書く」は効果がない
CLAUDE.mdに記述した内容はモデルへの振る舞い指示であり、Anthropicのデータ処理ポリシーを変更するものではない。プロンプト指示とポリシー設定は別のレイヤーで機能する。「CLAUDE.mdで学習を止める」という手段は存在しない。
「/feedbackコマンドは無害なバグ報告ツール」は危険な認識
/feedbackコマンドを実行すると、その時点の会話全文とコードがAnthropicに送信され、5年間保持される。機密コードを扱うセッションで誤って実行しないよう、前述の環境変数でコマンド自体を無効化しておくのが安全だ。
実運用で実際に踏んだ確認漏れ(一次情報)
当メディアの監修者・河合継はClaude Codeを3.5の時代から1年以上、商用の開発現場で日次運用してきた。ポリシーの読み解きだけでは見落としやすく、実際に運用して初めて気づいた「設定の抜け」を一次情報として補足する。
- アカウント種別をまたぐと設定は引き継がれない。個人のProアカウントで動作確認したものを、そのまま商用の感覚で本番運用に持ち込むと、学習・データ取り扱いの前提が別レイヤーになっている。「個人で一度オフにしたから大丈夫」という思い込みが最も危なく、アカウント種別ごとに毎回確認する運用に切り替えた。
- テレメトリ方針はチームで標準化しないとメンバーごとにバラつく。送信制御の環境変数や
settings.jsonを各自任せにすると、同じチームでもマシンによって挙動が変わる。配布する設定として一元管理し、新規メンバーのマシンにも同じ既定が効くようにして初めて、組織として一貫したデータ方針になった。 - オプトアウトは「一度設定して終わり」ではない。新規メンバーの追加やマシンの初期化のたびに既定へ戻り得るため、設定は一回きりのチェックではなく、人・端末が増えるたびに再点検する運用項目として扱うのが安全だった。
いずれもポリシー文書には明記されていないが、長期の商用運用を通じて繰り返し直面してきた実務上の落とし穴である。設定そのものよりも、「誰の・どのアカウントの・どの端末の設定か」を運用で押さえることが、学習回避を確実にする要点になる。
Claude Codeの全体像についての整理はClaude Codeとはを、他のAIコーディングツールとの違いはClaude CodeとCodexの比較を参照してほしい。
設定チェックリスト:プラン別に確認すべき項目
以下のチェックリストを設定完了の確認に使ってほしい。
Free / Pro / Max(個人プラン)
claude.ai/settings/data-privacy-controlsにアクセスする- 「AIモデルの改善にご協力ください」トグルがオフになっていることを確認する
- Claude Codeを個人アカウントで使っている場合も同じ設定が適用される
- フィードバック送信はこの設定とは独立した経路のため、
/feedbackコマンドの使用も避ける
Team / Enterprise / API(商用プラン)
- Development Partner Programに参加していないことを確認する(「参加する」ボタンを押していないか)
- 「ユーザーフィードバックを許可」がオフになっていることを確認する
- テレメトリ・エラー報告の送信を制限したい場合は
settings.jsonに環境変数を設定する /feedbackコマンドを封じる場合はDISABLE_FEEDBACK_COMMAND=1を設定する- ローカルの会話ログ保持期間を短縮したい場合は
cleanupPeriodDaysを調整する - ZDR(Zero Data Retention)が必要な場合は個別にAnthropicへ申請する
- GDPRや個人情報保護法が関係する場合はDPAの締結状況を法務と確認する
Anthropicのプライバシーポリシーおよびデータ利用規約は更新されることがある。四半期に一度は privacy.claude.com および code.claude.com のData usageセクションを確認し、変更がないかを確認する運用を設けることを推奨する。
Claude Codeの具体的な使い方についてはClaude Codeの使い方ガイドも参照してほしい。
利用できるモデルも進化を続けており、現在はClaude 5世代(最上位のFable 5、速度と知能のバランスに優れたSonnet 5)とOpus 4.8・Haiku 4.5が使えます。
参考文献
- Anthropic Privacy Policy(消費者向け・2026年3月16日付)
https://privacy.claude.com - Claude Code Data Usage(code.claude.com)
https://code.claude.com - Anthropic Compliance API – Organization Settings
https://platform.claude.com/docs/en/api/compliance/organizations/settings.md - Anthropic Self-hosted Sandboxes Security Model
https://platform.claude.com/docs/en/managed-agents/self-hosted-sandboxes-security.md - IPA テキスト生成AIの導入・運用ガイドライン
https://www.ipa.go.jp/jinzai/ics/core_human_resource/final_project/2024/f55m8k0000003spo-att/f55m8k0000003svn.pdf - デジタル庁 行政における生成AIの適切な利活用に向けた技術検証
https://www.digital.go.jp/assets/contents/node/information/field_ref_resources/19c125e9-35c5-48ba-a63f-f817bce95715/e03a8092/20240510_resources_ai_r5mainresults.pdf
監修
河合 継(クリスタルメソッド株式会社 代表取締役)
AI・ディープラーニングに関する特許16件の発明者。過去、国立がん研究センターとの共同研究や、テレビ番組でのAI解説実績を持つAI研究者として、AIの研究開発を主導している。
運営会社について | 編集方針
関連記事
Claude Code・AIエージェントの業務活用をご検討の方へ
クリスタルメソッドは、Claude Codeを実務投入している開発会社として、AIエージェント・社員AIの導入と開発効率化を支援しています。自社サイトの表示速度をAI社員(Claude Code)で12.89秒→2.03秒に短縮した実例も事例記事として公開しています。「自社の開発・業務にAIをどう組み込むか」といったご相談を承っています。
- 無料相談・お問い合わせ:ご相談はこちら
Study about AI
AIについて学ぶ
-

教育 AI 活用 事例から学ぶ企業研修のDXとAnthropic無償提供が示すプロンプトの重要性
## 1. Anthropicによる教育者向けClaude無償提供ニュースの要点 2026年1月、AIスタートアップのAnthropicは、国際NGO「Teac...
-

AI人事評価のリスクと違法性の境界線とは?Meta社リストラ訴訟から学ぶ防衛策
近年、企業の意思決定プロセスにおいてAI(人工知能)の活用が急速に進んでいます。特に人事評価や採用、人員整理といった領域でのAI導入は、業務効率化や客観性の担保...
-

AIエージェントの相互運用性と規制がもたらす経営インパクト—米上院法案から紐解く日本企業の針路
自律的にタスクを遂行するAIエージェントの台頭に伴い、異なるシステムやプラットフォーム間でこれらを安全に連携させる「相互運用性」と、それを支える「規制」のあり方...